AdvAnchor: Enhancing Diffusion Model Unlearning with Adversarial Anchors
Security concerns surrounding text-to-image diffusion models have driven researchers to unlearn inappropriate concepts through fine-tuning. Recent fine-tuning methods typically align the prediction distributions of unsafe prompts with those of predefined text anchors. However, these techniques exhibit a considerable performance trade-off between eliminating undesirable concepts and preserving other concepts. In this paper, we systematically analyze the impact of diverse text anchors on unlearning performance. Guided by this analysis, we propose AdvAnchor, a novel approach that generates adversarial anchors to alleviate the trade-off issue. These adversarial anchors are crafted to closely resemble the embeddings of undesirable concepts to maintain overall model performance, while selectively excluding defining attributes of these concepts for effective erasure. Extensive experiments demonstrate that AdvAnchor outperforms state-of-the-art methods. Our code is publicly available at https://anonymous.4open.science/r/AdvAnchor.
Problem:: 기존 Diffusion Model Unlearning 기법들의 성능 Trade-off 문제 / 사전 정의된 Text Anchor 기반 방법들의 한계
Solution:: 원치 않는 Concept의 Embedding에 최적화된 Universal Adversarial Perturbation
Novelty:: Diffusion Model Unlearning에서 Text Anchor의 영향을 체계적으로 분석 및 통찰 도출 / Unlearning 성능 향상을 위한 Adversarial Anchor 개념 최초 제안
