Domain-Consistent and Uncertainty-Aware Network for Generalizable Gaze Estimation
Unsupervised domain adaptive (UDA) gaze estimation aims to predict gaze directions of unlabeled target face or eye images given a set of annotated source images, which has been widely applied in practical applications. However, existing methods still perform poorly due to two major challenges. 1) There exists large personalized differences and style discrepancies between source and target samples, which leads the learned source model easily collapsing to biased results; 2) Data uncertainties inherent in reference samples will affect the generalization ability of their models. To tackle the above challenges, in this paper, we propose a novel Domain-Consistent and Uncertainty-Aware (DCUA) network for generalizable gaze estimation. Our DCUA network employs a two-phase framework where a primary training sub-network (PTNet) and a refined adaptation sub-network (RANet) are trained on the source and target domain, respectively. Firstly, to obtain robust and pure gaze-related features, we propose twain domain consistent constraints, that is, the intra-domain consistent constraint and the inter-domain consistent constraint. These two constraints could eliminate the impact of gaze-irrelevant factors by maintaining consistency between label and feature space. Secondly, to further improve the adaptability of our model, we propose dual uncertainty perception modules, which include an intrinsic uncertainty module and an extrinsic uncertainty module. These modules help DCUA network distinguish inferior reference samples and avoid overfitting to them. Experiments on four cross-domain gaze estimation tasks demonstrate the effectiveness of our method.
Problem:: UDA Gaze Estimation의 Domain 간 개인/스타일 차이로 인한 성능 저하 / 데이터(Source Noise/Target Pseudo Label) 불확실성으로 일반화 한계
Solution:: Twain Domain Consistent Constraints (Intra-Domain / Inter-Domain)로 Gaze 무관 요소 제거 / Dual Uncertainty Perception Modules (Intrinsic / Extrinsic)로 데이터 불확실성 관리
Novelty:: UDA Gaze Estimation에 Uncertainty Learning 최초 도입 및 Source/Pseudo Label 불확실성 동시 정량화 및 완화
Note:: Uncertainty에 관한 부분이 흥미로웠지만 이걸 정량화 및 완화 하는 방식이 좀 애매한 듯
Summary
Motivation
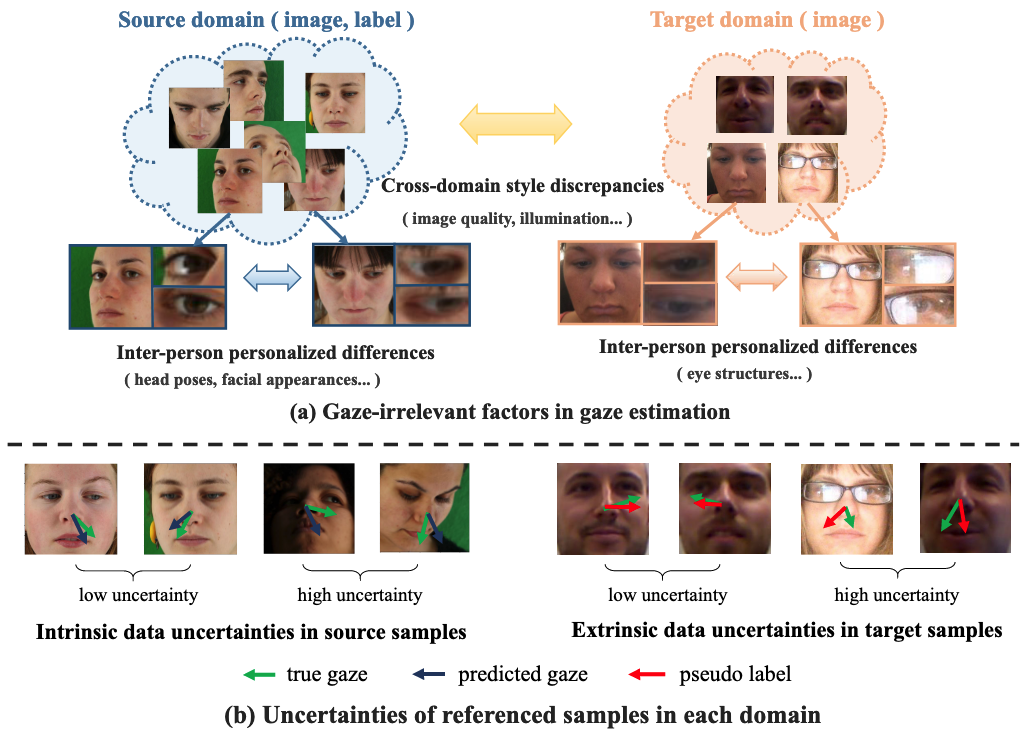
- 기존 Unsupervised Domain Adaptive (UDA) Gaze Estimation 방법들은 다음과 같은 두 가지 주요 문제점으로 인해 성능이 저조함
- Source Sample과 Target Sample 간의 큰 개인별 차이 (Personalized Differences) 및 스타일 불일치 (Style Discrepancies) 로 인해 학습된 Source Model이 편향된 결과로 쉽게 붕괴됨
- Inter-Person Personalized Differences: 동일 Domain 내 다른 개인 간의 Head Poses, Facial Appearances, Eye Structures 등의 차이
- Cross-Domain Style Discrepancies: 다른 Domain 간의 Image Quality, Illumination, Environment 등의 차이
- 참조 Sample에 내재된 데이터 불확실성 (Data Uncertainties) 이 모델의 일반화 능력에 영향을 미침
- Intrinsic Data Uncertainties: Source Domain 내 Extreme Head Poses나 Partial Occlusion을 가진 Noisy Sample로 인한 불확실성
