CLIP-Gaze: Towards General Gaze Estimation via Visual-Linguistic Model
Gaze estimation methods often experience significant performance degradation when evaluated across different domains, due to the domain gap between the testing and training data. Existing methods try to address this issue using various domain generalization approaches, but with little success because of the limited diversity of gaze datasets, such as appearance, wearable, and image quality. To overcome these limitations, we propose a novel framework called CLIP-Gaze that utilizes a pre-trained vision-language model to leverage its transferable knowledge. Our framework is the first to leverage the vision-and-language cross-modality approach for gaze estimation task. Specifically, we extract gaze-relevant feature by pushing it away from gaze-irrelevant features which can be flexibly constructed via language descriptions. To learn more suitable prompts, we propose a personalized context optimization method for text prompt tuning. Furthermore, we utilize the relationship among gaze samples to refine the distribution of gaze-relevant features, thereby improving the generalization capability of the gaze estimation model. Extensive experiments demonstrate the excellent performance of CLIP-Gaze over existing methods on four cross-domain evaluations.
Problem:: Gaze Estimation 모델의 Cross-Domain 성능 저하 / Gaze-Irrelevant Factor의 강한 영향력
Solution:: 언어 설명 기반 Gaze-Irrelevant Feature 생성 및 Gaze-Relevant Feature 와의 분리 / 개인화된 Prompt Tuning을 위한 Personalized Context Optimization (PCO) 제안 / 샘플 간 관계를 이용한 Feature 분포 개선을 위한 Feature Rank Loss 제안
Novelty:: Gaze Estimation 분야 최초의 Vision-Language Cross-Modality 접근법 적용
Note:: Gaze Estimation에 갑작스런 CLIP 사용 → 흥미로움 / PCO를 제안해서 당연히 떠오르는 Text Embedding으로만 Irrelevant Feature가 매칭 된다고? 라는 질문에 대답 / 연산량 많고 효과 좋은 Contrastive Regression Loss인 Feature Rank Loss
Summary
Motivation
- Appearance-Based Gaze Estimation 방법들은 동일 Domain 내에서는 높은 성능을 보이지만, 다른 Domain 데이터(예: 다른 사람, 다른 조명, 다른 카메라)에 대해서는 성능이 크게 저하되는 Domain Gap 문제를 겪음
- 얼굴 이미지에서 실제 Gaze 정보와 관련된 눈 영역은 매우 작은 부분을 차지하는 반면, 머리카락, 수염, 표정, 안경 착용, 조명 변화, 이미지 품질 저하 등 다양한 Gaze-Irrelevant Factor 들이 모델 예측에 큰 영향을 미침 → 이러한 Gaze-Irrelevant Factor들이 Domain Gap의 주요 원인이 되며, 모델의 일반화 성능을 저해함
- 기존 DG 연구들은 일부 Factor(Identity, Expression, Illumination 등)에 대한 강인성을 높이려 했으나, 모든 가능한 Factor 조합을 다루기 어렵고 주로 시각 정보에만 의존하여 한계가 있었음
- CLIP과 같은 VLM은 방대한 데이터로 학습되어 세상의 다양한 개념과 관계에 대한 폭넓은 이해를 가지고 있으며, 텍스트를 통해 정보를 유연하게 제어할 수 있어 Gaze-Irrelevant Factor를 효과적으로 다루는 데 적합할 것으로 기대됨
Method
CLIP-Gaze Framework
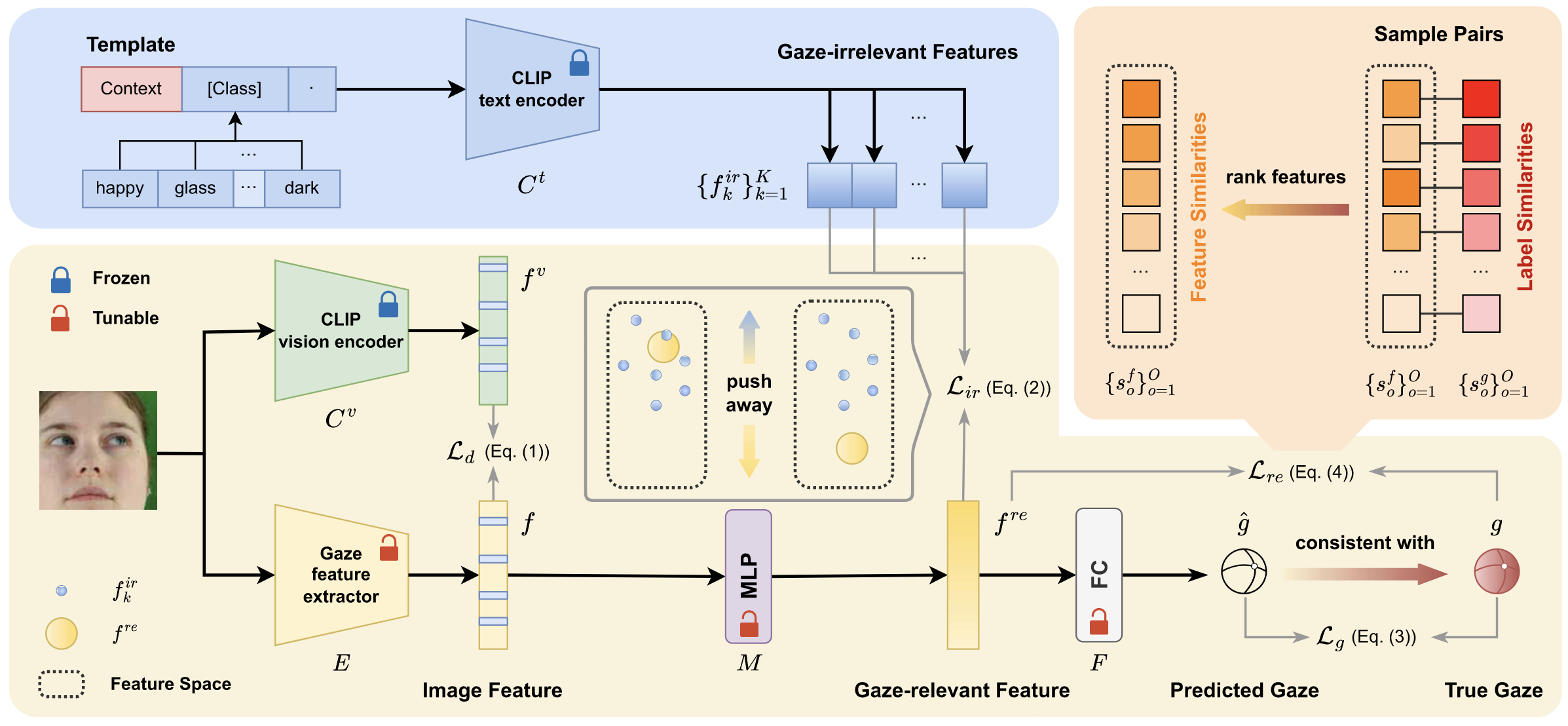
-
핵심 아이디어: 고정된 CLIP 모델을 활용하여 Gaze-Irrelevant Feature를 정의 및 생성하고, 학습 가능한 Gaze Model이 Gaze-Relevant Feature를 이와 분리하여 추출하도록 유도
-
구성 요소:
- CLIP Model (Fixed):
- Vision Encoder (
): 입력 이미지에서 Image Feature 추출 - Text Encoder (
): Text Prompt로부터 Gaze-Irrelevant Feature 생성
- Vision Encoder (
- Gaze Model (Trainable):
- Feature Extractor (E, ResNet-18): 이미지에서 Feature
추출 - Feature Filter (M, MLP):
에서 Gaze-Relevant Feature 분리 - Prediction Layer (F, FC):
로부터 최종 Gaze 예측
