Denoising Diffusion Bridge Models
Diffusion models are powerful generative models that map noise to data using stochastic processes. However, for many applications such as image editing, the model input comes from a distribution that is not random noise. As such, diffusion models must rely on cumbersome methods like guidance or projected sampling to incorporate this information in the generative process. In our work, we propose Denoising Diffusion Bridge Models (DDBMs), a natural alternative to this paradigm based on diffusion bridges, a family of processes that interpolate between two paired distributions given as endpoints. Our method learns the score of the diffusion bridge from data and maps from one endpoint distribution to the other by solving a (stochastic) differential equation based on the learned score. Our method naturally unifies several classes of generative models, such as score-based diffusion models and OT-Flow-Matching, allowing us to adapt existing design and architectural choices to our more general problem. Empirically, we apply DDBMs to challenging image datasets in both pixel and latent space. On standard image translation problems, DDBMs achieve significant improvement over baseline methods, and, when we reduce the problem to image generation by setting the source distribution to random noise, DDBMs achieve comparable FID scores to state-of-the-art methods despite being built for a more general task.
Problem:: 기존 확산 모델은 입력이 Random Noise로 고정되어 Image-to-Image Translation 같은 작업에 부적합함 / 기존 해결책들은 복잡하고 이론적으로 정립되지 않음
Solution:: 두 데이터 분포를 직접 잇는 Diffusion Bridge를 역방향으로 되돌리는 과정을 학습하는 DDBM(Denoising Diffusion Bridge Models) 프레임워크를 제안함 / 계산 가능한 Bridge의 Conditional Score를 매칭하는 Denoising Bridge Score Matching을 통해 모델을 학습시킴
Novelty:: 두 Endpoint의 통계량을 모두 고려하는 일반화된 파라미터화(Generalized Parameterization) 및 Scaling Function을 유도함 / 결정론적 ODE와 확률적 SDE 샘플링을 결합한 **하이브리드 샘플러(Hybrid Sampler)**를 제안하여 생성 품질을 향상시킴 / 기존 확산 모델과 Flow 기반 모델을 통합하는 일반적인 분포 변환 프레임워크를 제시함
Note:: Unconditional Generation은 Noise → Image니까 Image → Image 태스크를 위한 방법론을 제안해보자!
Summary
Motivation
- 기존의 Diffusion Model은 복잡한 데이터 분포를 Random Noise로 변환하는 과정(Data → Noise)을 학습
- 이러한 방식은 Image-to-Image Translation과 같이 입력이 Noise가 아닌 특정 분포를 갖는 경우에 적용하기 번거로움
- 기존 방법들은 Guidance나 Projected Sampling과 같은 복잡한 기법에 의존하며, 이론적으로 정립되지 않았고 Cycle Consistency를 보장하지 못함
- 본 논문에서는 두 개의 서로 다른 이미지 분포 사이의 변환을 직접 모델링하는 것을 목표로 함
- 이를 위해, 두 분포를 직접 잇는 Diffusion Bridge 개념에 기반한 **Denoising Diffusion Bridge Models (DDBMs)**를 제안
Method

- DDBM은 두 개의 Endpoint(
, )가 주어졌을 때, 이 둘을 잇는 Diffusion Process, 즉 Diffusion Bridge를 구축 - Forward Process는 Doob's h-transform을 이용해 한 분포(
)에서 출발한 샘플이 특정 Endpoint( )에 도달하도록 Drift를 조정함 - Forward SDE:
- Forward SDE:
- 위 그림과 같이, 이 Bridge Process를 역방향으로 되돌리는 과정을 학습하여 한 분포에서 다른 분포로의 변환을 수행
- 역방향 프로세스를 위한 Time-Reversed SDE와 Probability Flow ODE는 다음과 같음
- Time-Reversed SDE:
- Probability Flow ODE:
- Time-Reversed SDE:
- 역방향 프로세스를 위한 Time-Reversed SDE와 Probability Flow ODE는 다음과 같음
- 위 식의 Score Term
는 직접 계산할 수 없으므로 Neural Network로 근사해야 함 - 이를 위해 Denoising Bridge Score Matching이라는 새로운 학습 목표를 제안 (Theorem 2)
- 학습 목표:
- 이 목표 함수는 계산 가능한 Bridge의 Conditional Score인
와 모델의 예측값 의 차이를 최소화함으로써, 우리가 원하는 Score인 를 근사하도록 함 - 학습을 위해 두 Endpoint 사이의 중간 지점
는 다음과 같은 Gaussian 분포에서 샘플링됨
- 학습 목표:
- Generalized Parameterization & Sampling
- 기존 Diffusion Model(EDM)의 성공적인 설계 기법들을 DDBM에 적용하기 위해 모델 구조와 Scaling Function을 일반화함
- EDM은 Score 혹은 Noise 예측 대신 깨끗한
를 예측하는 모델
- EDM은 Score 혹은 Noise 예측 대신 깨끗한
- 두 Endpoint 분포의 분산(
, )과 공분산( )을 고려한 새로운 Scaling Function들( )을 유도하여 모델의 안정성과 성능을 향상시킴 - 결정론적인 ODE Sampler는 "평균적인" 경로를 따라가기 때문에 결과가 흐릿해질 수 있는 문제가 있음
- 이를 해결하기 위해 ODE Step과 확률적인 SDE Step (Euler-Maruyama)을 결합한 Denoising Diffusion Bridge Hybrid Sampler를 제안하여 샘플의 품질과 다양성을 높임 → 한 스텝의 간격을 두 개로 쪼개고 한번은 SDE, 다른 한번은 ODE로 샘플링
- 간격 조절용
s와 강도 조절용w가 존재
- 간격 조절용
- 기존 Diffusion Model(EDM)의 성공적인 설계 기법들을 DDBM에 적용하기 위해 모델 구조와 Scaling Function을 일반화함
Method 검증
- 실험 1: Image-to-Image Translation
- 실험 제목: Pixel-space Image-to-Image Translation 성능 평가
- 실험 진행 방법: Edges→Handbags (64x64), DIODE (Normal→RGB, 256x256) 데이터셋을 사용. 비교 모델로는 Pix2Pix, SDEdit, Rectified Flow, I²SB 등을 사용하고 FID, LPIPS, MSE 등으로 성능을 평가.