Note:: Concept과 가장 유사한 Anchor를 이용한 Unlearning은 보존 능력이 높다는 당연한 관찰을 AdvAnchor의 사용으로 연결 짓는 과정이 재밌음
Summary
Motivation
- Text-guided DM은 고품질 이미지 생성 능력으로 주목받고 있으나, 유해 콘텐츠 생성 및 저작권 침해와 같은 보안 문제가 존재함
- DM에서 안전하지 않은 행동을 재학습 없이 제거하기 위해 Machine Unlearning (MU) 기법, 특히 Fine-tuning 방식이 연구되고 있음
- 기존 Fine-tuning 방식들은 주로 안전하지 않은 Prompt의 예측 분포를 사전 정의된 Text Anchor의 분포와 일치시키는 방식을 사용함 (e.g., AbConcept)
- 하지만 이러한 방식들은 원치 않는 Concept 제거 성능과 모델의 전반적인 생성 품질 (다른 Concept 보존) 간에 상당한 Trade-off를 보임 (e.g., 'Cezanne' 스타일 제거 시 'Van Gogh', 'Picasso' 스타일 생성 능력 저하)
- Anchor 선택이 DM Unlearning에 미치는 영향과 더 나은 Anchor 설계를 통해 성능을 향상시킬 수 있는지에 대한 의문 제기
Impact of Various Anchors on DM Unlearning Analysis
분석 방법: 원치 않는 Concept