- Extrinsic Data Uncertainties: Target Domain의 Calibration Sample에 대한 Pseudo Label과 실제 Gaze 간의 각도 오류로 인한 불확실성
- Source Sample과 Target Sample 간의 큰 개인별 차이 (Personalized Differences) 및 스타일 불일치 (Style Discrepancies) 로 인해 학습된 Source Model이 편향된 결과로 쉽게 붕괴됨
- 이러한 문제점들을 해결하여 일반화 성능이 높은 Gaze Estimation 모델을 개발하는 것이 목표임
Method
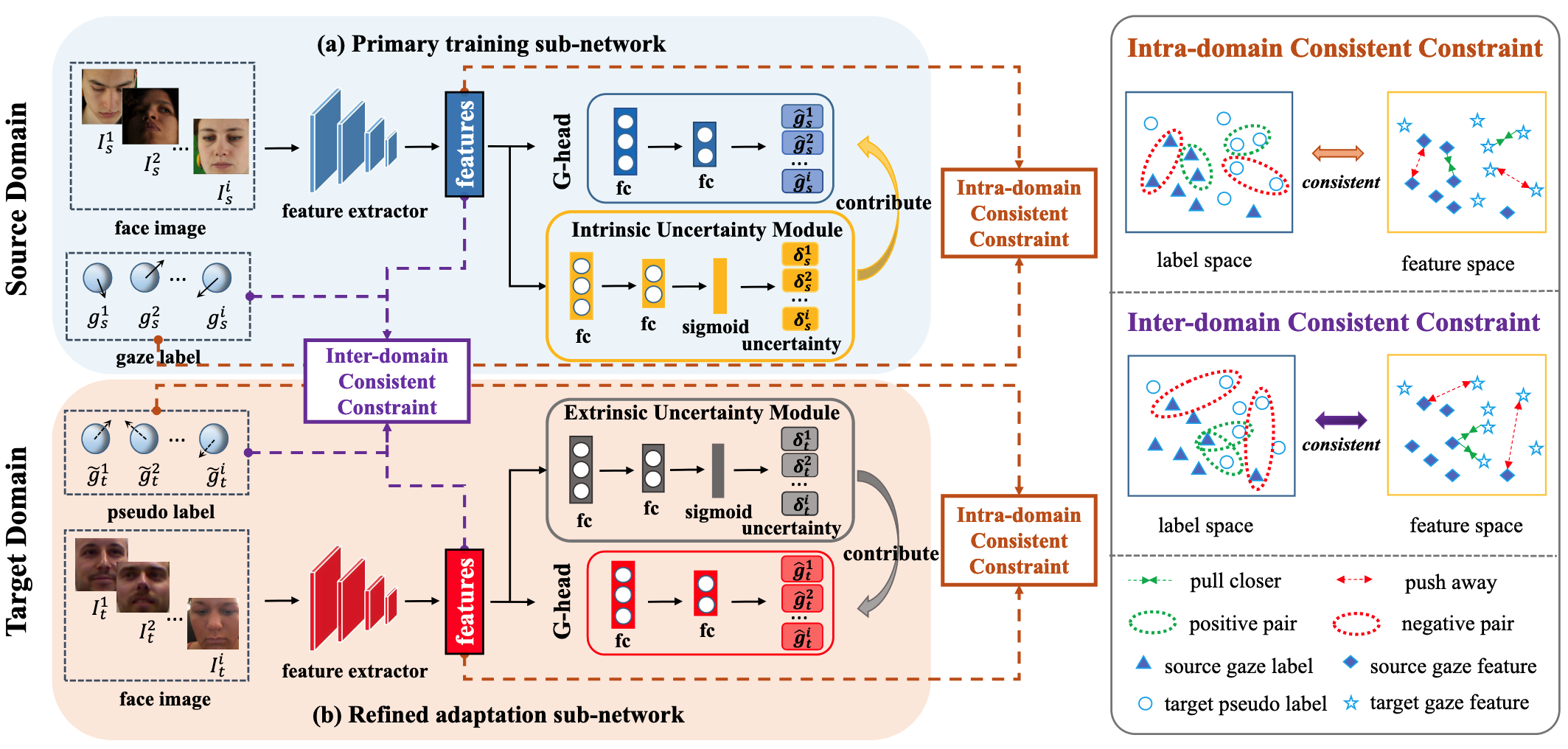
- Domain-Consistent and Uncertainty-Aware (DCUA) Network 제안
- Two-Phase Framework → 1단계로 In-domain 학습, 2단계로 Cross-Domain 개선
- Primary Training Sub-Network (PTNet): Source Domain에서 Annotated Training Sample을 사용하여 학습
- Refined Adaptation Sub-Network (RANet): Unlabeled Target Sample과 해당 Pseudo Label을 사용하여 학습
- Twain Domain Consistent Constraints
- Gaze와 무관한 요소 (Personalized Differences, Style Discrepancies)의 악영향을 제거하고 일반화 가능한 Feature 추출 목표
- Loss:
- Inter-Domain은 Source, Intra-Domain은 Source와 Target에 대해 계산
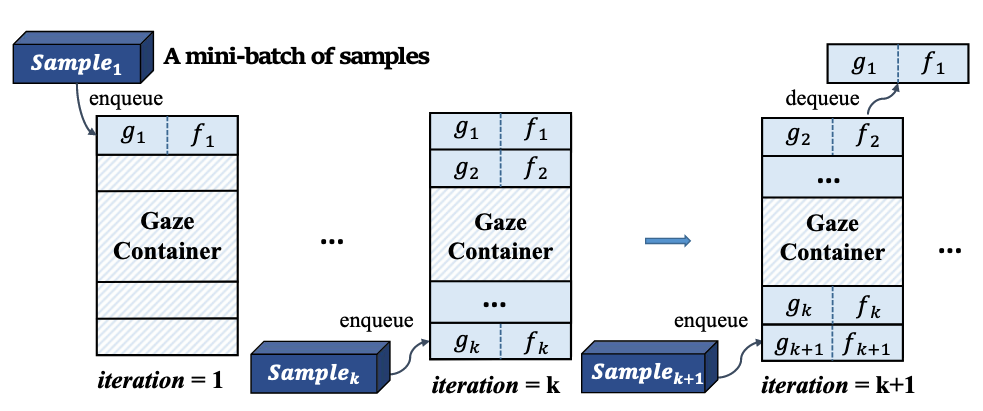
- Offline Gaze Container: Positive/Negative Pair를 효율적으로 선택하기 위한 Query Dictionary (Queue 형태로 구현하여 확장성 확보)
- Dual Uncertainty Perception Modules
- 참조 Sample의 Noisy Data 문제를 해결하기 위해 각 Sample의 중요도 측정
- Loss:
( 는 작은 상수) - Uncertainty Value
예측 (Prediction Variance 로 간주) - 별도의 모듈을 달아서 측정
- 시선 예측이 정확한 경우 첫 번째 항의 영향이 작아 두 번째 항을 줄임 → Var을 줄임
- 시선 예측이 부정확한 경우 첫 번째 항의 영향이 커 → Var을 키움
- 즉, 시선 예측이 정확 할 수록 Uncertainty가 낮아지는 양의 상관관계를 가지도록 함
- Intrinsic은 Source, Extrinsic은 Source와 Target에 대해 계산
- Overall Objective Functions