- 정량적 성능:
- Edges→Handbags: DDBM (VE) 모델이 FID 2.93, LPIPS 0.131로 SDEdit(3.58), I²SB(7.43) 대비 우수한 성능을 달성
- DIODE: DDBM (VP) 모델이 FID 4.43, IS 6.21로 I²SB(9.34), SDEdit(31.14) 대비 월등히 좋은 성능을 보임
- 통찰: DDBM은 생성 품질(FID)과 원본 충실도(LPIPS) 모두에서 기존 방법들보다 뛰어난 성능을 보이며, 특히 VP Bridge가 고차원 데이터에서 강점을 나타냄. 질적 비교에서도 다른 모델들보다 훨씬 선명하고 사실적인 이미지를 생성함.
- 정량적 성능:
- 실험 2: Ablation Studies
- 실험 제목: 제안된 Hybrid Sampler와 Preconditioning의 효과 분석
- 실험 진행 방법: Hybrid Sampler에서 SDE step의 비율(Euler step ratio
s)과 Guidance 강도(w)를 조절하며 FID 변화를 측정 (Figure 4). 또한, 제안된 Preconditioning과 Sampler의 기여도를 확인하기 위해 각 요소를 제거했을 때의 성능을 비교 (Table 3).- 정량적 성능:
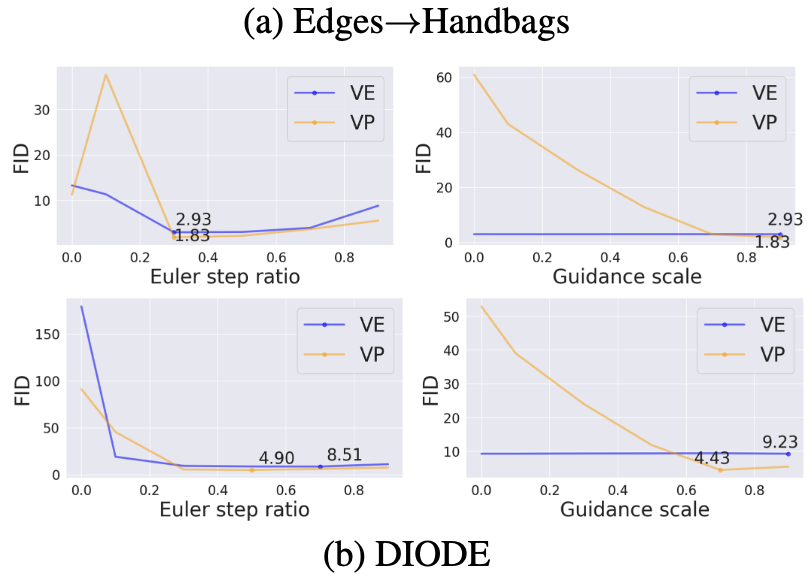
- Hybrid Sampler (
s):s=0(순수 ODE)일 때보다s=0.3근처에서 FID가 크게 하락 (Edges→Handbags에서 10 이상에서 2.93으로 감소) - 전체 구성 요소: Preconditioning과 Sampler를 모두 적용했을 때 FID가 크게 향상 (DIODE 데이터셋에서 126.3 → 8.51)
- Hybrid Sampler (
- 통찰: Hybrid Sampler를 통해 약간의 Noise를 주입하는 것(
s > 0)이 흐릿한 결과를 방지하고 성능을 극대화하는 데 결정적임. 또한, 본 논문에서 제안한 Preconditioning과 Sampler가 DDBM의 높은 성능에 필수적인 요소임을 확인함.
- 정량적 성능:
- 실험 3: Unconditional Generation
- 실험 제목: Unconditional Generation으로의 일반화 성능 검증
- 실험 진행 방법: Bridge의 한쪽 Endpoint를 Gaussian Noise로 설정하여 DDBM이 표준 Diffusion Model처럼 작동하는지 CIFAR-10과 FFHQ-64x64 데이터셋에서 검증. SOTA 모델인 EDM과 성능을 비교.

- 정량적 성능:
- CIFAR-10: DDBM의 FID는 2.06으로 EDM(2.04)과 거의 동일
- FFHQ-64x64: DDBM의 FID는 2.44로 EDM(2.53)보다 소폭 우수
- 통찰: DDBM은 더 일반적인 Image Translation 작업을 위해 설계되었음에도 불구하고, Unconditional Generation에서도 SOTA 모델과 대등하거나 더 나은 성능을 달성함. 이는 DDBM이 기존 Diffusion Model의 핵심 설계 요소들을 성공적으로 일반화하고 포괄하는 강력한 프레임워크임을 증명함.
- 정량적 성능: