DETRs with Collaborative Hybrid Assignments Training
In this paper, we provide the observation that too few queries assigned as positive samples in DETR with one-to-one set matching leads to sparse supervision on the encoder's output which considerably hurt the discriminative feature learning of the encoder and vice visa for attention learning in the decoder. To alleviate this, we present a novel collaborative hybrid assignments training scheme, namely \mathcalCo - \textDETR, to learn more efficient and effective DETR-based detectors from versatile label assignment manners. This new training scheme can easily enhance the encoder's learning ability in end-to-end detectors by training the multiple parallel auxiliary heads supervised by one-to-many label assignments such as ATSS and Faster RCNN. In addition, we conduct extra customized positive queries by extracting the positive coordinates from these auxiliary heads to improve the training efficiency of positive samples in the decoder. In inference, these auxiliary heads are discarded and thus our method introduces no additional parameters and computational cost to the original detector while requiring no hand-crafted non-maximum suppression (NMS). We conduct extensive experiments to evaluate the effectiveness of the proposed approach on DETR variants, including DAB-DETR, Deformable-DETR, and DINO-Deformable-DETR. The state-of-the-art DINO-Deformable-DETR with Swin-L can be improved from 58.5% to 59.5% AP on COCO val. Surprisingly, incorporated with ViT-L backbone, we achieve 66.0% AP on COCO test-dev and 67.9% AP on LVIS val, outperforming previous methods by clear margins with much fewer model sizes. Codes are available at https://github.com/Sense-X/Co-DETR.
Problem:: O2O Matching은 Encoder 출력에 Feature 품질 저하/O2O Matching은 Decoder의 Attention Learning을 저하
Solution:: O2M Matching(ATSS, Faster RCNN 등)을 사용하는 Aux Head로 Encoder 학습/Aux Head의 예측 Coordinate에서 생성한 Customized Query로 Decoder 학습 (여러 O2O를 이용한 O2M 근사)
