Less is More: Focus Attention for Efficient DETR
DETR-like models have significantly boosted the performance of detectors and even outperformed classical convolutional models. However, all tokens are treated equally without discrimination brings a redundant computational burden in the traditional encoder structure. The recent sparsification strategies exploit a subset of informative tokens to reduce attention complexity maintaining performance through the sparse encoder. But these methods tend to rely on unreliable model statistics. Moreover, simply reducing the token population hinders the detection performance to a large extent, limiting the application of these sparse models. We propose Focus-DETR, which focuses attention on more informative tokens for a better trade-off between computation efficiency and model accuracy. Specifically, we reconstruct the encoder with dual attention, which includes a token scoring mechanism that considers both localization and category semantic information of the objects from multiscale feature maps. We efficiently abandon the background queries and enhance the semantic interaction of the finegrained object queries based on the scores. Compared with the state-of-the-art sparse DETR-like detectors under the same setting, our Focus-DETR gets comparable complexity while achieving 50.4AP (+2.2) on COCO. The code is available at torch-version† and mindspore-version‡.
Problem:: DETR은 모든 토큰을 사용한 Encoder의 연산량이 너무 높음/기존의 토큰 선별 방법은 부정확함/Deformable Attention은 장거리 정보 결합에 한계가 있음
Solution:: 정확한 Foreground 토큰 선별(Top-down Score Modulation)/세부 범주 기반 추가 토큰 정제(Multi-category Score Predictor)/장거리 정보 결합 강화(Dual Attention)
Novelty:: Encoder의 Layer별로 토큰을 선택하여 연산량 감소/Encoder에서 Background도 이용한 Cross-Attention 방식 도입
Note:: Sparse DETR을 먼저 읽었어야 했을 듯
Summary
Motivation