- Feature Extractor (E, ResNet-18): 이미지에서 Feature
- CLIP Model (Fixed):
-
Gaze-Irrelevant Factor: Gaze Estimation에 방해가 되는 요인들을 Appearance (A), Wearable (W), Image Quality (Q) 세 가지 차원으로 나누어 포괄적으로 정의함
- Gaze-Irrelevant Feature: "An image of a face with
" 형태의 Prompt Template에 각 Factor 를 넣어 를 통해 생성
- Gaze-Irrelevant Feature: "An image of a face with
-
최종적으로 네 가지 Loss를 조합하여 Gaze Model 학습:
Learning Robust Gaze Representation
핵심 아이디어: Gaze Feature Extractor와 Clip Vision Encoder의 Feature를 Align → MLP 하나 통과시킨 다음 Gaze Irrelevant Text Feature와 멀어지게함
-
Distill to CLIP Feature Space (
): Gaze Model의 Feature 를 CLIP의 와 유사하게 만들어 CLIP의 풍부한 Feature Space로 정렬 -
Separate Gaze-relevant Feature (
): 학습 대상인 를 고정된 와 최대한 멀어지게 (유사도를 낮추게) 하여 Gaze-Irrelevant 정보를 제거. 각 샘플과 -번째 Factor 간의 연관도 를 계산하여 관련 없는 Factor의 영향을 줄임 (여기서
, ) -
Gaze Estimation (
): Angular Error를 사용하여 예측 Gaze 와 실제 Gaze 의 차이를 최소화
Improvements
-
Personalized Context Optimization (PCO): 아까 정의한 "An image of a face with glass"는 Gaze Irrelevant라고 하기에 모자라서 개선
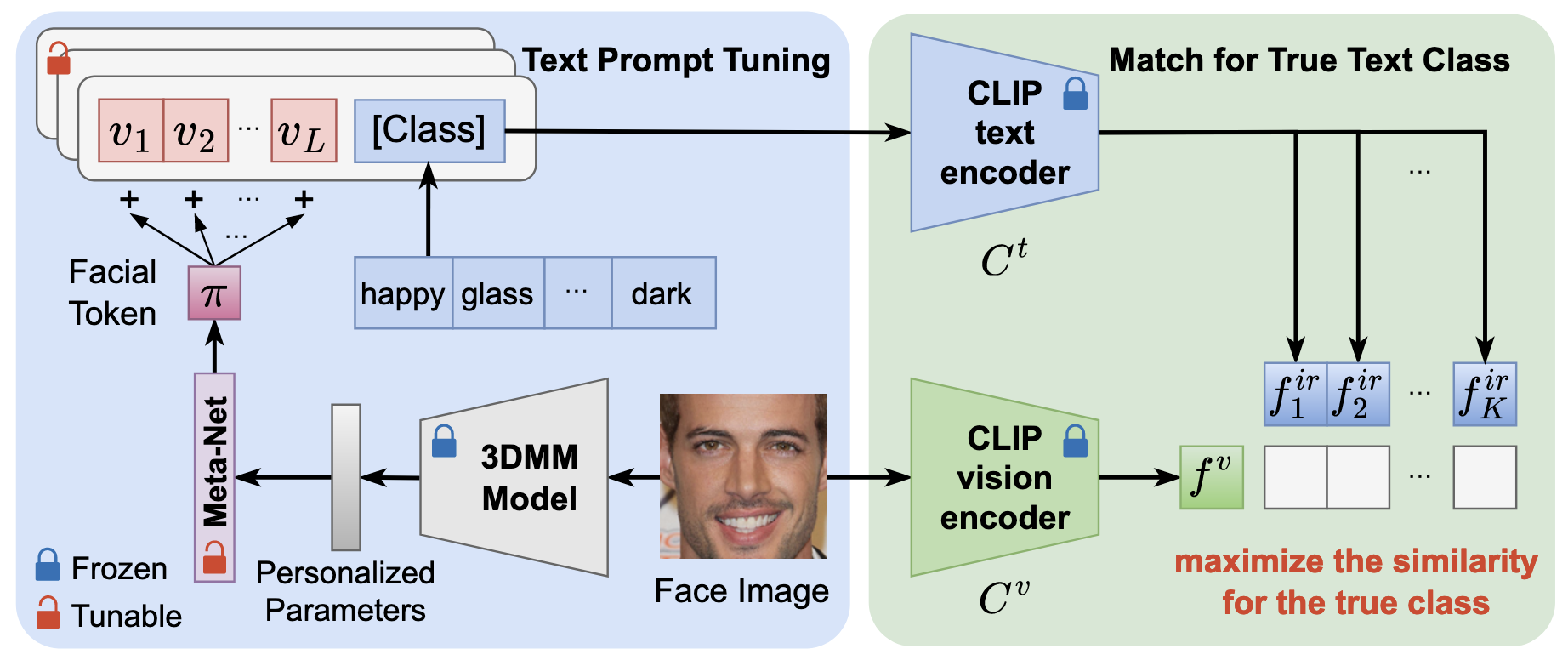
-
목적: Prompt Engineering의 어려움을 해소하고, 각 개인(Identity)에게 맞는 더 적합한 Text Prompt를 학습하여 정확한
를 생성하기 위함 -
학습: Face Attribute Classification을 Proxy Task로 사용. 3DMM에서 추출한 개인별 Identity Feature(
)를 Meta-Net에 입력하여 Input-Conditional Token( )을 생성하고, 이를 기존 Context Vector에 더해 개인화된 Prompt 를 만듦. Positive/Negative Prompt Feature( )와 Image Feature( ) 간의 유사도를 이용한 분류 손실 함수( 최대화)로 학습 → 얼굴 Attribute 뽑는 모델(3DMM) Feature로 개인화된 특징 얻은 다음, 이걸 토큰화(Meta-Net)해서 Learnable Token( )에 더한 다음 학습하면 Text Feature가 더 Gaze Relevant 해지겠지?