Novelty:: Discriminability Score 도입으로 Encoder 및 Decoder 성능 저하 및 제안 방식의 효과 검증/비슷한 다른 연구(Group/H Detr)과 달리 O2M에서 사용되는 Head를 사용해 O2M의 장점을 더 잘 적용했다고 주장/많은 Aux Head는 오히려 성능에 악영향임을 보임
Note::
Summary
Motivation
- DETR 계열 모델은 One-to-One Set Matching을 사용하여 End-to-End 방식으로 객체 탐지를 수행하나, 각 Ground-Truth Box에 하나의 Query만 할당되는 방식으로 인해 Positive Sample이 부족한 문제 발생
- One-to-One Set Matching의 두 가지 주요 문제점 발견:
- Encoder Feature Learning 문제: Positive Sample이 적어 Encoder 출력에 Sparse Supervision이 발생하여 Discriminative Feature 학습 저하
- Decoder Attention Learning 문제: Positive Query 부족으로 Cross-Attention 학습 효율 저하
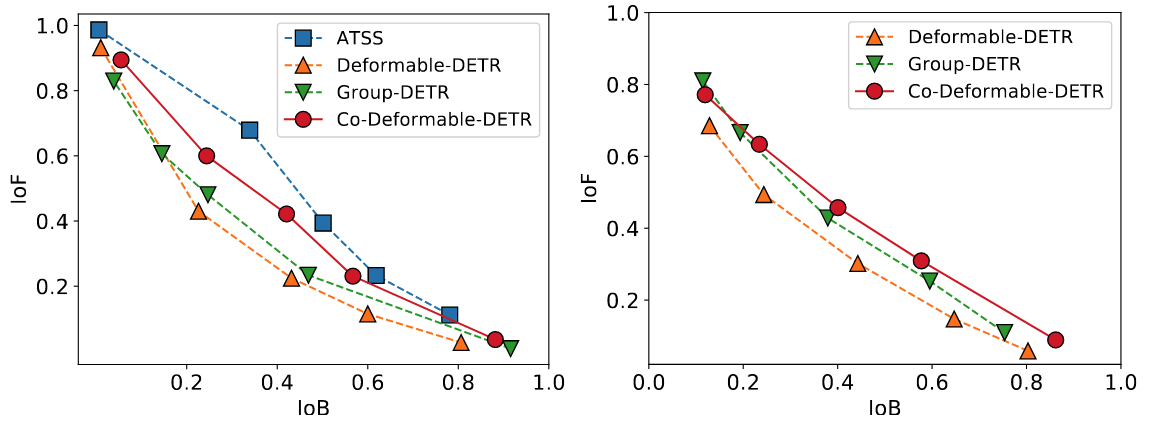
- 저자들은 Encoder 출력의 Discriminability Score를 분석하여 One-to-Many Label Assignment 방식(ATSS)이 Foreground와 Background를 더 잘 구분함을 확인
- IoF-IoB Curve 분석 결과, One-to-Many Label Assignment가 더 나은 Feature Discriminability 제공
- Visual 분석을 통해 One-to-Many 방식이 Foreground에서 더 높은 활성화를 보이는 반면, One-to-One 방식은 Background에서도 활성화되는 문제 확인

Method
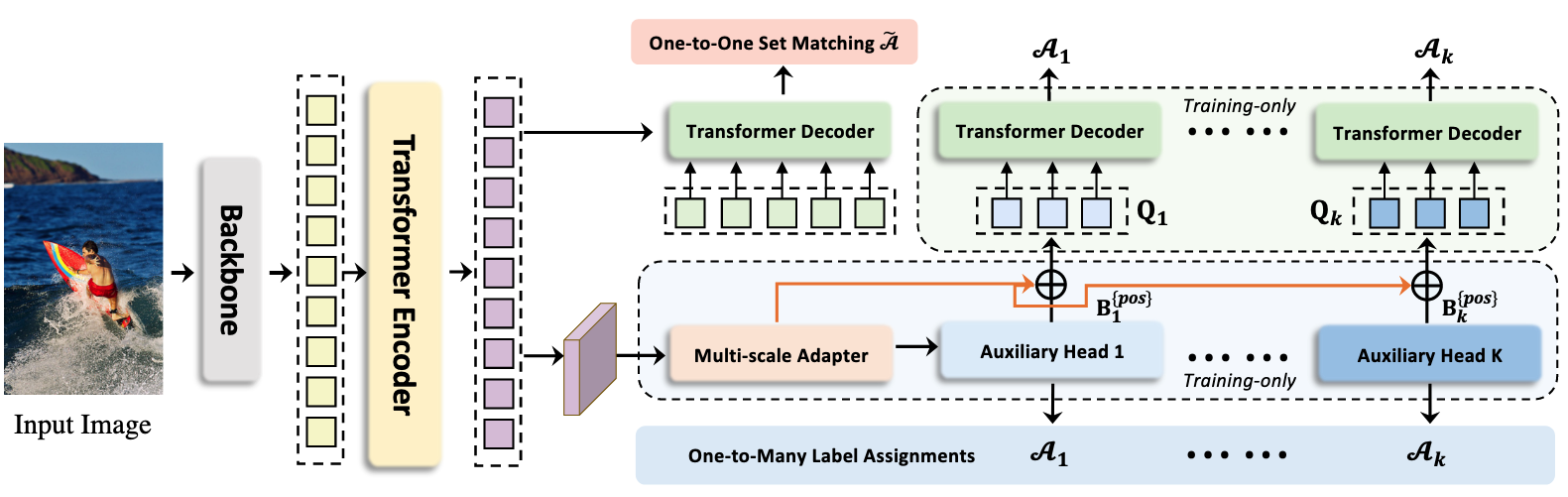
- 제안된 Co-DETR은 두 가지 주요 구성 요소로 이루어짐:
- Collaborative Hybrid Assignments Training: One-to-Many Label Assignment를 사용하는 Auxiliary Head를 통해 Encoder의 Feature Learning 강화
- Auxiliary Head는 기존 One-To-Many에서 사용된 Head들이므로 해당 Head들은 원래 연구에서 사용한 학습 방법으로 학습됨
- Customized Positive Queries Generation: Auxiliary Head에서 추출한 Positive Coordinate를 활용하여 Decoder의 학습 효율 향상
- Collaborative Hybrid Assignments Training: One-to-Many Label Assignment를 사용하는 Auxiliary Head를 통해 Encoder의 Feature Learning 강화
- 결론적으로, 학습은 Original Decoder 학습을 위한 Loss, Aux Head로 Encoder를 학습하는 Loss, 추가 Decoder Branch 학습을 위한 Loss로 구성됨
Collaborative Hybrid Assignments Training
- Auxiliary Head 구성:
- Encoder의 출력 Feature
에서 Feature Pyramid 를 생성 (Multi-Scale Adapter 사용) - 각 Auxiliary Head는 서로 다른 One-to-Many Label Assignment 방식(ATSS, Faster RCNN 등) 사용
- Label Assignment
는 Positive/Negative Sample 결정 및 Supervised Target 생성: - Assignment 방법과 Encoder 학습 Loss 모두 원 연구의 방식을 따름