- 기존의 DETR 기반 모델들은 모든 토큰을 동등하게 처리하여 불필요한 계산 비용이 발생하는 문제가 존재
- 최근 연구 (Sparse DETR 등)는 중요한 토큰만 선택하여 계산 효율성을 높였으나, 내부 모델 통계(Decoder의 Cross-Attention Map, DAM 등)에 의존한 토큰 선택 방식이 부정확하여 성능 저하가 발생
- Deformable Attention은 Local 정보 처리에 특화되어 있어, 멀리 떨어진 토큰 간의 의미론적 정보 결합에 한계가 있음
Method
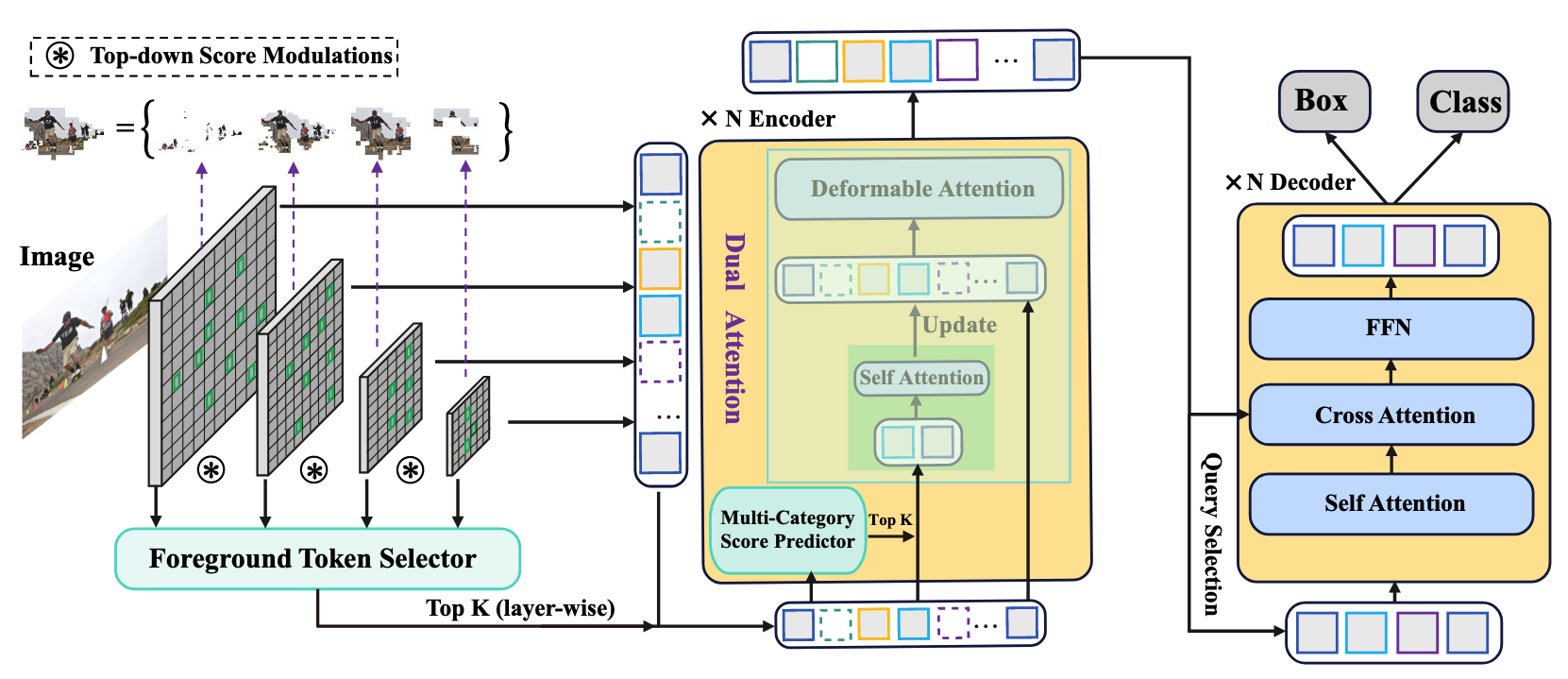
- Multi Scale Feature에 대해 Top-down Score Modulation으로 모든 Level의 Feature에 대해 Foreground Score 추정
- Backbone에서 나온 서로 다른 스케일의 다중 특징맵(Multi-scale features)을 이용
- 고해상도에서 저해상도 특징맵 순서로 하향식(top-down) 으로 점수를 전달하여, 높은 semantic 정보를 가진 고수준(high-level)의 특징맵을 이용해 저수준(low-level)의 특징맵에 존재하는 토큰의 Foreground 가능성 점수를 보완해줌
- 이를 통해 전체 스케일(Level)의 특징맵에서 보다 정확한 Foreground Score를 추정 가능
- Foreground Score를 이용해 각 레이어마다 특정 개수의 Foreground Token 추출
- 추정된 Foreground Score 기반으로 각 레이어(layer)의 특징맵에서 일정 비율의 토큰을 Foreground로 판단하고 추출
- 논문에서의 실제 비율은 각 레이어별로 미리 정해졌으며, 다음과 같음:
- 레이어별 유지 토큰 비율:
- 예시로 가장 높은 레이어(첫 번째 레이어)는 전체 토큰의 절반(50%), 가장 낮은 레이어(마지막 레이어)는 전체 토큰의 10%(0.2×0.5=0.1)만 유지하여 Foreground 토큰을 점차 줄이는 방식을 사용함
- 레이어별 유지 토큰 비율:
- 이 과정을 통해 각 레이어에서 더 효율적인 연산 수행
- Multi-Category Score Predictor를 이용해 Foreground Token에 대한 Category Probability 추정
- 앞서 선정된 Foreground Token을 대상으로, 추가적인 분류(Category) 점수를 예측하여 더욱 정밀한 Fine-grained Token 선별을 수행
- Category Score Predictor는 각 토큰이 특정 객체 범주(Category)에 해당될 확률을 추정하여 보다 의미 있는 토큰 선별을 도와줌
- Foreground Score와 Category Probability로 Encoder의 Dual Attention의 Self-Attention을 수행할 Fine-grained Token 추출
- 앞서 얻은 두 가지 점수를 결합하여 최종적인 토큰 중요도(
) 계산: : Foreground Score : Category Probability
- 위의 중요도 점수(
)로 전체 Foreground Token 중에서 상위 토큰 (논문에서는 기본적으로 300개)을 선택하고, 이를 "Fine-grained Token"이라 부름 - 이 토큰들이 추가적인 의미론적 연산을 수행하기 위해 Dual Attention의 Self-Attention 과정에서 사용됨
- 앞서 얻은 두 가지 점수를 결합하여 최종적인 토큰 중요도(
- Encoding 과정이 끝난 모든 토큰들 중 Top 900개를 Decoder의 Query로 이용
- Encoder의 Dual Attention 과정을 통해 계산된 모든 토큰 중, 최종적으로 importance 점수가 높은 상위 900개를 선택하여 Decoder의 Query로 전달
- 이를 통해 불필요한 많은 배경 정보를 배제하고 중요한 정보만으로 효율적인 Decoder 계산이 가능
Foreground Token Selector
- 역할: Backbone에서 추출된 전체 토큰 중에서 실제 객체(foreground)에 해당하는 토큰만 선별하는 모듈
- 학습 방법:
- 학습 시 Ground Truth(GT) Bounding Box 정보를 기반으로 각 토큰이 객체 영역인지 아닌지 Supervised 방식으로 학습함
- 이를 통해 각 토큰이 객체의 위치 및 크기와 얼마나 잘 일치하는지를 평가하는 방법을 학습하고, 추론 시에는 GT 없이도 Foreground 여부를 스스로 판단 가능하게 함
- 라벨 할당(Label Assignment) 방식:
- 라벨 할당이란, 학습 과정에서 각 토큰에게 foreground(1) 또는 background(0)라는 정답을 부여하는 과정을 의미함
- 본 논문에서는 라벨 할당을 다음과 같은 방식으로 진행함: 정답 BBox가 특정 크기에 속할 때 해당 BBox에 속한 쿼리는 전경
: Ground Truth bounding box 집합이며, 각 box는 형식임 : 토큰 의 위치와 bounding box 중심 사이의 **최대 체커보드 거리(checkerboard distance)**로 정의됨:
- 토큰이 Foreground로 판단되는 기준으로 객체의 크기 범위를 레벨별로 다르게 설정하고, 이를
로 나타냄: : 각 스케일에서 판단할 객체 크기의 하한 : 각 스케일에서 판단할 객체 크기의 상한 - 서로 인접한 스케일 레벨의 크기 범위를 50%씩 겹치도록 설정:
,
Top-down Score Modulation
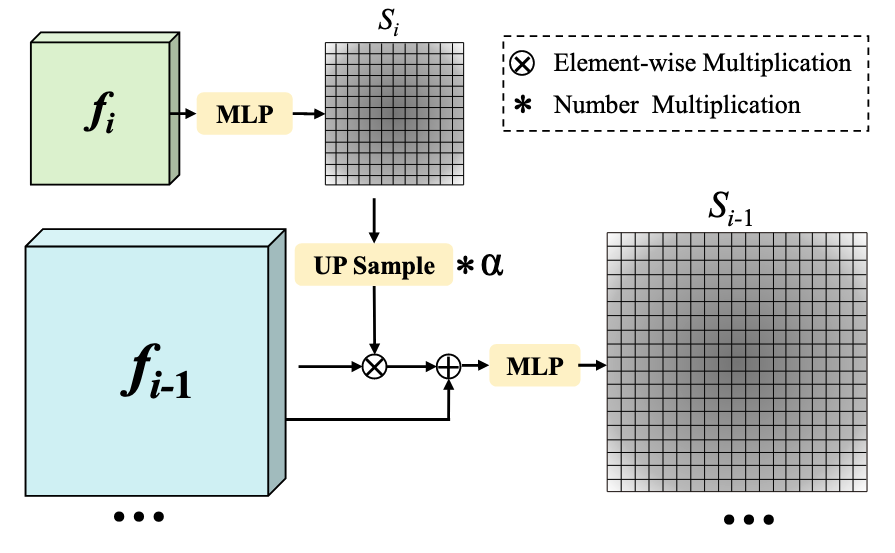
- 역할: 서로 다른 해상도에서 추출된 Multi-scale 특징맵이 가진 Semantic 정보를 효과적으로 결합하여 Foreground Token Selector가 보다 정확한 Foreground 점수를 계산할 수 있도록 보완해주는 전략적 모듈
- 세부 동작 원리:
- 일반적으로 고수준(high-level)의 특징맵은 낮은 해상도이지만 풍부한 semantic 정보를 담고 있고, 저수준(low-level)의 특징맵은 높은 해상도이지만 semantic 정보가 부족한 대신 위치 정보가 정확함
- 본 논문에서는 높은 Semantic 정보를 가진 고수준 특징맵의 Foreground 점수를 Upsampling하여, 저수준 특징맵의 Foreground 점수에 반영함
Multi-Category Score Predictor
- 역할: 이미 선택된 Foreground 토큰을 대상으로 추가로 객체의 범주(Category) 정보를 예측하여, 더 정밀하게 중요한 토큰(Fine-grained token)을 추출하는 모듈
- 동작 원리:
- 이전 단계(Foreground Token Selector)에서 걸러낸 Foreground 토큰은 객체인지 아닌지 여부만으로 선택되었기 때문에, 여전히 객체의 의미적인 세부 정보(category)가 부족함
- Multi-Category Score Predictor는 각 토큰에 대해 실제로 어떤 객체 카테고리에 속할 확률이 높은지(category probability) 를 추가로 예측함
- 효과:
- 범주(category) 정보를 추가로 이용하면 객체의 세부적이고 의미론적인 중요성을 평가할 수 있으며, 이를 통해 불필요하거나 중요도가 낮은 토큰을 효과적으로 제거하여 계산량을 줄이고, 중요한 토큰에 집중할 수 있도록 만들어 줌
Dual Attention
- 역할: 기존의 Deformable Attention 방식이 갖는 한계인 장거리 토큰 간의 정보 결합 제한 으로 인해 생기는 semantic 약점을 해결하기 위해 제안된 Encoder 구조