-
-
Feature Rank Loss (
): Contrastive Supervision 좋아보이는데, Regression에 맞게 수정해서 쓸게 -
목적: 개별 샘플 학습의 한계를 넘어, 샘플 간의 관계를 활용하여
의 분포를 실제 Gaze Label( )의 분포와 유사하게 정렬함으로써 Feature의 Robustness 향상 -
방법: 샘플 쌍
에 대해 Label Similarity ( )와 Feature Similarity ( )를 계산. 모든 쌍을 기준으로 정렬했을 때, 의 순서도 동일하게 유지되도록 Ranking Loss 적용. 는 Feature Similarity에 대해 이면 1, 아니면 -1
-
Method 검증
실험 설정
- Datasets: ETH-XGaze(
), Gaze360( )에서 학습, MPIIFaceGaze( ), EyeDiap( )에서 테스트 - Tasks: 4개 Cross-Domain Tasks (
, , , ) - Comparison Methods: Baseline, DG Methods(CDG, PureGaze, Xu et al), UDA Methods 등
실험 결과
- SOTA Comparison
- 실험: 4개 Cross-Domain Task에서 Angular Error 비교
- 결과: CLIP-Gaze (PCO +
)가 **평균 6.97°**로 모든 DG 방법 중 최고 성능 달성 (Baseline 8.65°, Xu et al 7.63°). 3개 Task에서 SOTA. Target Domain 정보 없이도 다수 UDA 방법보다 우수 - 통찰: CLIP 기반 접근법, PCO, Feature Rank Loss가 Cross-Domain 일반화 성능 향상에 매우 효과적임
- **Ablation Study: Text Prompt Tuning:
- 실험: TPT 방법 변경에 따른 성능 비교
- 겱과: PCO(6.97°) 가 w/o TPT(7.40°), CoOp(7.36°), CoCoOp(7.81°) 등 다른 방법보다 월등히 우수
- 통찰: Identity 정보를 활용한 개인화된 Prompt 생성이 Gaze-Irrelevant Feature 정의에 더 효과적임
- Ablation Study: Attributes and Conditions:
- 실험: Gaze-Irrelevant Factor 조합 변경에 따른 성능 비교
- 겱과: 단일 그룹보다 여러 그룹 조합 시 성능 향상. 모든 Factor(A+W+Q) 조합 시 최적 성능(6.97°)
- 통찰: 다양한 종류의 Gaze-Irrelevant Factor를 종합적으로 고려하는 것이 중요함
- **Ablation Study: Loss Functions:
- 실험: 제안된 Loss Term(
)의 효과 검증 - 겱과:
추가(8.38°), 추가(7.37°) 시 점진적 성능 향상. 추가 시 최종 6.97° 달성. 는 CRLoss(7.34°)나 다른 Ranking 변형보다 우수 - 통찰: CLIP Space 정렬(
), Irrelevant Feature 분리( ), Feature Rank Loss( ) 모두 효과적이며, 특히 가 Feature 분포 개선에 크게 기여함
- 실험: 제안된 Loss Term(
- Feature Visualization:
- 실험: T-SNE로 Gaze-Relevant Feature 분포 시각화
- 결과: Baseline은 Feature 혼재.
은 일부 개선. CLIP-Gaze( )는 Gaze 방향에 따라 Feature가 매우 잘 정렬된 합리적인 분포를 보임 - 통찰: Feature Rank Loss가 Feature 분포를 Gaze Label 관계에 맞게 효과적으로 구조화함을 시각적으로 확인