- PTNet (
Phase): - RANet (
Phase):
- PTNet (
- Network Architecture: ResNet18 또는 ResNet50을 Backbone으로 사용
- Two-Phase Framework → 1단계로 In-domain 학습, 2단계로 Cross-Domain 개선
Method 검증
- Datasets: ETH-XGaze (
), Gaze360 ( ), MPIIFaceGaze ( ), EYEDIAP ( ) - Source Datasets:
, - Target Datasets:
, - Adaptation Tasks:
, , ,
- Source Datasets:
- Comparison with State-of-the-Art Methods
- 비교군: ADDA, UMA, RSD (General UDA Methods), GazeAdv, PnP-GA, PureGaze (One-Stage UDA Gaze Estimation), Gaze360, DAGEN, CRGA, RUDA (Two-Stage UDA Gaze Estimation)
- DCUA (ours)는 ResNet18 Backbone 사용 시
(5.59 deg), (6.40 deg / 5.74 deg (6400 samples)) Task에서 SOTA 달성 - DCUA# (ours)는 ResNet50 Backbone 사용 시
(5.61 deg), (6.11 deg / 5.82 deg (6400 samples)) Task에서 SOTA 달성 - 통찰: 제안된 Two-Stage Framework와 Domain Consistent Constraints, Uncertainty Perception Module이 Target Domain으로의 적응을 효과적으로 도움
- Ablation Study
Phase: - 통찰:
와 제약 조건이 함께 사용될 때 Baseline보다 성능 향상. 각 제약 조건이 개별적으로 추가될 때는 일부 Task에서 성능이 하락하거나 미미한 변화를 보였으나, 최종적으로 모든 요소를 결합했을 때 가장 좋은 성능을 보임. 이는 각 요소가 상호 보완적으로 작용함을 시사함
- 통찰:
Phase (Pre-trained 사용): - 통찰:
단계에서 모든 제약 조건을 사용했을 때 단계보다 일관되게 성능 향상, 이는 Target Data를 사용한 Adaptation의 중요성을 나타냄. Inter-Domain Consistent Constraint ( ) 도입 시 정확도 추가 향상
- 통찰:
- Properties of Twain Domain Consistent Constraints
- Within Domain (Intra-Domain):
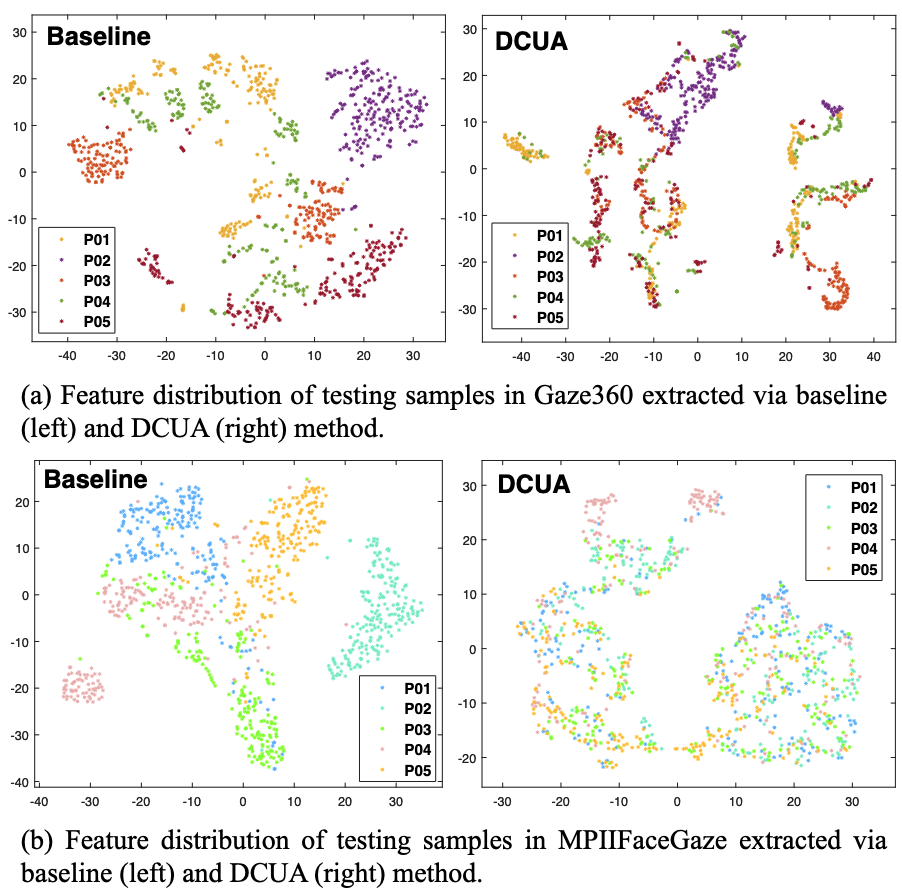
- 실험 방법: Gaze360과 MPIIFaceGaze에서 각각 5명 (각 200 샘플)의 Feature Embedding을 Baseline과 DCUA로 추출하여 t-SNE로 시각화