- 기존 Deformable Attention의 한계:
- Deformable Attention은 효율성을 위해 모든 토큰을 Global하게 보지 않고 Local한 일부 영역에서만 정보를 가져옴
- 이로 인해 서로 멀리 떨어진 토큰들 간의 Semantic 정보가 잘 결합되지 못하는 Semantic Weakness 문제가 발생함
- Dual Attention의 구조와 작동 원리:
- 위에서 추출한 "Fine-grained Token"을 대상으로 추가적인 Self-Attention 연산을 먼저 수행하여, 서로 떨어진 중요한 객체 토큰 간 semantic 정보를 정밀하게 결합시킴
- 이때 얻어진 풍부한 Semantic 정보를 다시 원래의 전체 Foreground Token 집합에 반영하여 업데이트(Update)함
Method 검증
- 데이터셋 및 평가기준:
- 표준적인 COCO 2017 Object Detection 데이터셋을 사용하여 평가 수행
- 성능 평가는 COCO AP(Average Precision) 를 주요 지표로 사용함
- 추가로 계산 복잡도 (GFLOPs) 및 **추론 속도(FPS)**를 이용하여 효율성을 평가함
- 비교 대상 모델:
- 기존 Transformer 기반 객체 검출 모델인 DETR, Deformable DETR, Sparse DETR, DINO 등 다양한 최신 DETR 기반 모델과 성능 및 복잡도를 비교 분석함
- 성능 검증 결과:
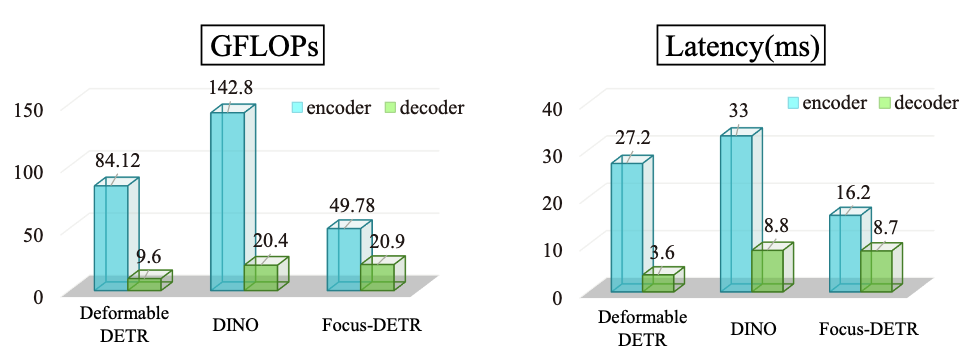
- 동일한 계산 복잡도(GFLOPs)에서 기존 Sparse DETR과 비교했을 때 +2.2 AP 만큼 성능이 향상됨을 보였음 (최고 성능은 50.4 AP 달성)
- Sparse DETR이 Learnable query 설정 환경에서 성능 저하를 보인 반면, 제안된 Focus-DETR은 이러한 조건에서도 안정적인 성능을 유지하고 향상함을 보임
- 효율성 검증 결과:
- 제안한 토큰 선별 방식과 Dual Attention 구조가 추가적인 연산을 필요로 하지만, 실제 추가되는 계산 비용은 전체 Transformer 계산량 대비 매우 낮음 (약 2.5% 이하)
- 기존 모델 대비 전체 계산 비용이 크게 감소하면서도 비슷하거나 더 높은 성능을 유지할 수 있었음
- 예: DINO와 비교했을 때, 계산 비용(GFLOPs)을 약 45% 감소시키고 추론 속도를 약 40.8% 향상시킴과 동시에 성능(AP)은 거의 동일하게 유지하는 결과를 보임
- 모듈별 효과 검증 (Ablation Study):
- 논문의 Ablation Study에서 Foreground Token Selector의 유지 비율(
)을 변화시키며 실험 수행: 값을 0.1에서 0.5 사이로 조정해 Foreground 토큰 유지 비율에 따른 성능 및 계산량 변화를 평가하여 최적의 값(0.3)을 찾아냄
- 추가적으로 Dual Attention을 제거하고 실험하였을 때 성능이 감소하는 것을 확인하여 Dual Attention의 중요성을 입증함
- 논문의 Ablation Study에서 Foreground Token Selector의 유지 비율(
- 장거리 정보 결합 개선 효과:
- 기존 Deformable Attention 구조가 장거리 토큰 간의 정보 결합이 부족한 문제를 가지고 있음을 지적하고, Dual Attention을 통해 이러한 Semantic 약점이 성공적으로 개선됨을 실험적으로 증명함
- 추가적인 Fine-grained Token 간의 Attention을 통해 Foreground Token의 semantic 정보를 더욱 강화할 수 있었음을 확인함