Knowledge Composition using Task Vectors with Learned Anisotropic Scaling
Pre-trained models produce strong generic representations that can be adapted via fine-tuning on specialised datasets. The learned weight difference relative to the pre-trained model, known as a task vector, characterises the direction and stride of fine-tuning that enables the model to capture these specialised representations. The significance of task vectors is such that simple arithmetic operations on them can be used to combine diverse representations from different domains. This paper builds on these properties of task vectors and aims to answer (1) whether components of task vectors, particularly parameter blocks, exhibit similar characteristics, and (2) how such blocks can be used to enhance knowledge composition and transfer. To this end, we introduce aTLAS, an algorithm that linearly combines parameter blocks with different learned coefficients, resulting in anisotropic scaling at the task vector level. We show that such linear combinations explicitly exploit the low intrinsic dimensionality of pre-trained models, with only a few coefficients being the learnable parameters. Furthermore, composition of parameter blocks enables modular learning that effectively leverages the already learned representations, thereby reducing the dependency on large amounts of data. We demonstrate the effectiveness of our method in task arithmetic, few-shot recognition and test-time adaptation, with supervised or unsupervised objectives. In particular, we show that (1) learned anisotropic scaling allows task vectors to be more disentangled, causing less interference in composition; (2) task vector composition excels with scarce or no labelled data and is less prone to domain shift, thus leading to better generalisability; (3) mixing the most informative parameter blocks across different task vectors prior to training can reduce the memory footprint and improve the flexibility of knowledge transfer. Moreover, we show the potential of aTLAS as a parameter-efficient fine-tuning method, particularly with less data, and demonstrate that it can be easily scaled up for higher performance.
Problem:: 기존 Task Vector가 구조적 중요도를 고려하지 않음
Solution:: 중요한 Layer마다 다른 가중치를 두어 Task Vector를 이용
Novelty:: Intrinsic Dimensionality와의 관게를 나타내어 이론적 배경을 보이고, 이를 실험적으로 증명/Weight가 정보 전달의 주 요소임을 보임/각 층에 따른 중요도를 보임
Note:: 기본 아이디어는 기존 Task Vector에서 크게 달라진 건 없음. 더하는 방식만 개선해서 간단해 보이지만 3.2절 작성을 잘한듯
Summary
Motivation
- Pre-Trained 모델은 일반적인(Generic) 표현을 생성하며 Fine-Tuning을 통해 특정 데이터셋에 적응 가능
- Task Vector(사전 훈련 모델과 Fine-Tuned 모델 간의 가중치 차이)는 Fine-Tuning 과정의 방향과 크기를 특성화하고 해당 작업에 특화된 표현을 포착
- 기존 연구에서는 Task Vector에 단순 산술 연산을 통해 서로 다른 도메인의 표현을 결합 가능함을 보여줌
- 다른 층(Layer)에 있는 Parameter Block은 중요도가 다름 (초기 층은 일반적 특징 추출, 깊은 층은 작업별 특징 생성)
- Task Vector 내 구성 요소(Parameter Block)가 유사한 특성을 가지는지, 그리고 이러한 블록이 지식 구성과 전달을 개선하는 데 어떻게 활용될 수 있는지는 불명확
Method
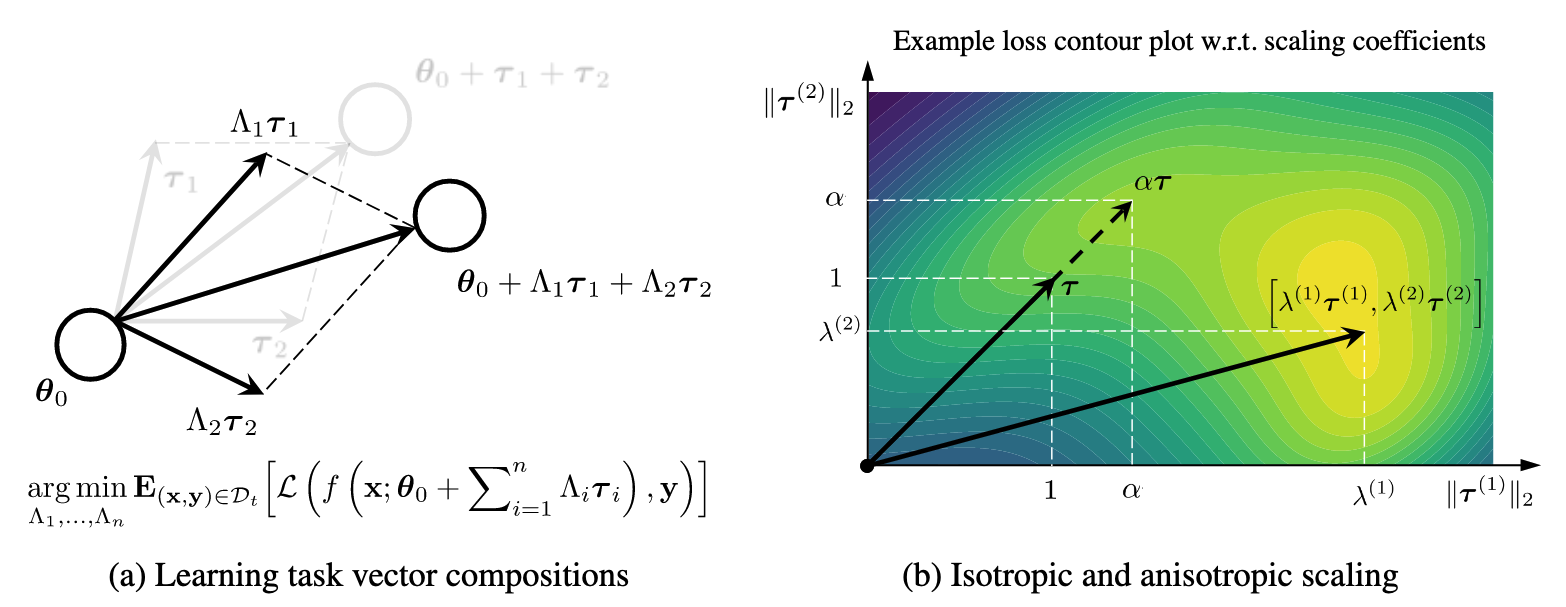
Base
- Standard Task Vector는 말 그대로 Pretrained Weight
와 해당 모델의 Fine-tuned Weight 간의 차로 구성 됨 - 사용시:
, 는 이미지
- 사용시:
- Linearized Task Vector는 두 벡터의 차를 이용하지만, Taylor expansion을 이용함
- 사용시:
- 사용시:
는 말 그대로 단순한 상수, 더하는 정도를 의미
aTLAS
는 사실 각 레이어의 Weight, Bias 등의 파라미터 블록으로 이루어 짐: : 파라미터 블록 수
- 기존 방법은
를 통으로 더하거나 뺌 → 각 블록 단위로 다르게 더하거나 빼자 (Anisotropic) → 를 로 변경해서 사용하자 - 그리고 이
를 학습하자 : 입력 에 대응하는 레이블 : 목표 데이터셋 : 태스크 벡터 수
- 학습 파라미터수:
- 추론 시 모델:
- 기존 방식과 비교하여 추가 계산 비용 없음
Intrinsic Dimensionality
- 딥 뉴럴 네트워크는 종종 낮은 내재적 차원성을 가진 해결책을 제시 → 사실 각 Weight들이 어떤 Task와 관련된 저차원 공간으로 임베딩 되는거 아니냐?
- Learnable
인 경우, Random Projection Matrix 가 저차원으로 임베딩하고, Learnable한 를 찾는게 Intrinsic Dimensionality를 이용하는게 됨 → 근데 가 이고 가 라고 생각하면 구조가 동일하네? → 근데 실제로 는 랜덤이 아니고 Task Vector니까 더 효과적일 듯
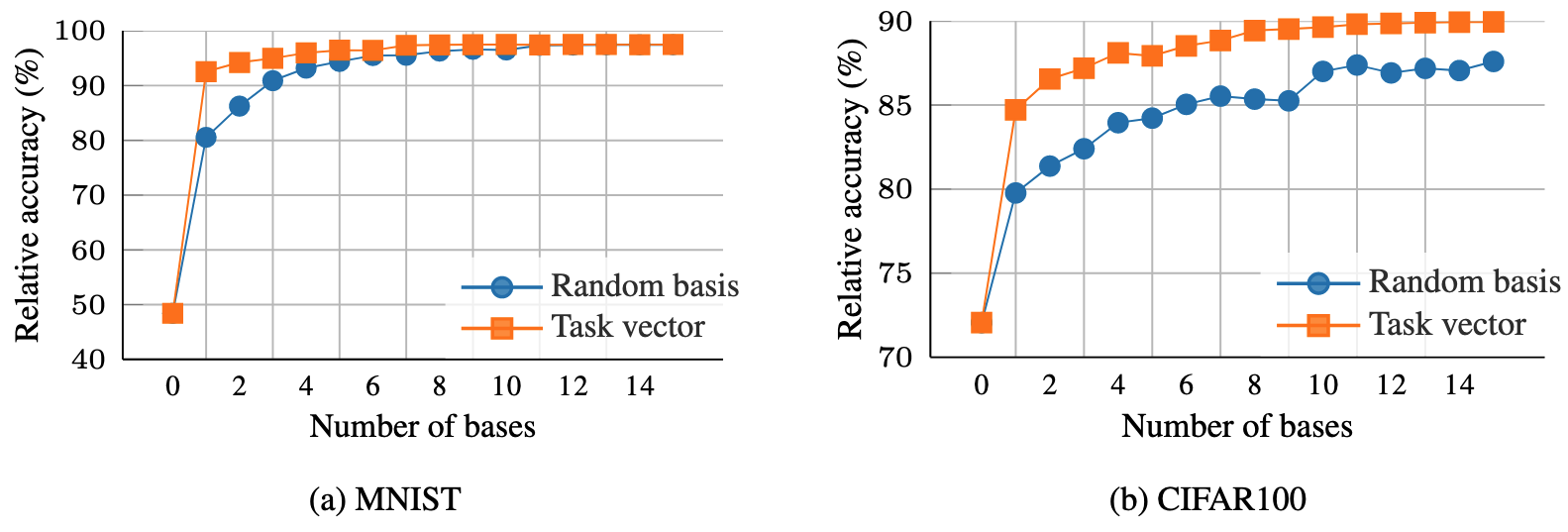
실제로 더 효과적임
Method 검증
Task Arithmetic
- Task Negation 실험: aTLAS가 표준 Task Vector의 성능을 크게 향상시킴 (평균 정확도 23.22%→18.76% 감소) → Anisotropic 스케일링이 불필요한 편향 제거에 효과적
- Task Addition 실험: aTLAS가 다중 작업 모델에서 큰 개선 달성 (기존 대비 93.79% 상대 정확도) → Task Vector 간 간섭 감소
- 가중치 행렬(Weight Matrices)이 일관되게 더 큰 계수를 가짐 → 가중치 행렬이 지식 전달의 주요 매개체임을 확인
- 실제로 가중치 행렬에 대해서만 aTLAS를 적용해도 성능 하락폭이 적음
- 더 깊은 층에서 더 높은 계수가 나타남 → 깊은 층이 작업별 특징 생성에 더 중요함을 입증
Few-Shot Recognition
- aTLAS는 최소한의 레이블 데이터로도 최신 방법보다 우수한 성능 달성 (1-Shot에서 6.5% 포인트 개선) → 적은 데이터로도 효과적인 지식 전달 가능성 입증
- 재밌는 점은 Linearized Task Vector가 일관되게 성능이 낮음 → 이에 대한 분석은 없음
- aTLAS는 기존 Few-Shot 방법(Tip-Adapter, LP++)과 상호 보완적 → 결합 시 성능 추가 향상
- Out-of-Domain 데이터셋에서 일관된 성능 향상 보임 → 도메인 변화에 강한 일반화 능력 입증
Test-Time Adaptation
- aTLAS가 LayerNorm 파라미터 튜닝보다 높은 정확도 달성 (6.5% 포인트 개선) → 레이블 없는 데이터에서도 효과적
- 다양한 자기지도학습 목표(Contrastive, Entropy, Pseudo Labeling)에서 모두 성능 향상
Parameter-Efficient Fine-Tuning
- LoRA를 희소 Task Vector로 활용 시 메모리 소비 감소 (10.7GB→3.3GB) → 자원 제약 환경에서도 효율적 사용 가능
- Task Vector Budget 실험: Parameter Block 단위 선택이 전체 Task Vector 선택보다 효과적 → 다른 Task Vector에서 정보가 풍부한 Parameter Block을 혼합하여 지식 전달 유연성 향상
- Random으로 선택하는거랑 기존 방식대로
의 Gradient를 기준으로 선택하는 방식 성능이 비슷함
- Random으로 선택하는거랑 기존 방식대로
- aTLAS를 확장하여 학습 가능한 파라미터 수를 증가시킬 수 있으며(aTLAS ×K 변형), 충분한 훈련 데이터에서 더 높은 성능 달성 → Parameter-Efficient Fine-Tuning 방법으로서의 잠재력 입증