Taskonomy: Disentangling Task Transfer Learning
Do visual tasks have a relationship, or are they unrelated? For instance, could having surface normals simplify estimating the depth of an image? Intuition answers these questions positively, implying existence of a structure among visual tasks. Knowing this structure has notable values; it is the concept underlying transfer learning and provides a principled way for identifying redundancies across tasks, e.g., to seamlessly reuse supervision among related tasks or solve many tasks in one system without piling up the complexity. We proposes a fully computational approach for modeling the structure of space of visual tasks. This is done via finding (first and higher-order) transfer learning dependencies across a dictionary of twenty six 2D, 2.5D, 3D, and semantic tasks in a latent space. The product is a computational taxonomic map for task transfer learning. We study the consequences of this structure, e.g. nontrivial emerged relationships, and exploit them to reduce the demand for labeled data. We provide a set of tools for computing and probing this taxonomical structure including a solver users can employ to find supervision policies for their use cases.
Problem:: 개별 시각 문제 해결 접근법은 많은 Labeled Data 필요 / 시각 문제들 간의 복잡한 관계 및 구조가 잘 알려져 있지 않음 / 사람의 직관과 신경망의 학습 방식이 다를 수 있음
Solution:: 다양한 26개 Task Dictionary 간 Transfer Learning으로 관계 매핑 / Task 간 전이 의존성을 나타내는 Taskonomy 그래프 생성 / 제한된 Supervision Budget 하에서 최적 전이 정책 탐색
Novelty:: 시각 문제 공간의 구조를 체계적으로 매핑한 최초의 완전 자동 계산 방식 / 이종 Task 간 전이 유사도 정규화를 위한 AHP(Analytic Hierarchy Process) 사용 / 최적 전이 정책 선택 문제를 BIP(Boolean Integer Program)로 공식화
Note:: 이런 생각을 선행 연구도 없이 떠올리고 실제로 실행에 옮긴 행동력이 부럽다 / 유사하게 Encoder 고정하고 Transfer시 성능 차이로 서로 다른 Task간의 의존성을 측정할 수 있을 듯
Summary
Motivation
- 다양한 Visual Task (Object Recognition, Depth Estimation 등)들이 존재하며, 이들 간에는 명확하거나 혹은 불분명한 관계가 존재할 것으로 예상됨
- 기존의 연구들은 주로 개별 Task를 독립적으로 해결하려 했으며 (Siloing tasks), 이로 인해 새로운 Task를 학습하거나 포괄적인 인식 시스템을 구축하는 데 많은 Labeled Data와 노력이 필요했음
- Task들 간의 관계, 즉 Task Space의 구조를 파악하면 Transfer Learning을 통해 Supervision 효율성을 높이고, 계산량을 줄이며, 예측 가능한 모델을 개발할 수 있음
- 하지만 이 Task Space 구조는 아직 잘 알려져 있지 않으며, 사람의 직관이나 분석적 지식과 Neural Network의 작동 방식이 다를 수 있어 (e.g., Depth와 Surface Normal 관계) Fully Computational 접근 방식이 필요함
Method
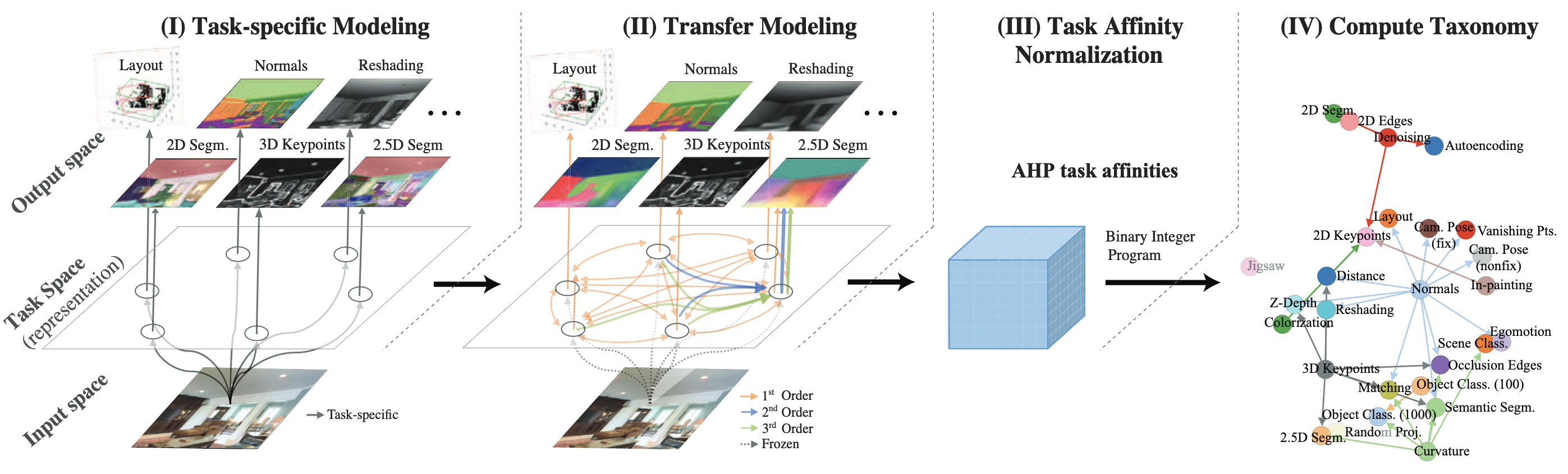
- Taskonomy: Task 간의 Transferability를 포착하는 계산적으로 발견된 Directed Hypergraph
- 4단계 프로세스로 Taskonomy 구축:
- Task-Specific Modeling: 각 Source Task (
)에 대해 Encoder-Decoder 구조의 Task-Specific Network를 학습 → 각 Task의 단일 성능 - 모든 Task에 대해 Encoder 구조는 동일 (Fully Convolutional ResNet-50 without pooling)
- Decoder는 Task의 Output 특성에 따라 다름 (Pixel-to-Pixel: 15-layer FCN, Low Dimensional: 2-3 FC layers)
- Transfer Modeling: Source Task (
)의 Representation ( )을 입력받아 Target Task ( )를 예측하는 작은 Readout Function ( ) 을 학습 → Encoder 고정 시키고, 1단계보다 적은 데이터로 다른 Task에 대한 성능 측정
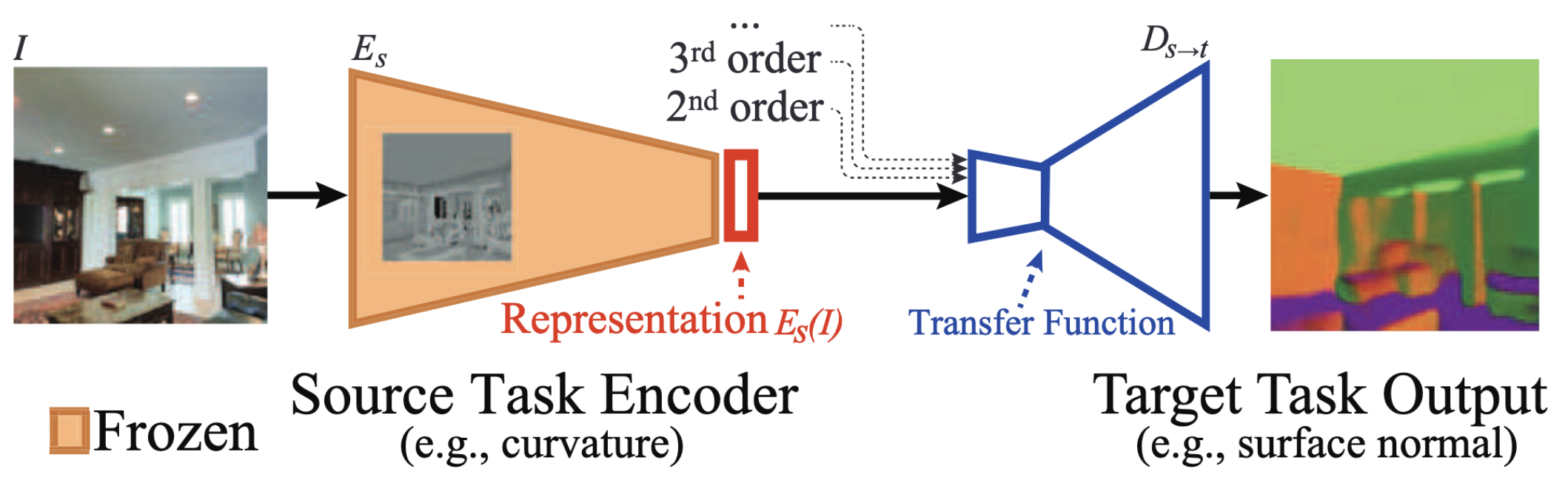
- Source Network의 Encoder는 고정 (Frozen)
- Transfer Function은 적은 데이터 (Task-Specific 대비 8x~120x 적음)로 학습하여 정보의 접근성 (Accessibility) 측정 → Source Task의 Representation에서 Target Task 해결에 필요한 정보가 얼마나 쉽게 접근 가능한지 측정하기 위함
- Higher-Order Transfers: 여러 Source Task의 Representation을 동시에 입력받아 Target Task를 예측 (e.g.,
) → 여러 Repr는 Concat 하여 사용 - 조합 폭발 문제를 해결하기 위해 Beam Search 기반 샘플링 사용
- Task Affinity Normalization: 서로 다른 Scale과 Space를 가진 Transfer 성능(
)을 Ordinal Approach (AHP: Analytic Hierarchy Process) 를 이용해 정규화 → 각 Task의 성능 지표가 서로 다르므로, 순위를 고려하여 정규화 - 각 Target Task (
)에 대해 Source Task들 간의 Pairwise Tournament Matrix ( ) 구축 ( 가 보다 더 나은 성능을 보인 이미지 비율) 를 정규화하여 생성 ( ) → 두 Source Repr 중 뭐가 얼마나 더 잘하는지를 측정 의 Principal Eigenvector를 계산하여 최종 Task Affinity ( ) 도출
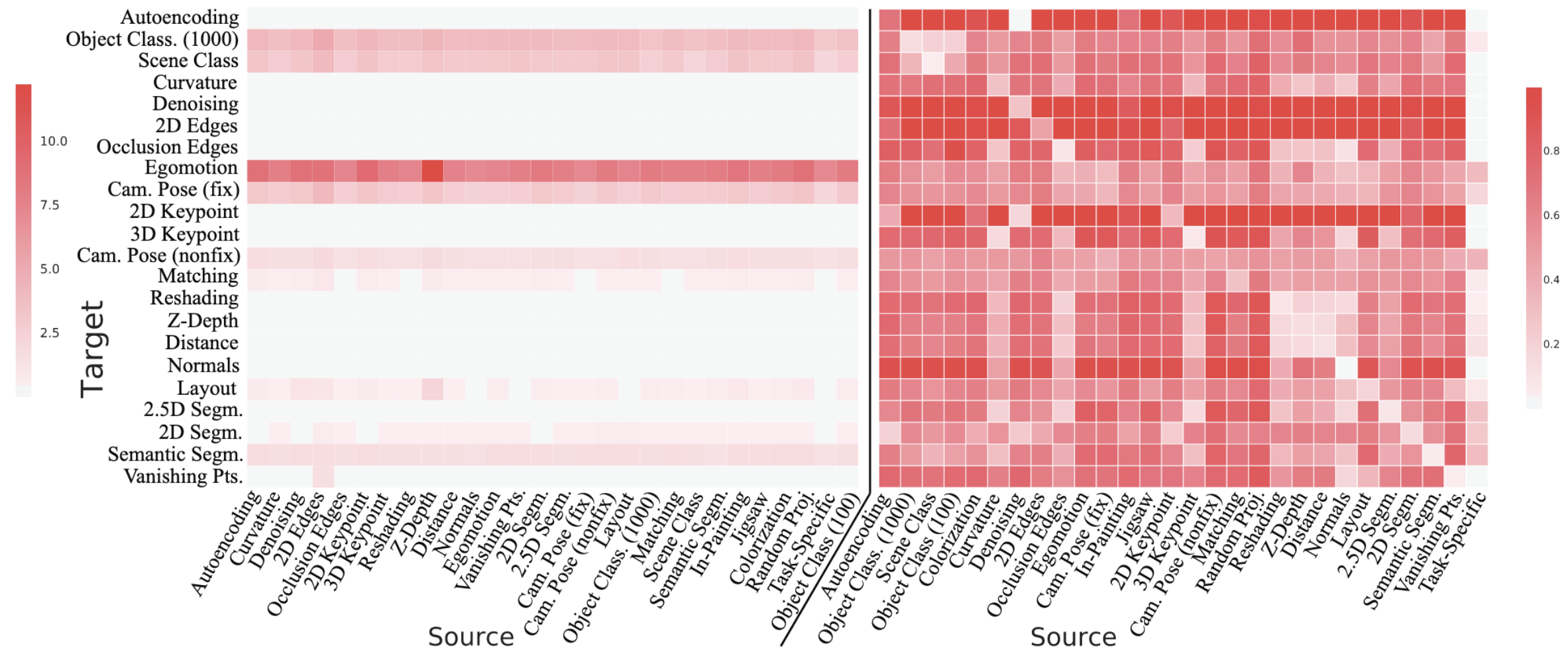
- 각 Target Task (
- Compute Taxonomy: 정규화된 Task Affinity (
)와 Supervision Budget ( ) 제약 하에, 전체 Task에 대한 Collective Performance를 최대화하는 최적의 Transfer Policy (Subgraph)를 Boolean Integer Programming (BIP)으로 탐색 → 최소한의 Source 학습으로 다수의 Target의 성능을 최대화하는 조합 탐색 - 목적 함수:
, where (각 Transfer의 성능( )과 Target Task 중요도( )의 곱의 합) - 제약 조건:
- Constraint I: 선택된 Transfer의 모든 Source Task는 반드시 Source Node로 포함되어야 함
- Constraint II: 각 Target Task는 정확히 하나의 Transfer를 받아야 함
- Constraint III: 총 Source Task 수가 Supervision Budget (
)을 초과하지 않아야 함
- 목적 함수:
- Task-Specific Modeling: 각 Source Task (
- Task Dictionary: 2D, 2.5D, 3D, Semantic Task 등 26개의 다양한 Visual Task 포함

- Dataset: 약 600개 건물에서 수집된 4백만 개의 실내 이미지로 구성, 모든 이미지에 대해 26개 Task의 Annotation 보유
- Knowledge Distillation 등을 활용하여 Annotation 생성
Method 검증
- Task-Specific Network 성능 검증: 학습된 각 Task-Specific Network의 성능을 두 가지 Baseline과 비교 (Win Rate (%) 측정)
* Baseline 1 (random): 가우시안 분포로 초기화된 Random Network Encoder의 Representation을 Readout하여 예측
* Baseline 2 (avg): 데이터셋 전체의 통계적 평균값을 이용해 예측 (Statistically Informed Guess)
* Win Rate (%): Test 데이터셋에서 Task-Specific Network가 Baseline보다 더 나은 성능을 보인 이미지의 비율- 정량적 성능: 대부분의 Task에서 Baseline 대비 높은 Win Rate (평균 92.4% vs avg, 90.9% vs random)를 보여 네트워크가 잘 학습되었음을 확인
- 통찰: 제안된 방법론의 기반이 되는 Task-Specific Network들이 단순히 무작위 예측이나 평균 예측보다 훨씬 뛰어나며, 안정적이고 신뢰할 만한 성능을 가짐
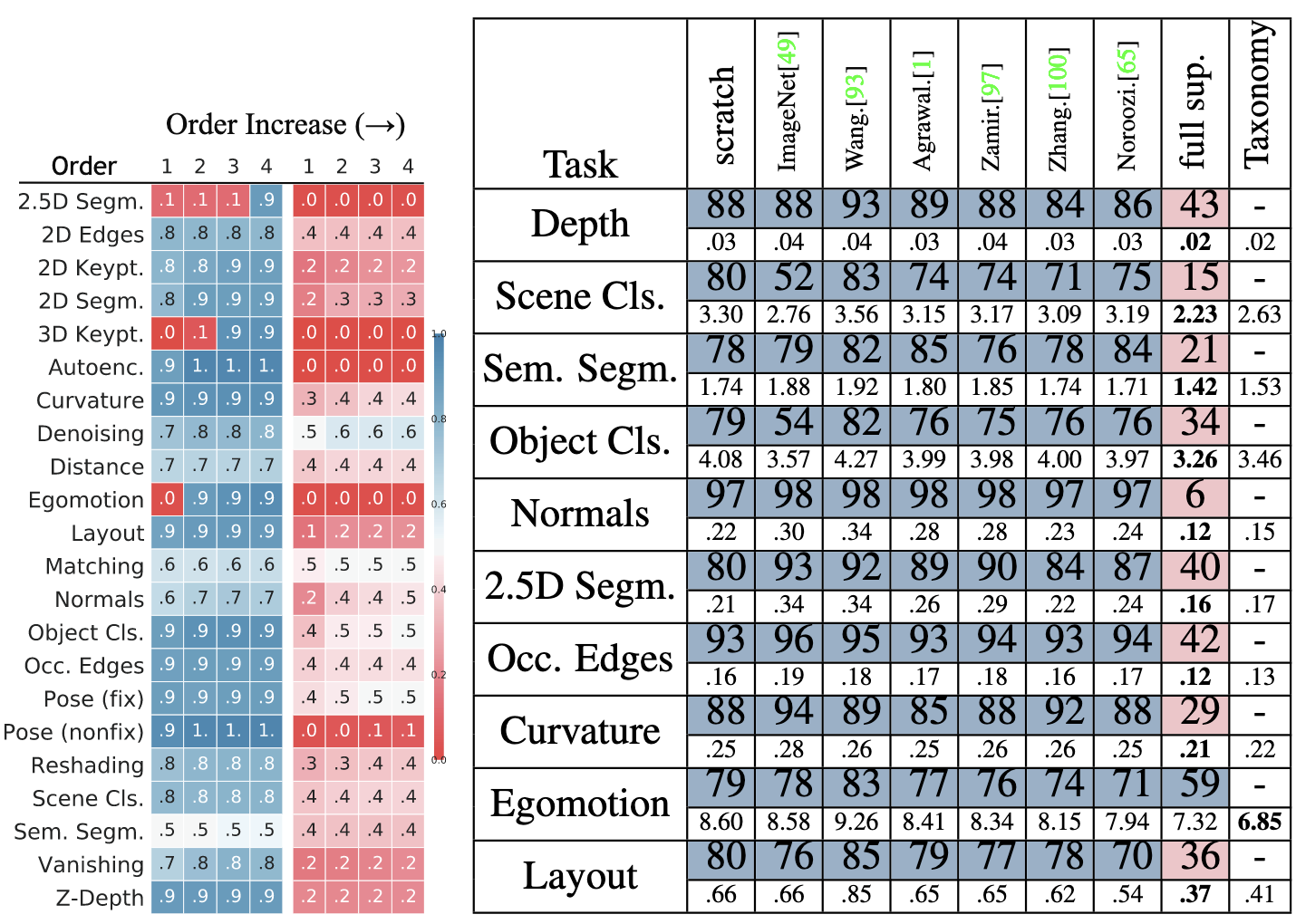
- Computed Taxonomies 평가: 다양한 Supervision Budget과 Maximum Transfer Order 조건 하에서 BIP를 통해 계산된 Taxonomy (Transfer Policy)의 성능을 Gain과 Quality Metric으로 평가 → 최종 목표랑 비슷한 경향을 보임
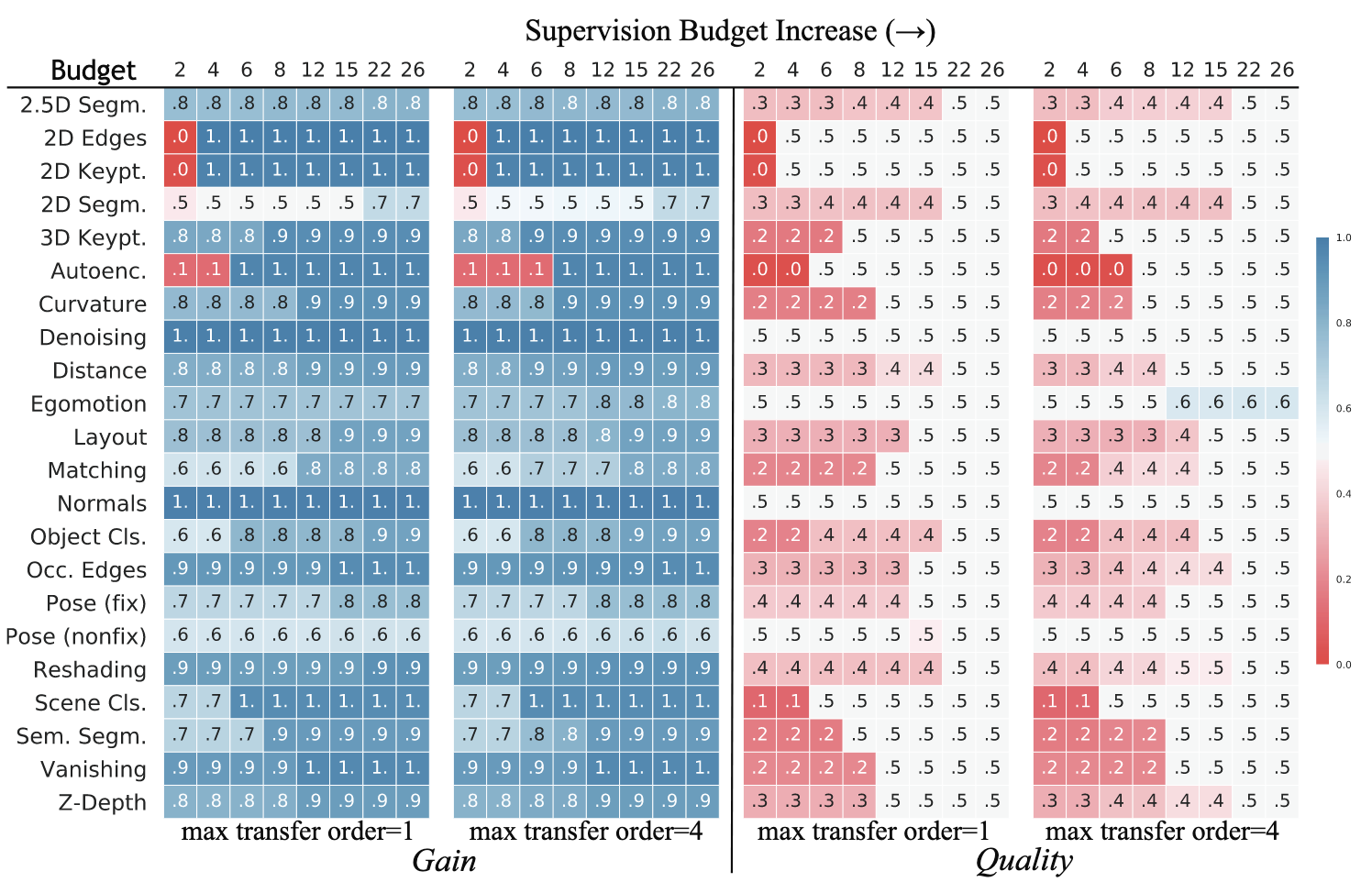
- Gain: 동일한 소량 데이터로 Scratch부터 학습한 모델 대비 Win Rate (%) → Transfer Learning으로 얻은 성능 향상
- Quality: 대량 데이터(120k)로 학습한 Fully Supervised 모델 (Gold Standard) 대비 Win Rate (%) → 최종 목표 성능
- 정량적 성능: Supervision Budget이 증가함에 따라 Gain과 Quality가 향상됨. 제한된 Budget 하에서도 상당한 성능 달성 가능. Higher-Order Transfer (Order 4)가 Order 1보다 전반적으로 더 나은 성능을 보임
- 통찰: Taskonomy가 제안하는 Transfer Policy가 제한된 Supervision으로도 효과적으로 Task를 해결할 수 있으며, Higher-Order Transfer가 성능 향상에 기여함
- Generalization to Novel Tasks (Out-of-Dictionary): Dictionary에 없는 새로운 Task를 설정하고, 나머지 Task를 Source로 하여 최적의 Transfer Policy를 BIP로 탐색 (All-for-one). 이 Policy의 성능을 다른 Self-Supervised 방법들과 비교
- 정량적 성능:
- Gain/Quality: 대부분의 Novel Task에서 높은 Gain과 Quality를 달성하며, Transfer Order가 높아질수록 성능 향상 경향
- 비교: 기존 Self-Supervised 방법들 및 ImageNet Pre-trained Feature보다 Taskonomy 기반 Policy가 월등히 높은 Win Rate를 보임
- Fully Supervised 대비: 많은 경우 Fully Supervised 모델보다는 성능이 낮지만, 상당히 근접한 결과 (40%대 Win Rate)를 보임
- 통찰: Taskonomy는 Dictionary에 없는 새로운 Task에 대해서도 효과적인 Transfer Policy를 제공하며, 이는 Task에 맞춰진 신중한 Policy 선택이 고정된 Transfer 방식(Self-Supervised)보다 우수함을 시사함. Task Space가 예측 가능하고 강한 구조를 가짐을 암시
- 정량적 성능:
- Structure Significance Test: 제안하는 Policy의 성능을 Random하게 연결된 Transfer Policy들과 비교
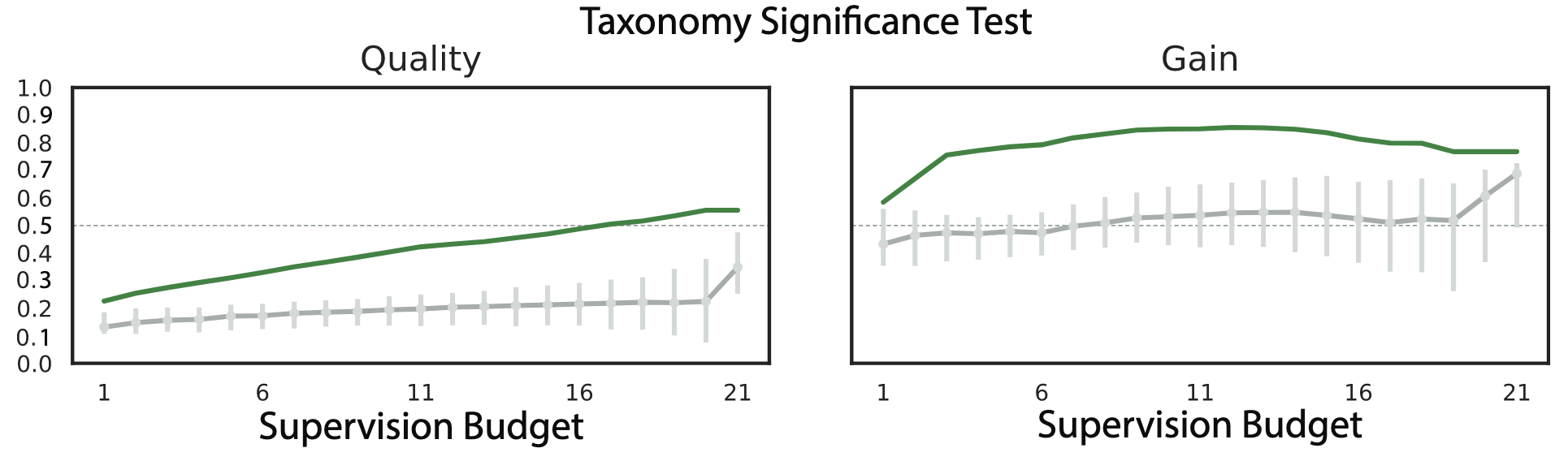
- 정량적 성능: Taskonomy Policy가 모든 Random Policy보다 월등히 높은 성능을 보임
- 통찰: Task Space에는 유의미하고 강한 구조가 존재하며, 제안된 Taskonomy 방법론이 이 구조를 효과적으로 모델링함
- Evaluation on MIT Places & ImageNet: Taskonomy의 Source Task들의 Transfer 성능 순위와, 실제 MIT Places/ImageNet 데이터셋에서 Fine-tuning 했을 때의 성능 순위 간의 상관관계 (Spearman's rho) 분석
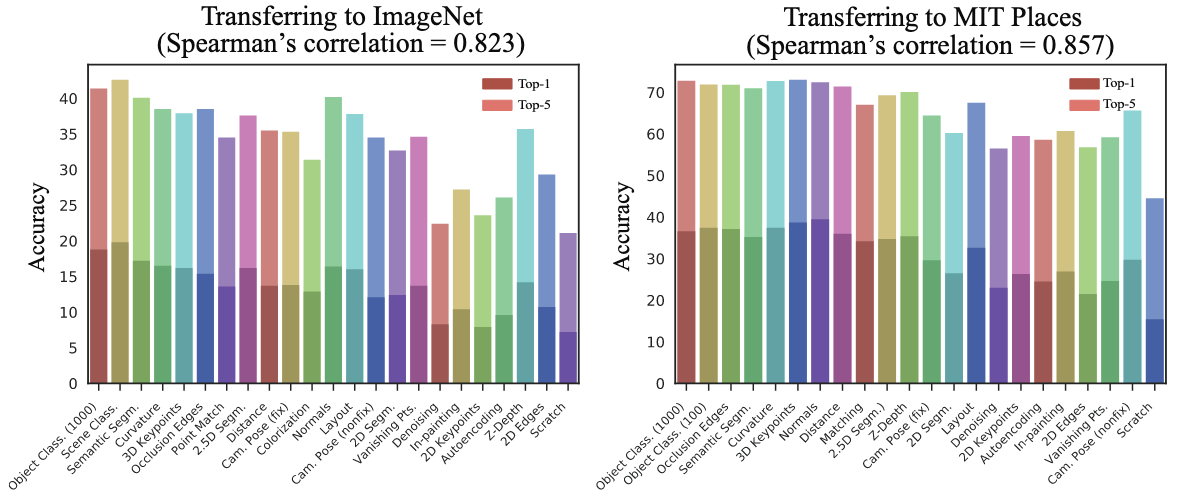
- 정량적 성능: Places에서 0.857, ImageNet에서 0.823의 높은 Spearman's rho 값을 보여 강한 상관관계를 확인
- 통찰: Taskonomy를 통해 발견된 Task Space 구조는 특정 데이터셋에 크게 의존적이지 않으며, 다른 데이터셋(Places, ImageNet)에도 일반화될 수 있음
- Universality of the Structure (Stability Test): 시스템 설계 요소 (Task-Specific Network, Transfer Function, Transfer 학습 데이터 양, 데이터셋, 데이터 분할, Dictionary)를 변경했을 때 최종 Taxonomy 결과의 변화 정도 측정
- 정량적 성능: 설계 요소에 큰 변화(e.g., 데이터 양 16배, 아키텍처 크기 4배 변경)를 주었음에도 최종 Taxonomy 결과는 거의 변하지 않고 안정적이었음
- 통찰: 발견된 Task Space 구조는 특정 모델 아키텍처나 데이터 조건에 크게 구애받지 않는 보편적인 특성을 가짐