Adversarial Purification with Score-based Generative Models
While adversarial training is considered as a standard defense method against adversarial attacks for image classifiers, adversarial purification, which purifies attacked images into clean images with a standalone purification, model has shown promises as an alternative defense method. Recently, an EBM trained with MCMC has been highlighted as a purification model, where an attacked image is purified by running a long Markov-chain using the gradients of the EBM. Yet, the practicality of the adversarial purification using an EBM remains questionable because the number of MCMC steps required for such purification is too large. In this paper, we propose a novel adversarial purification method based on an EBM trained with DSM. We show that an EBM trained with DSM can quickly purify attacked images within a few steps. We further introduce a simple yet effective randomized purification scheme that injects random noises into images before purification. This process screens the adversarial perturbations imposed on images by the random noises and brings the images to the regime where the EBM can denoise well. We show that our purification method is robust against various attacks and demonstrate its state-of-the-art performances.
Problem:: 기존 적대적 정제 방법(EBM + MCMC)은 정제 과정에 1,000단계 이상의 긴 Markov 체인이 필요하여 실용성이 떨어짐/EBM이 제대로 학습되지 않으면 그레디언트가 부정확해 정제 성능이 하락함
Solution:: Stochastic Markov 체인 대신에 Score Function을 이용한 Deterministic Update로 정제 속도 향상/Adaptive Step Size로 초기 속도 및 정확도 향상/Denoising Score Matching으로 그레디언트를 직접 학습/정제 전에 적대적 공격보다 큰 랜덤 노이즈를 넣어서 적대적 공격을 Screening Out
Novelty:: 효율적인 결정론적 정제 과정과 랜덤 노이즈 주입을 통한 방어 성능 향상
Note:: Score의 Norm을 이용해서 적대적 공격 여부 감지 방식 제안
Summary
Motivation
- 적대적 공격(Adversarial Attack)은 사람이 인지할 수 없는 미세한 변화만으로도 딥러닝 이미지 분류기를 완전히 속일 수 있음
- 주요 방어 방법으로는 적대적 훈련(Adversarial Training)이 있으나, 이는 정확도에 영향을 줄 수 있음
- 적대적 정제(Adversarial Purification)는 분류기와 독립적으로 학습된 정제 모델로 공격 이미지에서 노이즈를 제거하는 접근법
- Energy-Based Model(EBM)은 데이터 분포를 잘 모델링할 수 있어 적대적 정제에 자연스러운 선택
- EBM은 이미지 공간에서 깨끗한 이미지에 낮은 에너지를, 비정상 이미지에 높은 에너지를 할당
- Langevin 동역학을 통해 높은 에너지 지점(공격받은 이미지)에서 낮은 에너지 지점(깨끗한 이미지)으로 이동 가능
- 그러나 Maximum-Likelihood with MCMC로 학습된 EBM은 심각한 한계가 있음
- 에너지 함수
를 직접 학습하는 방식으로, 그래디언트 는 부산물로 얻어짐 - 학습이 완벽하지 않으면 에너지 함수가 정확해도 그래디언트가 부정확할 수 있음
- 실제 정제에 사용되는 것은 그래디언트이므로 정제 성능에 직접적 영향
