Learning Conflict-Noticed Architecture for Multi-Task Learning
Multi-task learning has been widely used in many applications to enable more efficient learning by sharing part of the architecture across multiple tasks. However, a major challenge is the gradient conflict when optimizing the shared parameters, where the gradients of different tasks could have opposite directions. Directly averaging those gradients will impair the performance of some tasks and cause negative transfer. Different from most existing works that manipulate gradients to mitigate the gradient conflict, in this paper, we address this problem from the perspective of architecture learning and propose a Conflict-Noticed Architecture Learning (CoNAL) method to alleviate the gradient conflict by learning architectures. By introducing purely-specific modules specific to each task in the search space, the CoNAL method can automatically learn when to switch to purely-specific modules in the tree-structured network architectures when the gradient conflict occurs. To handle multi-task problems with a large number of tasks, we propose a progressive extension of the CoNAL method. Extensive experiments on computer vision, natural language processing, and reinforcement learning benchmarks demonstrate the effectiveness of the proposed methods.
Problem:: 다중 태스크 학습(MTL)에서 공유 파라미터의 Gradient 충돌 문제 발생/기존의 Gradient 조작 방법으로는 근본적인 아키텍처 충돌 해결 어려움 존재
Solution:: Purely-Specific Module을 도입해 태스크별로 충돌 시 독립적인 모듈 학습/동적 분기 시점을 자동 학습하여 최적의 아키텍처를 탐색
Novelty:: Gradient 충돌 문제를 아키텍처 설계 관점에서 접근한 최초의 시도
Note:: Task 충돌 문제를 GazeTarget의 Detection과 Estimation에 적용하려고 봤는데, 아키텍쳐적 접근 방식이라서 참고할게 없었음
Summary
Motivation
- 파라미터가 공유되는 하나의 모델에서 여러개의 태스크를 동시에 학습시키는 것은 성능에 악영향을 줌
- 여러 개의 태스크가 서로 강하게 관련지 않음 → 두 태스크가 업데이트하는 방향이 반대 → 성능 악화
- 따라서, 보통 모든 태스크가 공통된 인코더를 쓰고 디코더만 다르게 사용함 → 이것도 여러 태스크가 관련되어 있어야 잘 동작