- 결과: DCUA가 Baseline보다 Subject-Agnostic Representation을 학습하여 개인 간 차이를 줄임
- 통찰: Intra-Domain Consistent Constraint가 효과적으로 개인별 차이를 완화함
- Cross Domain (Inter-Domain):
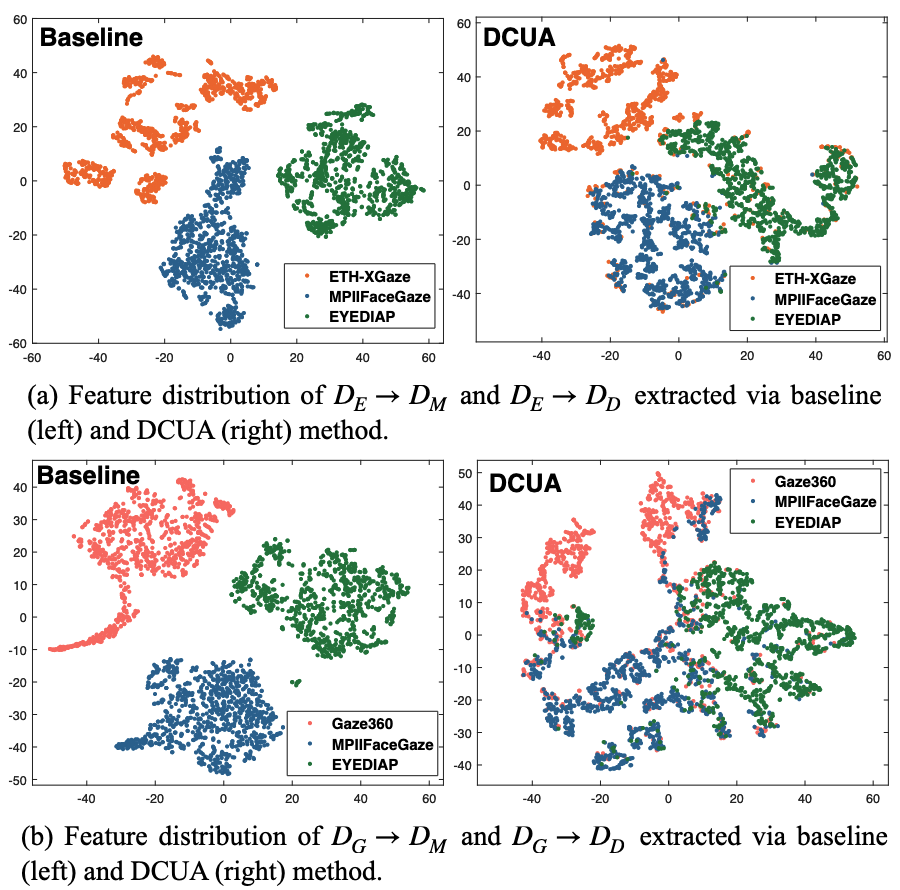
- 실험 방법: 각 Dataset에서 1000개 Sample을 무작위 선택하여 Feature Embedding을 Baseline과 DCUA로 추출하여 시각화
- 결과: DCUA가 Baseline에 비해 다른 Domain 간의 Gap을 좁힘
- 통찰: Inter-Domain Consistent Constraint가 Cross-Domain Style Discrepancies를 제거하고 Domain-Invariant Feature 학습에 도움을 줌
- Within Domain (Intra-Domain):
- Evaluation of Queue-based Gaze Container
- Selection of Positive and Negative Pairs
- 비교 방법: Batch-based method, Fixed container-based method, Our queue-based method
- 결과: 제안된 Queue-based 방법이 정확도 측면에서 가장 우수하며, 시간 복잡도는 다른 방법들과 유사함
- 통찰: Queue-based Container가 적절한 Positive/Negative Pair를 효과적으로 선택하여 모델의 일반화 및 정확도 향상에 기여함
- Construction of Gaze Container (Size Analysis)
- 실험 방법:
의 Gaze Container 크기 비율 , 의 Target/Source Gaze Container 크기 비율 변경 - 결과:
일 때 최적 성능 - 통찰: Container 크기가 너무 작으면 유사/비유사 Sample 선택이 어렵고, 너무 크면 Pair의 다양성이 감소하여 성능 저하 가능성
- 실험 방법:
- Analysis for The Number of Pairs
- 실험 방법:
의 Container 대비 Pair 수 비율 , 의 Target/Source Container 대비 Pair 수 비율 변경 - 결과:
일 때 최적 성능 - 통찰: 너무 적은 Pair는 상관관계 특성화에 불충분하고, 너무 많은 Pair는 부적절한 Pair를 포함할 가능성이 있어 정확도에 영향
- 실험 방법:
- Selection of Positive and Negative Pairs
- Evaluation of Uncertainty Modules
- Weighting Mechanisms for Noisy Data
- 비교 설정: Setting 1 (Equal Weights - ew), Setting 2 (Large Weights for Large Errors - lw), Setting 3 (Small Weights for Large Errors - sw, 제안 방법)
- 결과: 제안 방법 (Setting 3)이
와 단계 모두에서 가장 좋은 성능을 보임 - 통찰: 큰 Uncertainty를 가진 Sample에 덜 집중하는 것이 Gaze Estimation Task에서 더 합리적임
- Qualitative Analysis of Data Uncertainty
- MPIIFaceGaze 결과 시각화. Gaze Error와 Uncertainty Value가 양의 상관관계를 보이며, DCUA가 Baseline보다 낮은 Error를 보임
- MPIIFaceGaze Sample 100개에 대한 Gaze Error와 Uncertainty Value 곡선이 잘 일치함
- 4개 Dataset의 Noisy Sample (Incorrect Samples, Inaccurate Samples) 시각화. Incorrect Sample은 Label 자체가 이미지와 달라 보이며, Inaccurate Sample은 Label은 정확하나 이미지 품질 문제로 예측이 어려운 경우
- 통찰: Uncertainty Module이 Noisy Sample을 정확히 구별하고 Overfitting을 방지하여 모델 정확도 향상에 기여함
- Weighting Mechanisms for Noisy Data
- More Discussion
- Backbone of DCUA Network
- 실험: ResNet18과 ResNet50 Backbone 비교
- 결과: 두 Backbone 모두에서 DCUA Network (PTNet, RANet)가 Baseline보다 우수한 성능을 보임
- 통찰: 제안된 DCUA Network의 효과는 Backbone 종류에 크게 의존하지 않음
- Selection of Primary Gaze Network Loss
- 비교 Loss: L1 Loss (제안 방법), L2 Loss, Cosine Distance Loss
- 결과: L1 Loss가 전반적으로 가장 좋은 성능을 보임. L2 Loss는 수렴 값은 작으나 일반화 성능이 L1보다 떨어질 수 있고, Cosine Loss는 제약 강도가 가장 약함
- 통찰: L1 Loss가 정확도와 일반화 성능 모두에 적합하여 UDA Task에 유리함
- Analysis of Hyper Parameters
- 실험: 각 Loss Term의 Weight (
) 변경 - 결과: Weight가 0일 때 성능 저하가 크지만, 그 외 범위에서는 모델이 Weight 변화에 민감하지 않음
- 통찰: 제안된 Constraint들이 중요하며, Hyperparameter 튜닝에 비교적 강건함
- 실험: 각 Loss Term의 Weight (
- Backbone of DCUA Network