MS-DETR: Efficient DETR Training with Mixed Supervision
DETR accomplishes end-to-end object detection through iteratively generating multiple object candidates based on image features and promoting one candidate for each ground-truth object. The traditional training procedure using one-to-one supervision in the original DETR lacks direct supervision for the object detection candidates. We aim at improving the DETR training efficiency by explicitly supervising the candidate generation procedure through mixing one-to-one supervision and one-to-many supervision. Our approach, namely MS-DETR, is simple, and places one-to-many supervision to the object queries of the primary decoder that is used for inference. In comparison to existing DETR variants with one-to-many supervision, such as Group DETR and Hybrid DETR, our approach does not need additional decoder branches or object queries; the object queries of the primary decoder in our approach directly benefit from one-to-many supervision and thus are superior in object candidate prediction. Experimental results show that our approach outperforms related DETR variants, such as DN-DETR, Hybrid DETR, and Group DETR, and the combination with related DETR variants further improves the performance. Code is available at: https://github.com/Atten4Vis/MS-DETR.
Problem:: DETR의 Candidate 생성 단계에 명시적 Supervision 부족으로 품질 저하 발생
Solution:: 기존의 One-to-One Supervision에 추가적으로 One-to-Many Supervision을 결합한 Mixed Supervision 제안
Novelty:: 기존 연구와 달리 추가적인 Decoder Branch나 Query 없이 Candidate의 품질 향상
Note::
Summary
Motivation
- DETR는 End-to-End 방식으로 Object Detection 수행
- 기존 DETR 구조는 후보 생성 단계에서 명시적인 Supervision 부재로 인해 Candidate 품질이 저하되는 문제 발생
- 특히 기존 DETR의 Candidate 생성은 Cross-Attention에 의해 이루어지고, 중복된 후보 제거는 Self-Attention과 One-to-One Supervision에 의해 수행되나, Candidate를 명시적으로 관리하지 않아 품질 저하 초래

1행: GT, 2행: DETR, 3행: 제안 방식 → 2행을 보면 앞서 언급한 문제로 후보 생성이 제대로 이루어지지 않음
Method

(a) DETR, (b) MS-DETR, (c) Group DETR/DN-DETR, (d) Hybrid DETR
제안 방식은 Weight Shared Decoder와 추가 Query들을 요구하지 않음 → 실용적
-
One-to-One Supervision과 추가적인 One-to-Many Supervision을 결합한 Mixed Supervision (MS-DETR)을 제안
-
추가적인 One-to-Many Supervision을 DETR의 Primary Decoder 내의 Object Query에 직접 적용하여 Candidate 품질 개선
-
One-to-Many Supervision을 위한 Matching Score 정의
: Prediction : GT
-
Matching Score가 높은 상위
개의 후보를 지도 대상으로 선정하며, Threshold 이하의 후보는 제외함으로써 높은 품질의 후보들만을 관리
Method 검증
- 다양한 DETR 기반 모델과 수치적 성능 비교 수행 (COCO Dataset 사용)
- 다른 One-to-Many Supervision 기반 방법(Group DETR, Hybrid DETR, DN-DETR 등)과 직접 비교 및 성능 우위 입증
- 기존 One-to-Many 방법들과의 결합을 통한 성능 추가 향상 확인
- Computation 및 Memory 효율성 실험으로 효율적임을 입증
- Hybrid DETR 및 Group DETR는 추가적인 Decoder와 Query 사용으로 Memory 사용량이 Baseline 대비 각각 +69.6%(8680M), +39.3%(7128M) 증가한 반면, MS-DETR은 오직 +2.5%(5243M) 증가로 최소화됨
- Epoch당 Training Time은 Hybrid DETR(+36분), Group DETR(+28분) 대비 MS-DETR(+2분)이 월등히 효율적임
- 수렴 속도(Convergence) 측면에서 우위 입증
- 장기간 훈련(50 epochs)에서도 Baseline 모델보다 빠른 수렴 속도를 보이며, 최종 mAP를 46.9 → 49.0으로 개선
- Instance Segmentation Task 적용을 통한 추가 검증
- Mask-Deformable-DETR 모델을 기반으로 Instance Segmentation 성능 실험 수행 시 12 Epoch 기준 Mask mAP가
로 증가, 50 Epoch에서도 로 꾸준히 성능 향상됨
- Mask-Deformable-DETR 모델을 기반으로 Instance Segmentation 성능 실험 수행 시 12 Epoch 기준 Mask mAP가
흥미로운 점
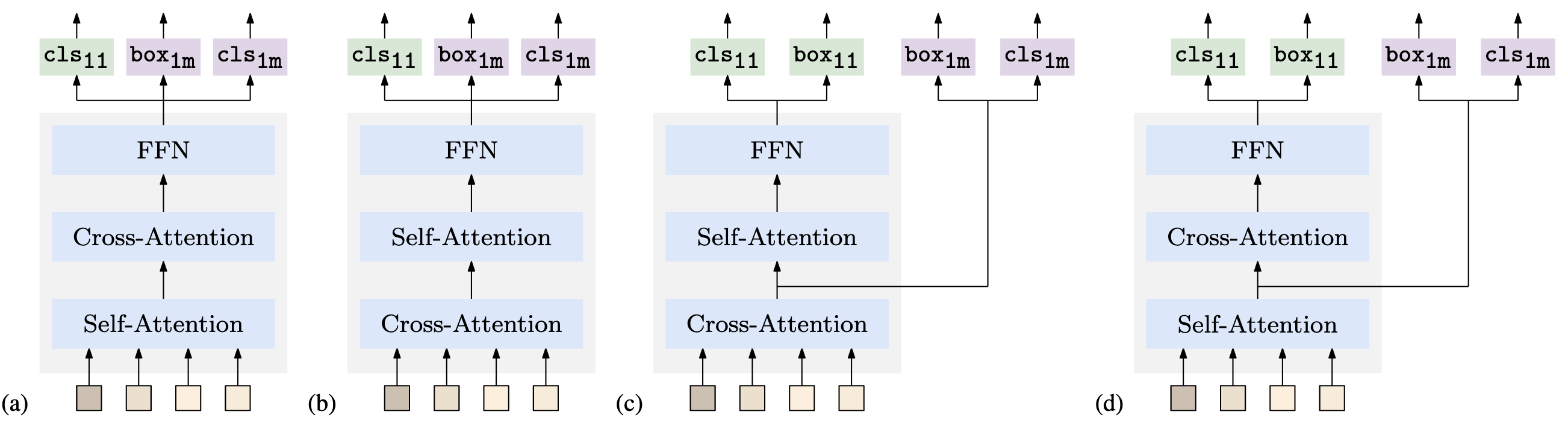
(c) > (d) > (b) > (a)
(a), (b)의 경우은 에 통합됨 → 이유는 밝히지 않음
- Cross-Attention이 후보군 생성에 관여하므로, One-to-Many Matching을 Cross-Attention 직전에 주입한 (c)가 가장 성능이 좋음
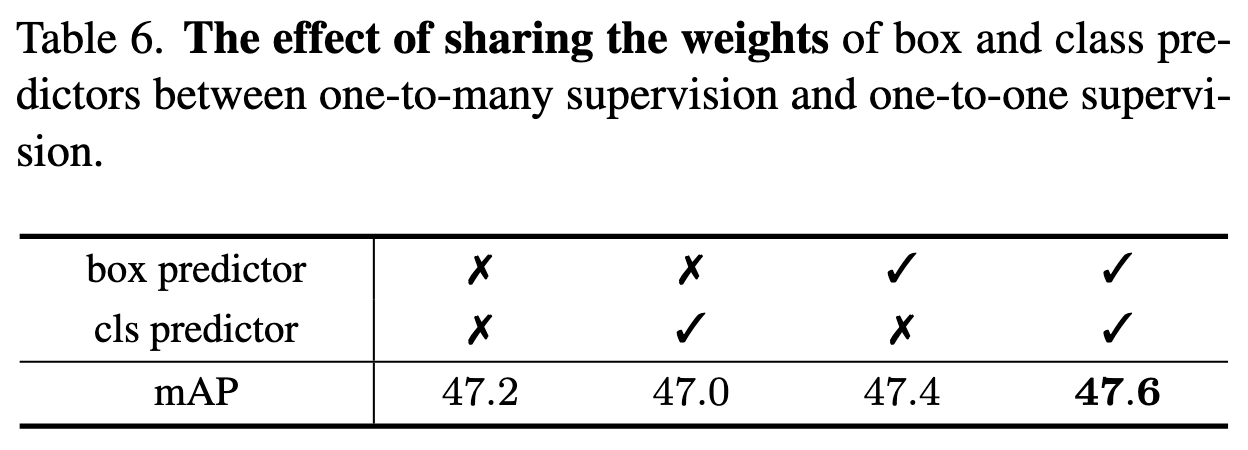
- Box Predictor: 완벽히 동일한 목적 → 공유하면 성능 향상
- Class Predictor: 일부 목적 공유, 일부는 다름 → 공유하면 추가 supervision 효과가 있고 중복 후보 제거용 weight는 성능에 영향을 안 미침 → 공유하는 것이 성능상 유리함을 실험적으로 확인
- Class Predictor의 경우, One-to-One과 One-to-Many의 목적에 공통된 부분이 일부 있지만, 중복된 후보(duplicate candidates)를 제거하고 하나의 후보만 선택하는 과정은 One-to-One supervision에서만 사용되는 고유한 목적
- Class Predictor에서 Weight를 공유할 때 다음과 같은 두 가지 효과를 기대할 수 있음
- 공통 부분에 대해서는 Supervision이 더 풍부해짐 (성능 향상 효과)
- 중복 후보 제거 등 One-to-One Supervision에만 사용되는 Weight는 공유해도 One-to-Many Supervision의 성능에 악영향을 미치지 않음 (사용되지 않으므로)
- 반면, Box Predictor의 경우처럼 전적으로 완벽하게 같은 목적을 수행