- 여기서
는 Unlearning을 위해 최적화 가능한 모델 가중치, 는 Denoiser, 는 Timestamp t에서의 Latent Representation, 와 는 각각 와 의 Text Embedding, 는 원본 모델의 고정된 가중치를 의미함 - 관찰 1 (o1):
와 사이의 유사성이 높을수록 보존 성능이 향상됨
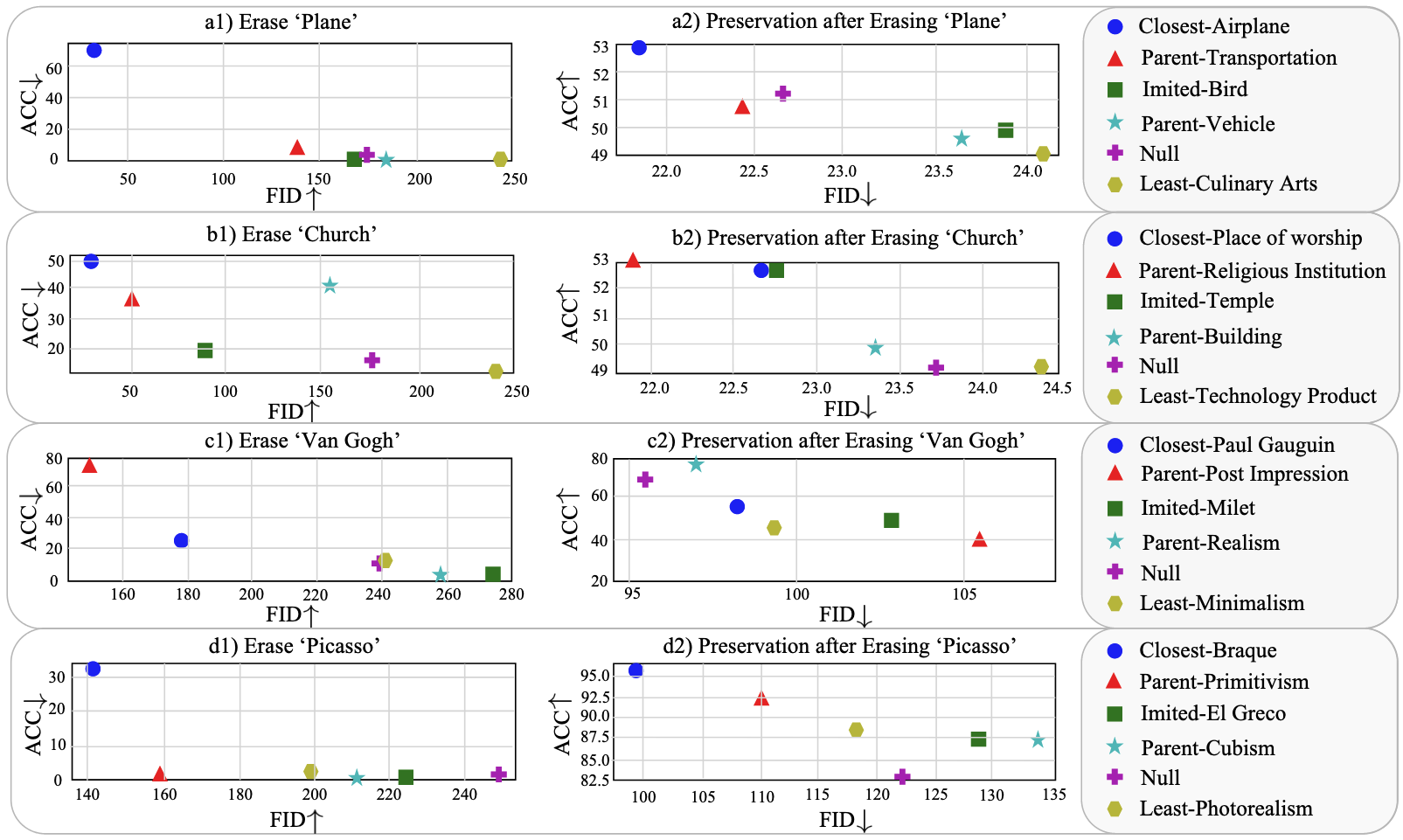
- 목표 개념과 가장 유사한 단어를 앵커로 사용할 때(Closest) FID와 ACC 지표 모두에서 가장 우수한 보존 성능을 보임 → 당연히 Unlearning 성능은 낮음
- 예를 들어, 'Plane' 제거 시 'Aircraft'를 앵커로 사용하는 것이 'Culinary Arts'보다 효과적
- 'Van Gogh' 제거 시 'Paul Gauguin' 같은 유사 화가 스타일을 앵커로 사용할 때 성능 보존이 더 우수함
- 관찰 2 (o2):
와 사이에 공유하는 문장이 길수록 보존 성능이 향상됨
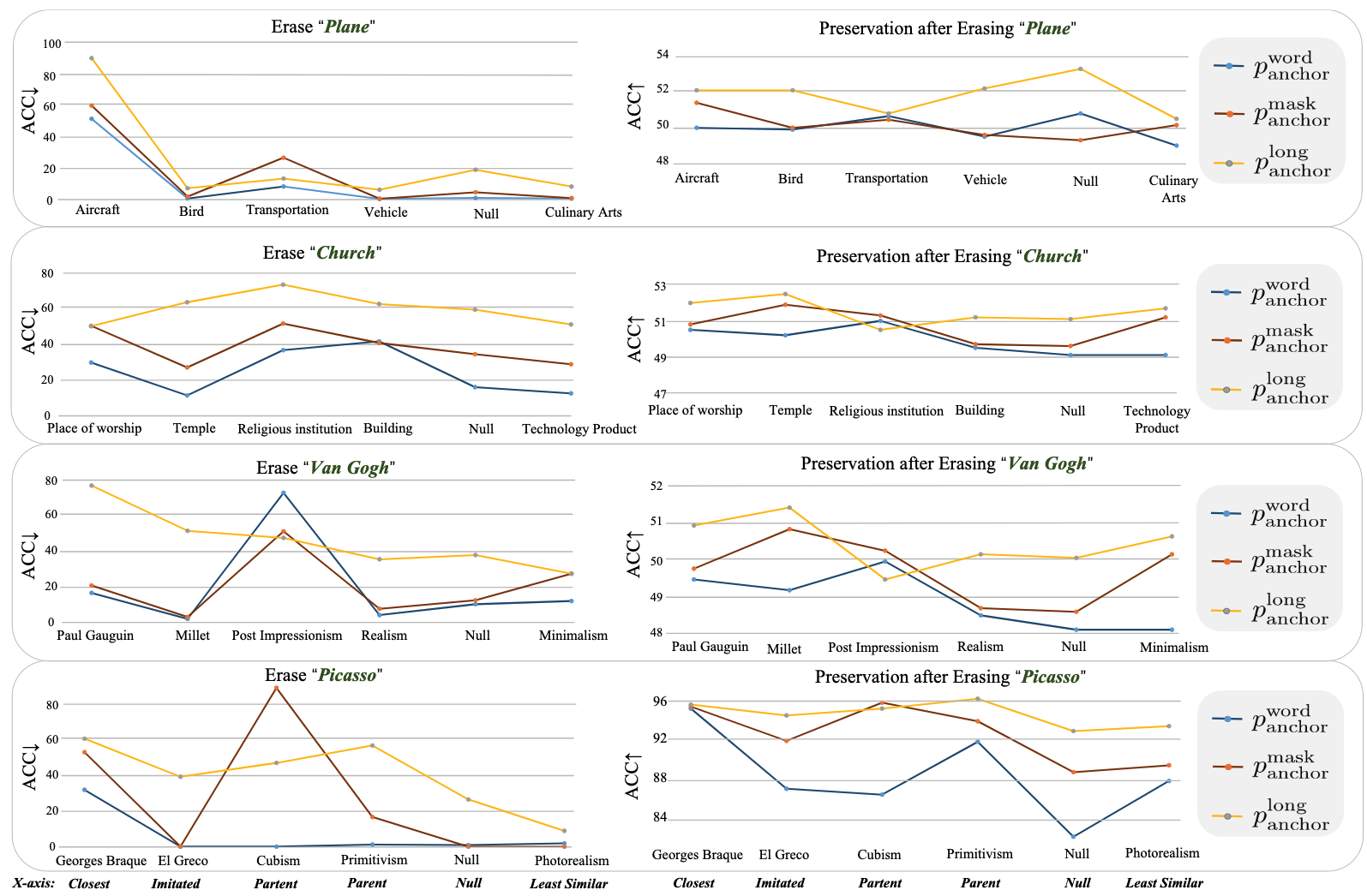
, , 사이의 성능 비교를 보여줌 (긴 문장 공유) > (마스크된 문장) > (단일 단어) 순으로 보존 성능이 우수함 - 공유 문장이 길수록 더 많은 컨텍스트 정보가 유지되어 모델의 다른 개념 생성 능력 손상을 최소화함
- 관찰 3 (o3):