- Encoder의 출력 Feature
Customized Positive Queries Generation
-
Auxiliary Head에서 추출한 Positive Coordinate를 활용하여 추가 Positive Query 생성
-
생성 방법:
: Positional Encoding (Transformer에서 일반적으로 사용되는 사인-코사인 인코딩) : Positive Coordinate Set (Auxiliary Head에서 판별된 객체 좌표, 형태: [x, y, w, h]) : Feature Extraction (좌표에 해당하는 특징 추출)
Method 검증
- Feature Discriminability 분석:
- Encoder 출력의 Discriminability Score IoF-IoB Curve 분석 → Co-DETR이 기존 Deformable-DETR보다 높은 Feature Discriminability 제공
- Visual 분석을 통해 Co-DETR이 Salient 영역에서 더 높은 활성화를 보이는 것 확인 → 객체 영역 특징 추출 능력 향상 입증
- L2-norm을 Discriminability Score로 사용한 동기:
- 딥러닝 네트워크는 객체가 있는 영역에서 특징 채널 전반에 걸쳐 강한 활성화 패턴을 생성하도록 학습됨
- L2-norm(
)은 각 공간 위치에서 특징 벡터의 크기를 측정하여 "해당 위치에 중요한 패턴 존재 여부"를 단일 스칼라 값으로 요약 - 객체 영역에서는 높은 L2-norm 값, 배경에서는 낮은 값이 나타나는 것이 이상적 → 모델의 객체/배경 구분 능력(Discriminability)을 평가하는 효과적인 지표
- 기본 성능 개선:
- Deformable-DETR: 12 epoch에서 +5.8% AP 향상 (37.1% → 42.9%) → 학습 수렴 속도 크게 개선
- Deformable-DETR: 36 epoch에서 +3.2% AP 향상 (43.3% → 46.5%) → 장기 학습에서도 성능 이점 유지
- DAB-DETR-C5: 36 epoch에서 +2.3% AP 향상 (41.2% → 43.5%) → 다양한 DETR 변형에 일관된 개선 효과
- SOTA 모델에 적용 결과:
- DINO-Deformable-DETR (Swin-L): +1.0% AP 향상 (58.5% → 59.5%) → 최신 모델에도 효과적
- ViT-L Backbone 적용 시: COCO test-dev에서 66.0% AP, LVIS val에서 67.9% AP 달성 → 대규모 모델과의 호환성 입증
- 모델 크기 효율성: 기존 3B 파라미터 모델보다 적은 304M 파라미터로 더 높은 성능 달성
- 구현 관련 Ablation Study:
- Auxiliary Head 종류별 분석: ATSS(+2.5% AP), Faster-RCNN(+2.0% AP), FCOS(+1.2% AP) → ATSS가 가장 효과적
- K 값(Auxiliary Head 수) 변화에 따른 결과: K=1(+1.6% AP), K=2(+2.4% AP), K=3(+2.4% AP) → K=2일 때 성능/효율성 최적화
- Auxiliary Head 구성 최적화:
- 여러 Head 간 최적화 충돌 문제 발생 가능성 → KL 발산으로 측정한 최적화 충돌 분석
- λ1, λ2 값 조정을 통한 손실 함수 균형 → {1.0, 2.0}일 때 최적 성능
- 계산 효율성 검증:
- 추론 시 Auxiliary Head 제거로 추가 계산 비용 없음 → 기본 모델과 동일한 추론 속도
- 학습 시 추가 메모리 사용량: Hybrid DETR(+69.6%), Group DETR(+39.3%)에 비해 Co-DETR은 매우 적은 +2.5% 증가
- Epoch당 학습 시간: Hybrid DETR(+36분), Group DETR(+28분)에 비해 Co-DETR(+2분)이 훨씬 효율적 → 실용적 구현 가능