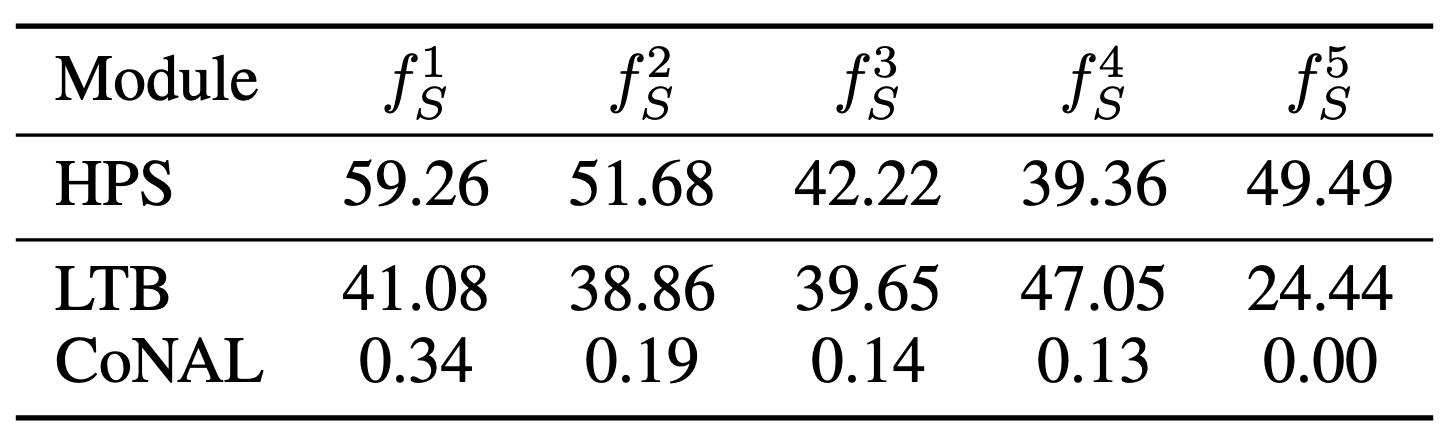
- 기존 방법들을 적용해도 공유된 인코더에서 두 태스크의 업데이트 방향이 반대임 (HPS, LTB)
- LTB는 Multi Task Learning (MTL)에 적합한 아키텍쳐를 학습하는 연구로, 이 경우 약간 줄어드는걸 볼 수 있음
- LTB는 Shared Module (모든 태스크가 관여)와 Partially-Specific Module (특정 태스크와 모든 태스크가 관여)를 사용 → Partially-Specific의 경우 관력이 적거나 관련이 없는 태스크에도 영향을 받음 → Sub Optimal한 방식
Method
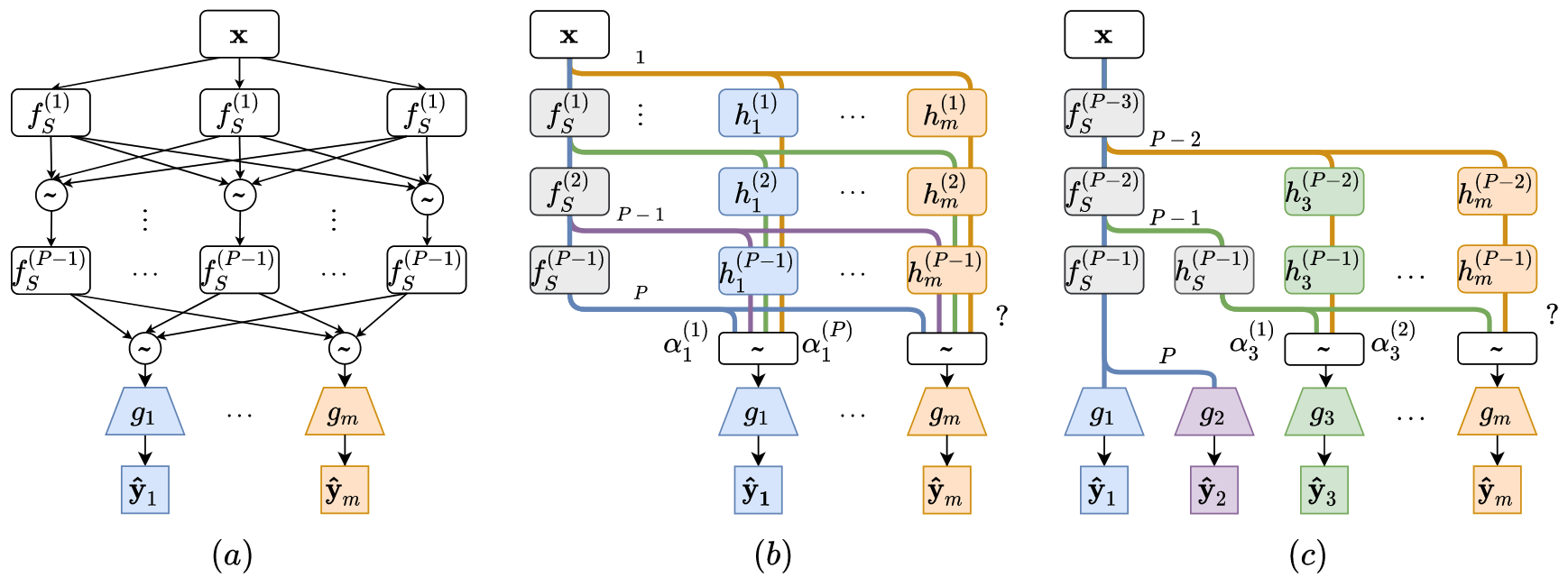
(a) LTB, (b) CoNAL, (c) CoNAL-Pro
- 목적: MTL에 적합한 Architecture 찾기
- CoNAL: All-Shared와 함께 Purely-Specific Module 도입
- All-Shared Encoder
에서 분기하는 시점에 관한 파라미터 찾기 는 태스크 인덱스, 는 분기 시점을 의미 - 해당 파라미터가 0이면 Purely-Specific Module
와의 연결이 끊김
- 찾은 모델을 이용해 Multi Task Loss로 학습
- 이때 연결이 끊긴 모든 모듈들은 제거함
- All-Shared Encoder
- CoNAL-Pro: 태스크가 점진적으로 늘어나는 경우를 위한 방법
- 학습하는 태스크 수
이 커지면 연산량 너무 커짐 - 비슷한 태스크들이 Shared Encoder에 지배적인 영향을 줄 수 있음
- 첫 번째 단계
- 공유 모듈
에서 시작 - 각 과제
의 선택: : Shared Module 사용 : Purely-Specific Module 로 분기
- 공유 모듈
- 두 번째 단계
- 검색 공간 축소:
- 새로운 공유 모듈
추가 - 모든 태스크가 분기가 할당 될 때까지 반복
- 검색 공간 축소:
- 마지막 단계
- 분기점이 1밖에 남지 않으면 다 Purely-Specific과 연결
- 학습하는 태스크 수
Method 검증
- Multi-Task 벤치마크 성능 분석:
- 다양한 컴퓨터 비전 데이터셋(CityScapes, NYUv2, PASCAL-Context, Taskonomy)에서 평가 → 단일 과제 학습(STL) 대비 일관된 성능 향상
- 하드 파라미터 공유(HPS) 방식 대비 최대 +1.76% 성능 개선 → 다중 태스크 학습 시 아키텍처 학습 효과 입증
- Architecture Learning 능력 분석:
- CoNAL이 각 태스크에 대해 최적의 분기 지점을 자동 탐색 가능
- 태스크 간의 연관성에 따라 동적이고 최적화된 아키텍처 자동 조정 → 적은 파라미터 수로 높은 성능 달성
- 강화 학습 성능 개선:
- MT10 Challenge에서 평균 성능 0.76 달성 → 단일 과제 정책(0.78) 대비 경쟁력 있는 성능 유지
- 훈련 속도 6.25배 향상 → 효율적 학습 입증
- CelebA 데이터셋 실험 결과:
- 9개의 다중 태스크 학습에서 최저 총 테스트 오류 달성 → CoNAL-Pro 아키텍처 (모델 파라미터 30.58M)가 최적 성능
- 기존 방법 대비 효율적인 태스크 그룹핑 수행 능력 입증
- 구현 관련 Ablation Study:
- Purely-Specific Module 도입으로 성능 +1.16% 향상 → 태스크 간 갈등 최소화 효과 확인
- Conflict-Noticed 연산 도입 시 추가로 +0.6% 성능 개선 → 갈등 상황 감지 및 대응 효과 입증
- 무작위 손실 가중치(random loss weighting) 적용 시 안정적인 성능 유지 → 방법의 견고성 입증
- Gradient Manipulation 방법과 결합 효과 분석: