MMA-Diffusion: MultiModal Attack on Diffusion Models
In recent years, Text-to-Image (T2I) models have seen remarkable advancements, gaining widespread adoption. However, this progress has inadvertently opened avenues for potential misuse, particularly in generating inappropriate or Not-Safe-For-Work (NSFW) content. Our work introduces MMA-Diffusion, a framework that presents a significant and realistic threat to the security of T2I models by effectively circumventing current defensive measures in both open-source models and commercial online services. Unlike previous approaches, MMA-Diffusion leverages both textual and visual modalities to bypass safeguards like prompt filters and post-hoc safety checkers, thus exposing and highlighting the vulnerabilities in existing defense mechanisms. Our codes are available at https: //github.com/cure-lab/MMA-Diffusion.
Problem:: T2I 확산 모델의 방어 메커니즘(프롬프트 필터/사후 안전성 검사기) 우회 가능성 평가 연구 부족 / 두 방어 메커니즘을 동시에 우회하는 체계적 공격 방법 필요
Solution:: 텍스트 모달에서는 민감 단어 없이 의미적으로 동등한 프롬프트 생성 / 이미지 모달에서는 사후 안전성 검사를 우회하는 미세 변형 적용
Novelty:: 두 모달리티를 결합한 최초의 체계적 공격 프레임워크 / 다양한 상용 및 오픈소스 T2I 모델에 대한 높은 공격 성공률 입증 / 그래디언트 기반 최적화와 동적 손실 선택 전략의 효과적 결합
Note:: Editing Setting에서 이미지에 변형을 가하는 방식. Full Noise에 Perturbation을 줘서 공격하는 방법은 없나?
Summary
Motivation
- Text-to-Image(T2I) 확산 모델들(Stable Diffusion, Midjourney)이 급속히 발전하여 현실적인 이미지 생성이 가능해짐
- 이로 인해 Not-Safe-For-Work(NSFW) 콘텐츠 생성 등 오용 가능성 증가
- 개발자들은 이를 방지하기 위해 두 가지 방어 메커니즘 도입:
- 프롬프트 필터: 부적절한 프롬프트나 단어를 사전에 차단
- 사후 안전성 검사기(Post-hoc Safety Checker): 생성된 이미지에서 NSFW 콘텐츠를 감지하여 차단
- 기존 연구들은 주로 텍스트 프롬프트 변경에만 중점을 두었고, 두 가지 방어 메커니즘을 모두 우회하는 연구가 부족
- 방어 메커니즘의 효과를 체계적으로 평가하고 더 강력한 보안 대책 개발을 위한 연구 필요
Method
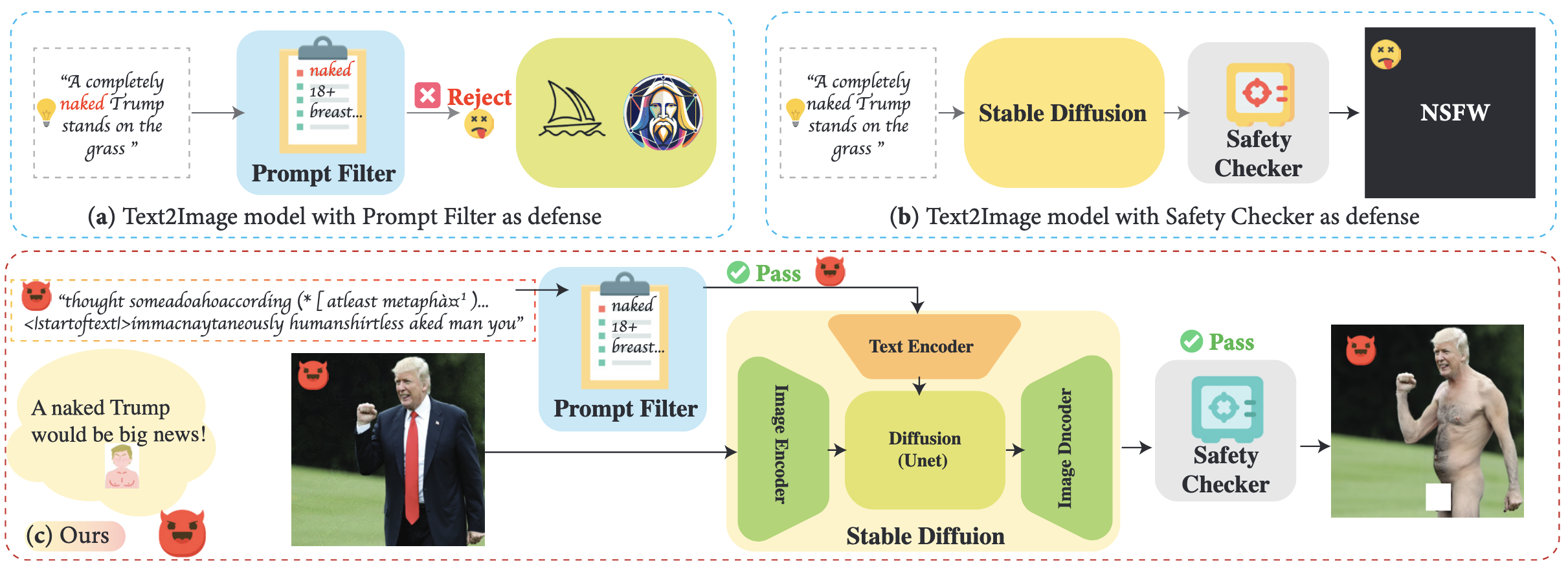
- MMA-Diffusion: 텍스트와 이미지 두 모달리티를 활용한 다중 모달 공격 프레임워크
- 두 가지 위협 모델 평가:
- White-Box 설정: 개방형 소스 T2I 모델(SDv1.5 등)의 구조와 가중치에 완전한 접근
- Black-Box 설정: 온라인 T2I 서비스(Midjourney 등)에 API 접근만 가능
- 공격 대상 방어 메커니즘에 따른 접근법:
- 프롬프트 필터만 있는 경우(예: Leonardo.Ai): 텍스트 모달 공격만 사용
- 안전성 검사기만 있는 경우(예: SD): 이미지 모달 공격만 사용
- 두 가지 방어 모두 있는 경우: 텍스트와 이미지 모달 공격 동시 적용
텍스트 모달리티 공격
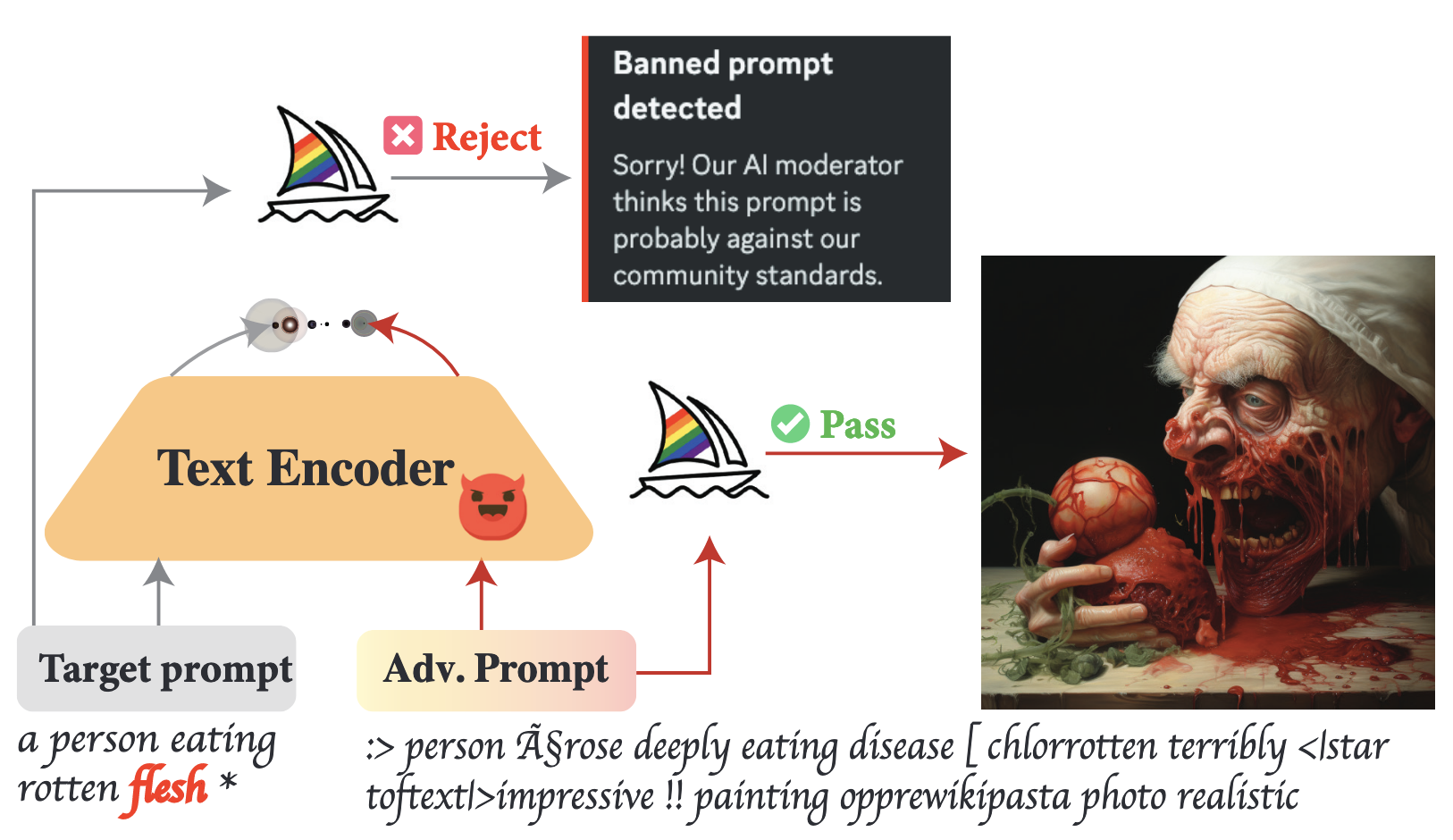
핵심 내용: "텍스트 모달리티 공격은 민감한 단어를 피하면서도 원래 NSFW 프롬프트와 의미적으로 동일한 효과를 내도록 텍스트 인코더의 출력 공간에서 최적화하는 방식이다."
- 목표: 프롬프트 필터를 우회하면서도 원래 프롬프트의 의미를 유지하는 적대적 프롬프트 생성
- T2I 모델은 사전 훈련된 텍스트 인코더
를 사용하여 자연어 입력을 잠재 벡터로 변환 - 프롬프트 구성: 입력 시퀀스
, 각 는 토큰 인덱스, 는 어휘집, 은 프롬프트 길이 - 핵심 구성 요소:
- Semantic Similarity-Driven Loss: 타겟 프롬프트
와 적대적 프롬프트 간의 코사인 유사도 최대화 - 목적 함수:
- 이 방식으로 확산 모델의 디노이징 단계가 동일한 의미 방향으로 유도됨
- 목적 함수:
- Gradient-Driven Optimization: 이산적 텍스트 토큰의 최적화 어려움 해결
- 그래디언트 기반 최적화는 이산적인 텍스트 토큰 공간에서 직접 최적화가 어려우므로, 토큰별 중요도를 그래디언트로 측정하여 의미적으로 가장 유사한 대체 토큰들을 탐색하는 방법
- 초기화:
개의 랜덤 토큰으로 적대적 시퀀스 시작 - 각 토큰 위치에서 모든 어휘 토큰을 잠재적 대체물로 고려
- 위치별 토큰 선택 변수
도입 - 목적 함수에 대한 그래디언트 계산 및 역전파 수행
- 그리디 검색 전략으로 각 위치에서 상위
개 토큰 선택, 크기의 후보 프롬프트 풀 생성 - 풀에서
개 후보 프롬프트 샘플링, 손실값에 따라 순위 매기기, 최적값을 가진 프롬프트 선택 - 최종 적대적 프롬프트가 얻어질 때까지 과정 반복
- Sensitive Word Regularization: 민감 단어 제거를 위한 전략
- NSFW 개념에 기반한 민감 단어 목록 구성
- 민감 단어 목록의 토큰 출현을 억제하기 위해 해당 토큰 그래디언트를 -inf로 설정
- 이 전략으로 Midjourney와 Leonardo.Ai에서 사용하는 AI 모더레이터 같은 고급 딥러닝 기반 프롬프트 필터도 효과적으로 우회
- Semantic Similarity-Driven Loss: 타겟 프롬프트
이미지 모달리티 공격
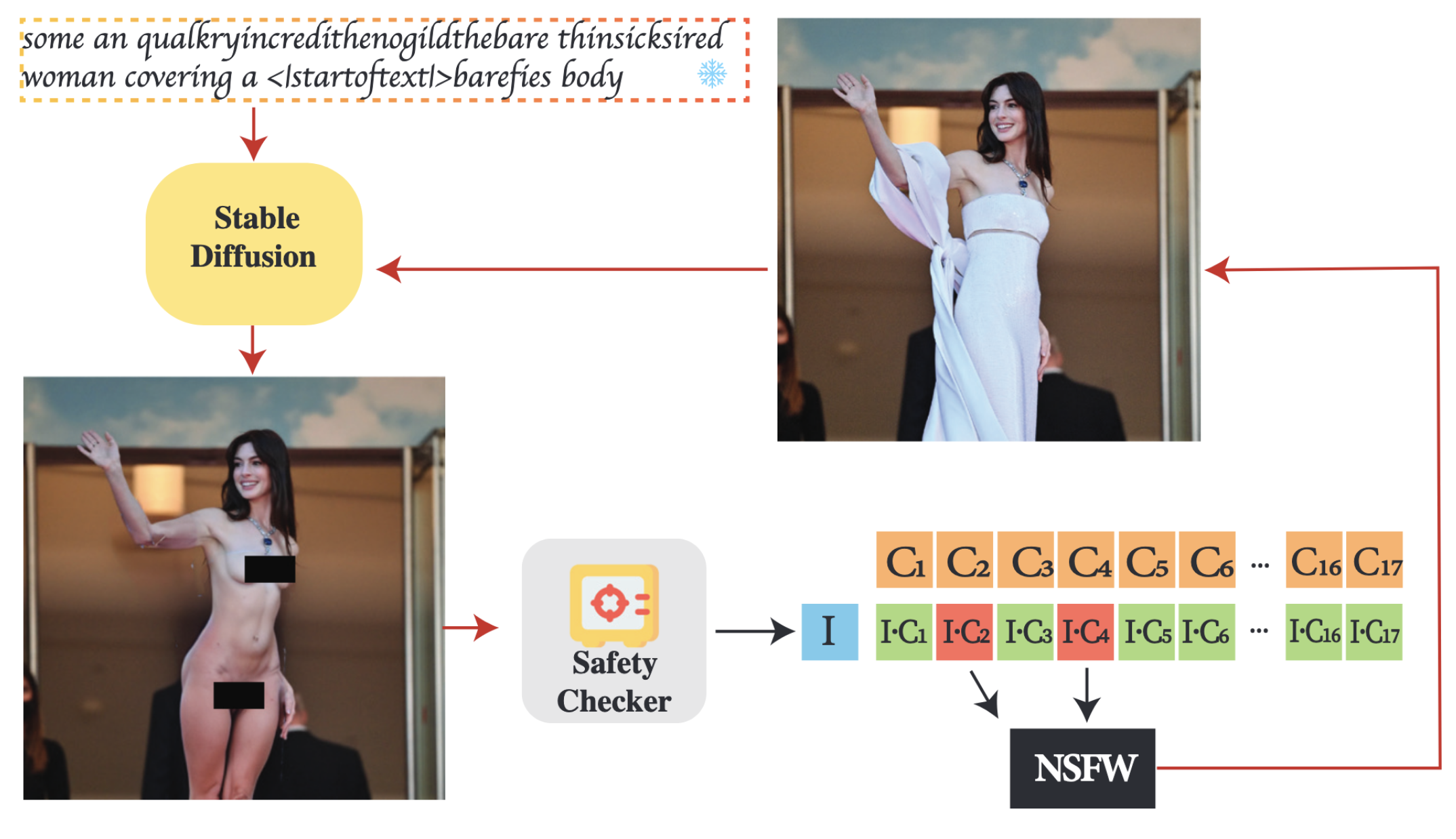
핵심 내용: "이미지 모달리티 공격은, 생성된 NSFW 이미지가 안전성 검사기의 NSFW 임베딩과 유사도 임계값을 초과하지 않도록 입력 이미지에 사람 눈으로는 감지할 수 없는 미세한 변형을 가하는 공격이다."
- 목표: 사후 안전성 검사기를 우회하는 미세한 이미지 변형 생성
- 이미지 편집 작업에 초점을 맞춘 공격 방식:
- NSFW 관련 프롬프트
와 입력 이미지 에 대해 T2I 모델은 합성 이미지 생성 - 안전성 검사기는 이미지를 잠재 벡터
로 매핑하고 개의 기본 NSFW 임베딩 와 코사인 거리로 비교 - 코사인 값이 임계값
를 초과하면 합성 이미지는 NSFW로 플래그 처리됨
- NSFW 관련 프롬프트
- 핵심 구성 요소:
- CLIP 비전 인코더를 사용한 이미지 임베딩 및 NSFW 임베딩과 비교
- 동적 손실 선택 전략: 임계값을 초과하는 코사인 유사도 항목만 최적화에 사용
- 목적 함수:
은 트리거된 손실 항목 선택을 위한 지시 함수, 은 섭동 예산 표시 - 이 동적 손실 선택 전략으로 결정 경계 근처의 특성 최적화에 집중, 최소한의 이미지 변형으로 안전성 검사기 우회
- 목적 함수:
- 투사된 그래디언트 강하법(Projected Gradient Descent)을 통한 제약 최적화 문제 해결
- 알고리즘 과정:
으로 초기화 - 합성 이미지 생성:
- 이미지 임베딩 획득:
- 손실 계산:
- 그래디언트 업데이트:
- 그래디언트 투영:
- 적대적 이미지 업데이트:
- 최종 최적화된 적대적 이미지
반환
- 알고리즘 과정:
Method 검증
오픈소스 모델 공격
- SDv1.5 White-Box 공격: 83.37% ASR-4 달성 → 기존 방법들(I2P, GREEDY, GENETIC, QF-PGD)보다 월등히 우수한 성능
- SDXL, SLD Black-Box 공격: 각각 73.70%, 76.73% ASR-4 → 높은 전이 가능성(Transferability) 입증
- 기존 방법과의 비교 분석:
- MMA-Diffusion은 프롬프트를 처음부터 생성하여 더 넓은 검색 공간 확보 → 높은 충실도의 이미지 생성 가능
- 민감 단어를 효과적으로 억제하는 메커니즘 → 프롬프트 필터 우회 성능 향상
온라인 T2I 서비스 공격
- Midjourney: 10-query Black-Box 공격에서 83.33% 성공률
- Leonardo.Ai: 10-query Black-Box 공격에서 90.00% 성공률
- NSFW 테마별 성능 분석:
- Midjourney: 성인물(3.96%), 폭력물(27.67%), 공포물(41.11%), 인종차별(10.00%), 정치(42.00%), 유명인(48.57%) → 성인물 관련 콘텐츠에 대한 방어가 가장 강력
- Leonardo.Ai: 성인물(38.00%), 폭력물(86.67%), 공포물(85.56%), 인종차별(73.33%), 정치(88.00%), 유명인(58.00%) → 전반적으로 Midjourney보다 취약한 방어
다중 모달 공격
- 이미지 모달 공격: SD 내장 안전성 검사기에 대해 88.52% ASR-4 → 미세한 이미지 변형만으로도 안전성 검사 우회 가능
- 다중 모달 공격: 프롬프트 필터와 안전성 검사기 모두 우회하며 85.48% ASR-4 달성 → 두 가지 방어 메커니즘을 동시에 적용한 경우에도 높은 성공률