- MCMC 기반 정제는 1,000단계 이상의 샘플링이 필요하여 실용성이 떨어짐
- 에너지 함수
Method
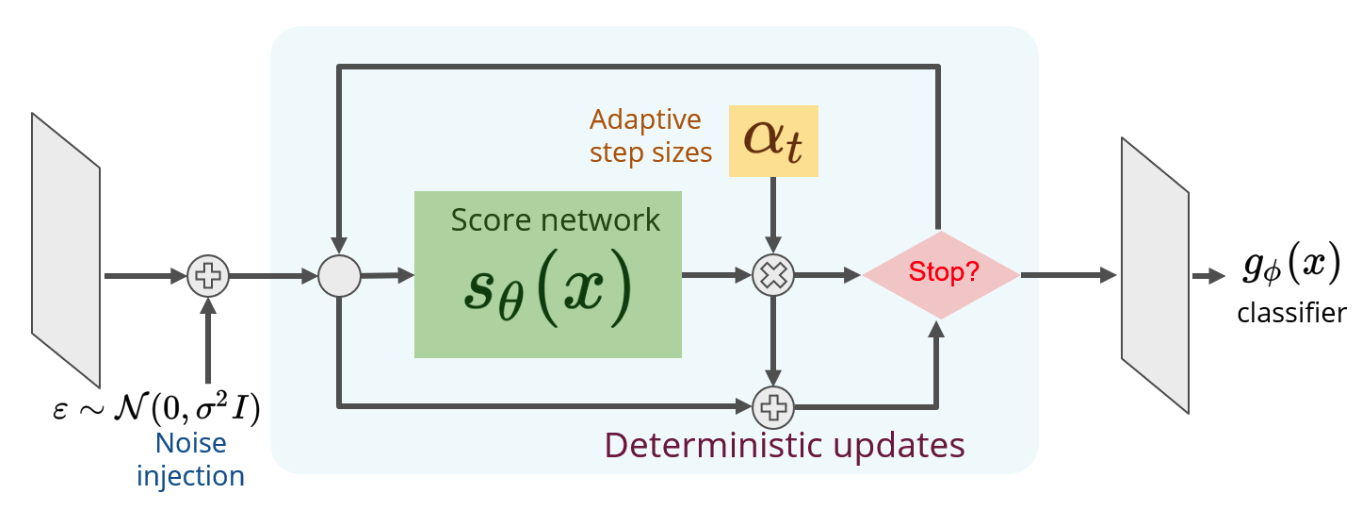
- Denoising Score-Matching(DSM)으로 학습된 EBM 사용
- DSM은 노이즈가 있는 이미지를 원본으로 복원하는 방향(Score Function)을 직접 학습
- SM은 고차원으로 확장 시킬 수 없는데, Perturbed Data의 경우 이게 가능해짐
- 이 과정에서
는 Perturbed 로부터 원본 를 복원하도록 학습됨 - 적대적 정제의 본질은 '노이즈 제거'이므로 DSM은 정제 작업에 더 직접적으로 연관됨
- 학습 목표:
→ Score Network 학습 - 이는 노이즈가 있는 이미지
에서 원본 이미지 로 복원하는 방향을 명시적으로 학습 - Noise Conditional Score Network(NCSN)를 사용해 여러 노이즈 레벨에서 학습해 다양한 공격에 대응 가능
- DSM은 노이즈가 있는 이미지를 원본으로 복원하는 방향(Score Function)을 직접 학습
- 결정론적 업데이트를 통한 정제
- 기존 MCMC 방법: 확률적 Langevin 동역학으로 마르코프 체인 실행 (
) - 제안 방법: 학습된 Score Network를 사용한 결정론적 업데이트 (
) - 랜덤성을 제거함으로써 수렴이 보장되지는 않지만 실험적으로 정제 속도가 크게 향상됨
- DSM은 직접 방향을 학습하므로 결정론적 업데이트와 특히 잘 작동
- 기존 MCMC 방법: 확률적 Langevin 동역학으로 마르코프 체인 실행 (
- 적응형 스텝 크기
조정 - 각 단계마다 최적의 스텝 크기 자동 계산
- 현재 이미지 주변에서 Score Function이 가우시안 분포의 Score와 유사하다는 가정
- 목표: 한 번의 업데이트 후 스코어 크기가 일정 비율(1-λ)만큼 감소하도록 함
- 수식:
- 초기에는 큰 스텝으로 빠르게 이동하고, 최적점에 가까워질수록 작은 스텝으로 정교하게 조정
- 정제 전 랜덤 노이즈 주입
- 이미지에 가우시안 노이즈를 추가한 후 정제 진행:
- 작은 적대적 교란
에 비해 상대적으로 큰 노이즈 이 교란을 가리는 "Screening Out" 효과 - DSM 학습에 사용된 노이즈 데이터와 유사한 입력 생성 → Score Network가 잘 작동하는 영역으로 이미지 이동
- Randomized Smoothing Classifier로 해석 가능 → 수학적 보증 제공
- 입력 데이터에 가우시안 노이즈(Gaussian noise)를 추가한 후, 여러 번의 예측 결과에서 가장 빈번한 클래스를 최종 예측으로 사용하는 분류기
- 여러 정제 실행 결과를 앙상블하여 최종 예측:
- 이미지에 가우시안 노이즈를 추가한 후 정제 진행:
Method 검증
- 모델 구성
- 분류기: WideResNet(depth 28, width factor 10), 36.5M 파라미터
- Score Network: NCSN, 29.7M 파라미터
- 정제 파라미터: 노이즈 표준편차
, 앙상블 수
- 전처리-블라인드 공격에 대한 방어: Gray-Box → Classifier 접근 가능, Purification 접근 불가능
- ADP(σ=0.25)는 86.14% 표준 정확도, 80.24% 견고한 정확도 달성 → 기존 정제 방법들보다 우수한 성능
- 노이즈 주입 정도(σ)와 표준/견고 정확도 간 트레이드오프 확인
- 강력한 적응형 공격에 대한 방어
- BPDA+EOT 공격에 대해 70.01%, Joint(full)+EOT에 대해 78.39% 정확도 달성 → 적대적 훈련 방법들보다 우수
- 랜덤 노이즈 주입(σ=0.25)은 SPSA 공격에 특히 효과적 (σ=0일 때 47.6%에서 80.80%로 향상) → 랜덤성이 그래디언트 추정 방해
- 인증된 견고성(Certified Robustness) 평가
- 랜덤화된 평활화 분류기로 해석 가능
- σ=0.12 노이즈 레벨에서 기존 방법보다 더 나은 인증된 정확도 → 효과적인 랜덤화 효과
- 일반 변형(Common Corruptions)에 대한 방어
- CIFAR-10-C 데이터셋에서 평가: 노이즈 변형에는 강하나 다른 변형에는 상대적으로 약함
- DCT, AugMix 등을 추가하여 성능 향상 → Score Network 학습 시 다양한 변형 고려 필요성
- CIFAR-100 데이터셋에서 BPDA 공격에 대해 39.72% 정확도 달성 → 기존 최고 성능(28.88%) 대비 큰 향상
- 적대적 예제 탐지 능력
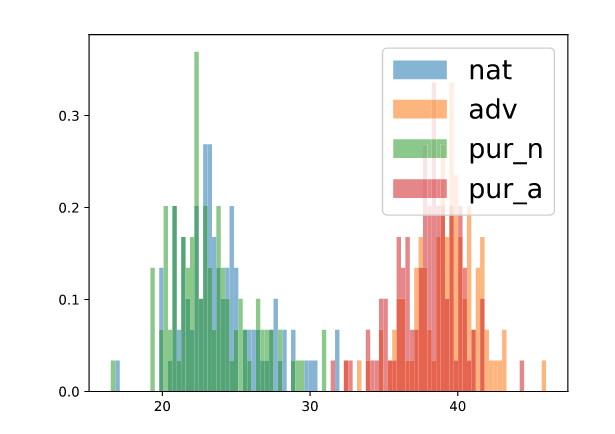
Natural, Adversarial 및 각 이미지의 Purified 된 이미지들의
.
- Score Network의 출력 노름 분포를 통해 자연/적대적 이미지 구분 가능 → 효과적인 탐지 메커니즘 제공