를 사용한 언러닝이 다른 변형보다 우수한 제거 및 보존 성능을 달성함
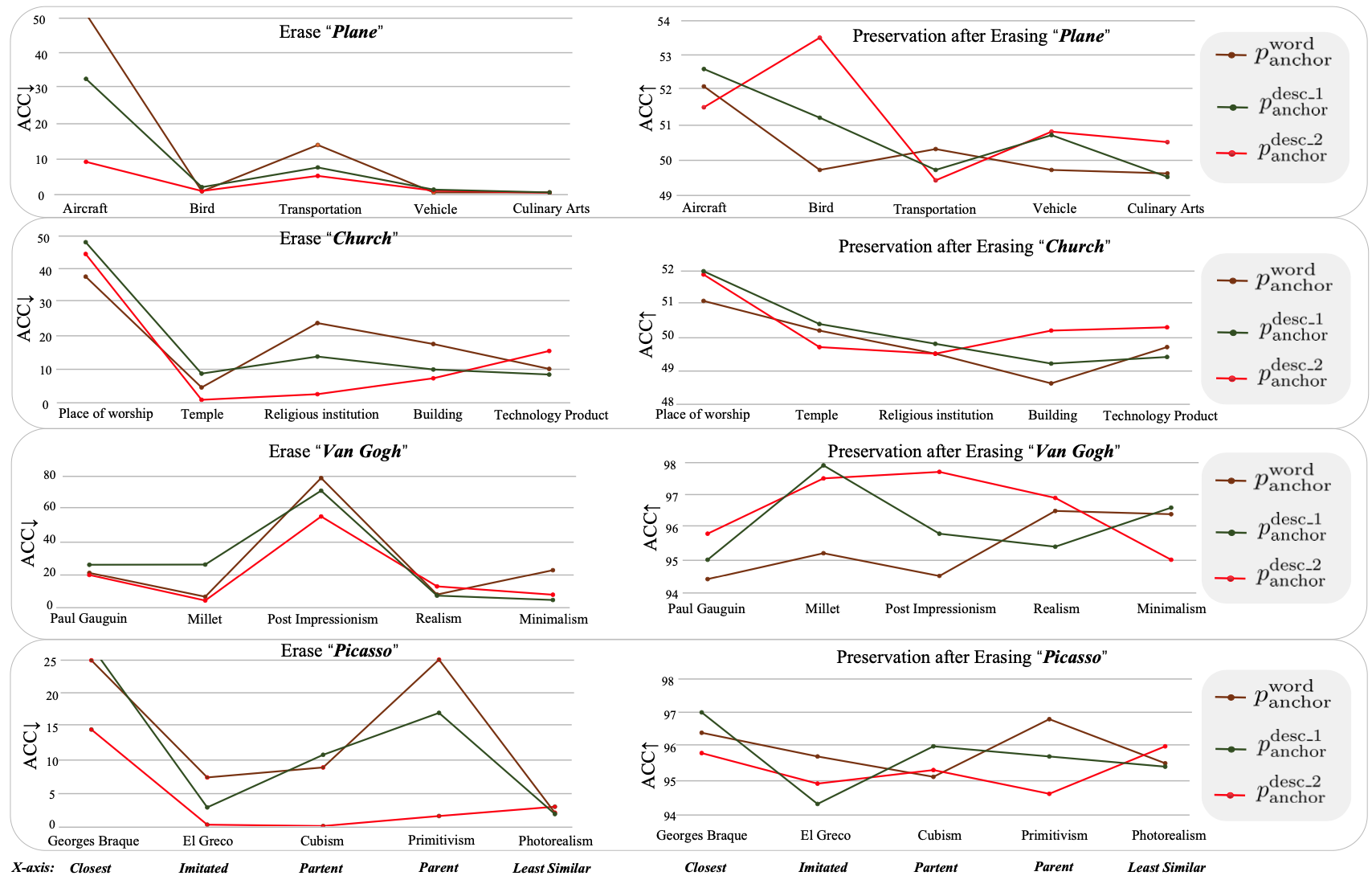
은 다른 앵커 유형보다 대체로 더 효과적 : Provide a sentence that describes the morphological features of . This sentence should include the common attributes between and . : , while excluding defining features of
- 형태적 특성은 유사하게 유지하면서 목표 개념의 정의적 특성만 제외하는 방식이 최적
- 예: 'Plane' 제거 시 "항공기의 일반적 특성을 가지지만 비행기의 정의적 특성은 제외한 물체" 같은 설명이 효과적
- 결론
- 모델 전반적 성능 보존을 위해서는
와 간 높은 유사성 유지가 중요함 (관찰 1, 2) - 원치 않는 개념의 효과적 제거를 위해서는 앵커에서 해당 개념의 정의적 속성을 제외해야 함 (관찰 3)
- 모델 전반적 성능 보존을 위해서는
Method
AdvAnchor
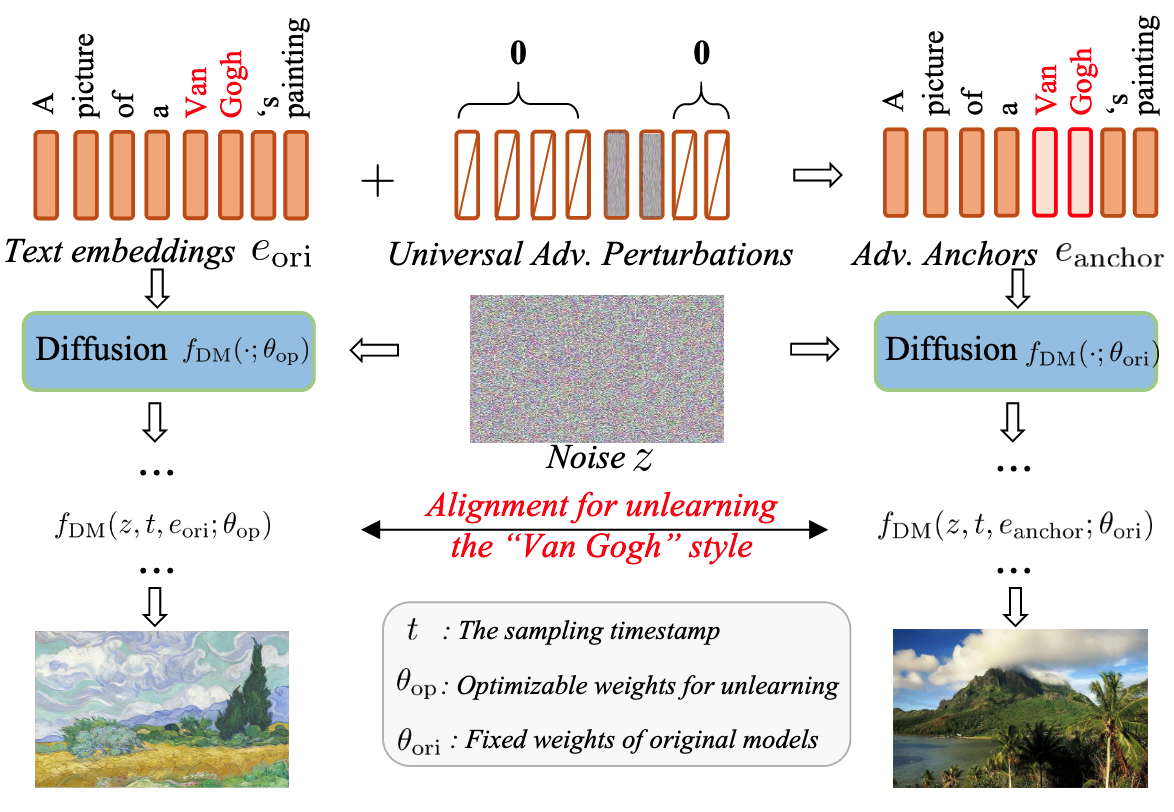
-
AdvAnchor 제안 배경: 작은 Adversarial Perturbation이 모델 예측에 큰 영향을 미칠 수 있다는 점과 Anchor 분석 결과(유사성 높은 Anchor는 보존↑, 제거↓)에 착안함.
- 제거하려는 컨셉에 노이즈를 더한 것 자체가 유사도를 높은 앵커 → 보존 성능이 높지만 삭제 성능은 낮음 → Adv Noise를 최적화 삭제 성능 개선
-
Adversarial Anchor
생성: Embedding 공간에서 원치 않는 Concept 에 를 추가하여 생성함. 이 Noise는 와 직접적으로 관련된 프롬프트에 추가함 - 여기서
와 는 각각 Prompt 와 Concept 의 Text Embedding임
- 여기서
-
Defining Attribute 제외:
에서 의 Defining Attribute를 제외하기 위해, 를 최적화 → AdvAnchor를 사용하면 Concept에 관한 생성을 하지 못하도록 함 의 Ground Truth 이미지는 , Random Noise는 , 사전 훈련된 DM의 고정된 가중치는
-
Denoising 과정에서 위 과정을 수행하기 위한 실제 최적화 함수
- 여기서
는 Pseudo Target 역할 최적화를 위한 Loss Functions: 를 위해 두 가지 함수를 설계함 : 와 에 대한 모델 예측 간의 Cosine Similarity를 측정: → 두 조건에서 예측된 노이즈 벡터 자체가 서로 다른 방향을 가지도록 : 와 로 인해 발생하는 생성 변화량 간의 유사성을 측정: , 여기서 ( 는 Empty Prompt Embedding) → 두 조건이 만들어내는 의미론적 변화 방향이 서로 달라지도록
- Vector Orthogonality에 착안하여
을 최적화의 중단 기준으로 설정함
- 여기서
-
통합 및 최적화 전략: 생성된
는 사전 정의된 Anchor를 대체하여 다양한 Unlearning 기법에 쉽게 통합될 수 있음 -
와 를 업데이트하기 위한 세 가지 최적화 전략을 설계함: - Alternating Optimization: 다양한 입력에 대해
와 를 번갈아 업데이트 - Sequential Optimization: 다양한 입력으로 최종
구성 후 미세조정 - Cyclical Optimization: Sequential Optimization과 대조적으로, 입력을 주기적으로 재방문하여
업데이트 - 실험의
로는 Cross-Attention만 사용함
- Alternating Optimization: 다양한 입력에 대해
Method 검증
스타일 언러닝 실험 (Style Unlearning)
- 9개 아티스트 스타일에 대한 언러닝 평가
- AdvAnchor(
) 효과: - 원치 않는 스타일 평균 FID/LPIPS: 0/0 → 417.4/0.408
- 원치 않는 스타일 평균 ACC: 99.2 → 4.2
은 우수한 제거 성능, 는 최적의 모델 보존 성능 제공 - AdvAnchor(
)가 기존 방법들(e.g., AbConcept, ESD)보다 보존 성능 우수: 평균 FID 75.4 (vs AbConcept 80.8, ESD 114.1)
객체 언러닝 실험 (Object Unlearning)
- Imagenette 데이터셋의 Category Name을 사용한 객체 언러닝 평가
- AdvAnchor는 객체 제거와 보존에서 우수한 성능 → 기존 방법들(SDD, All-but-one, ESD, AbConcept)보다 평균적으로 낮은 FID와 높은 ACC 달성
- 보존 성능 측면에서 Unlearning은 객체(평균 FID
24.0)보다 스타일(평균 FID 75.4)에 더 큰 영향을 미침
노출 콘텐츠 제거 실험 (Explicit Content Removal)
- I2P Prompt 사용, 4,073개 이미지 생성 및 노출 신체 부위 이미지 수 측정
- AdvAnchor(
)이 보다 노출 콘텐츠 제거에 효과적 ( 의 초기값이 더 높기 때문) - 원본 모델 815개 → AdvAnchor(
) 85개 (Best Run, 89.6% 감소) - 다른 방법들(SDD, All-but-one, ESD, AbConcept)보다 우수한 제거 능력과 ACC 측면의 보존 성능 달성
최적화 전략 및 하이퍼파라미터 영향 (Optimization & Hyperparameter)
- Alternating Optimization 전략이 제거 및 보존 성능 균형 측면에서 가장 효과적
+ Alternating Opt: 노출 이미지 107개 (Avg), FID 23.4/ACC 53.8 + Cyclical Opt: 노출 이미지 66개 (Avg, 제거↑), FID 25.6/ACC 52.4 (보존↓)
에서 반복 횟수( ) 증가 → 제거 성능 향상, 보존 성능 감소 → 높은 값은 Anchor와 Concept의 유사도를 떨어뜨림 =20: 노출 이미지 204.7개 (Avg), FID 22.7 =50: 노출 이미지 95.3개 (Avg), FID 25.0
Limitation
- 트레이드오프 여전히 존재: 제거 성능을 극대화하면 보존 성능이 저하됨
- 반복 횟수(
)와 손실 함수( vs ) 선택에 따라 성능 균형이 달라짐 - 모든 유형의 개념에 동일하게 적용하기 어려움 → 개념의 복잡성에 따라 효과 차이