Gaze Target Detection by Merging Human Attention and Activity Cues
Despite achieving impressive performance, current methods for detecting gaze targets, which depend on visual saliency and spatial scene geometry, continue to face challenges when it comes to detecting gaze targets within intricate image backgrounds. One of the primary reasons for this lies in the oversight of the intricate connection between human attention and activity cues. In this study, we introduce an innovative approach that amalgamates the visual saliency detection with the body-part & object interaction both guided by the soft gaze attention. This fusion enables precise and dependable detection of gaze targets amidst intricate image backgrounds. Our approach attains state-of-the-art performance on both the Gazefollow benchmark and the GazeVideoAttn benchmark. In comparison to recent methods that rely on intricate 3D reconstruction of a single input image, our approach, which solely leverages 2D image information, still exhibits a substantial lead across all evaluation metrics, positioning it closer to human-level performance. These outcomes underscore the potent effectiveness of our proposed method in the gaze target detection task.
Problem:: 인간의 주의(Attention)와 활동(Activity) 단서 간 연결 관계 고려 부족/얼굴 가시성 제한 상황에서 견고성 부족
Solution:: 5개 신체 부위와 객체 간 상호작용을 학습에 도입하여 Activity와의 연결성 확보/얼굴의 키 포인트를 추출하여 가시성 제한 상황에서 견고성 확보
Novelty:: 인간 주의와 활동 단서를 시선 목표 감지에 통합한 최초 연구/얼굴과 5개 머리 키포인트를 활용한 견고한 시선 주의 메커니즘
Note:: Pretrained 모델(Pose, Object Detection)이 요구됨/자기들 마음대로 AUROC 성능 지표 제거함/2024년도 연구인데 그 이전에 나온 SOTA 연구들 다 성능 비교표에서 제거함 → 이딴게 AAAI?/얼굴이 제대로 나오지 않는 경우에도 동작 → 사실 얼굴은 크게 중요하지 않을지도?
Summary
Motivation
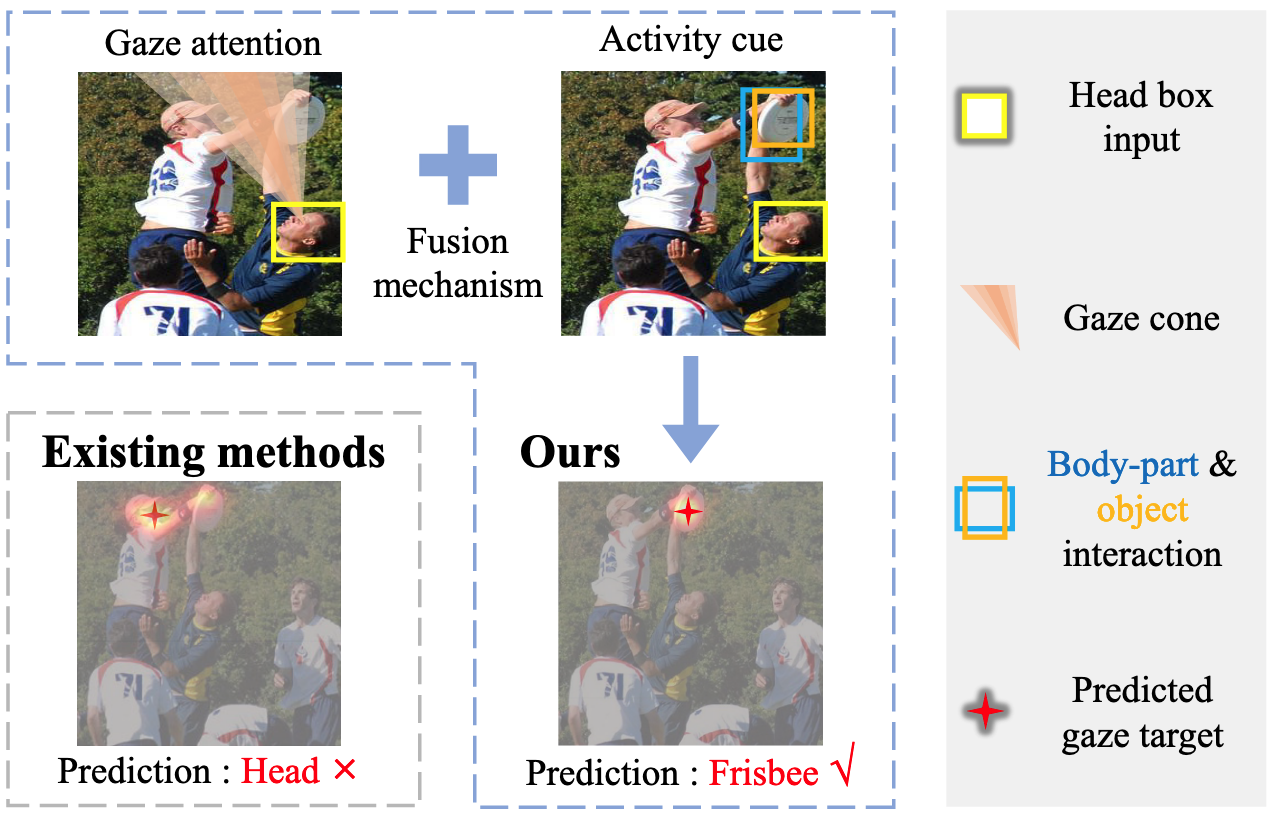
- 기존 시선 목표 감지 방법들은 시선 방향을 따라 시각적 현저성(Visual Saliency)을 감지하는 방식에 의존
- 최근에는 단안 깊이 추정(Monocular Depth Estimation)과 3D 기하학적 구조를 활용한 방법들이 개발됨
- 하지만 복잡한 이미지 배경에서 정확하고 신뢰할 수 있는 시선 목표 감지에 여전히 어려움 존재
- 주요 한계점: 인간의 주의(Human Attention)와 활동 단서(Activity Cues) 간의 복잡한 연결관계 고려 부족
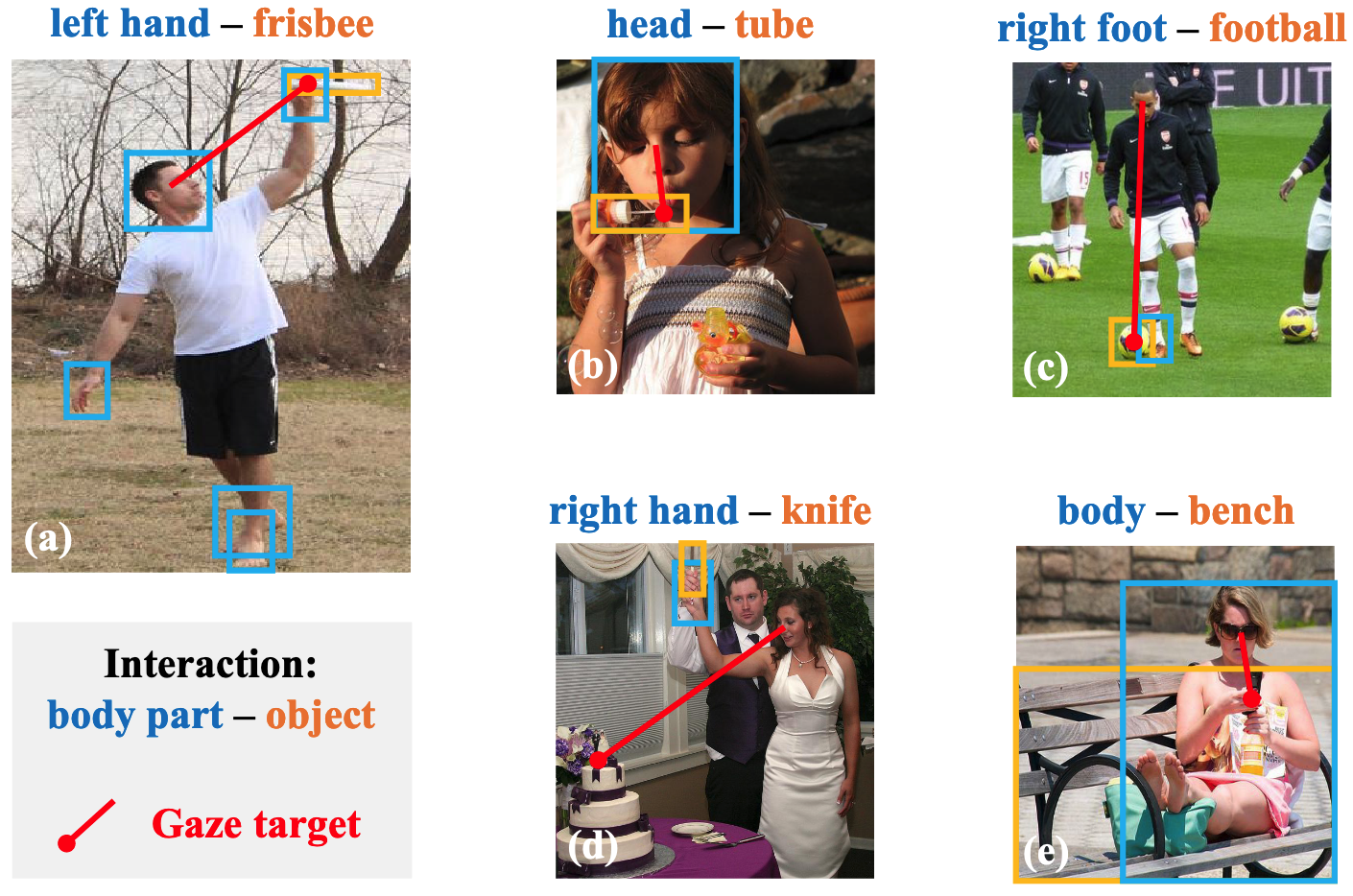
- 사람들이 특정 활동에 참여할 때 시선은 대개 상호작용하는 물체에 집중되지만(1행), 상호작용하지 않는 물체를 바라보거나 아예 보지 않을 수 있음(2행) → 하지만 시선이 행동과 관련 있는것은 명백하므로 학습에 이용
Method
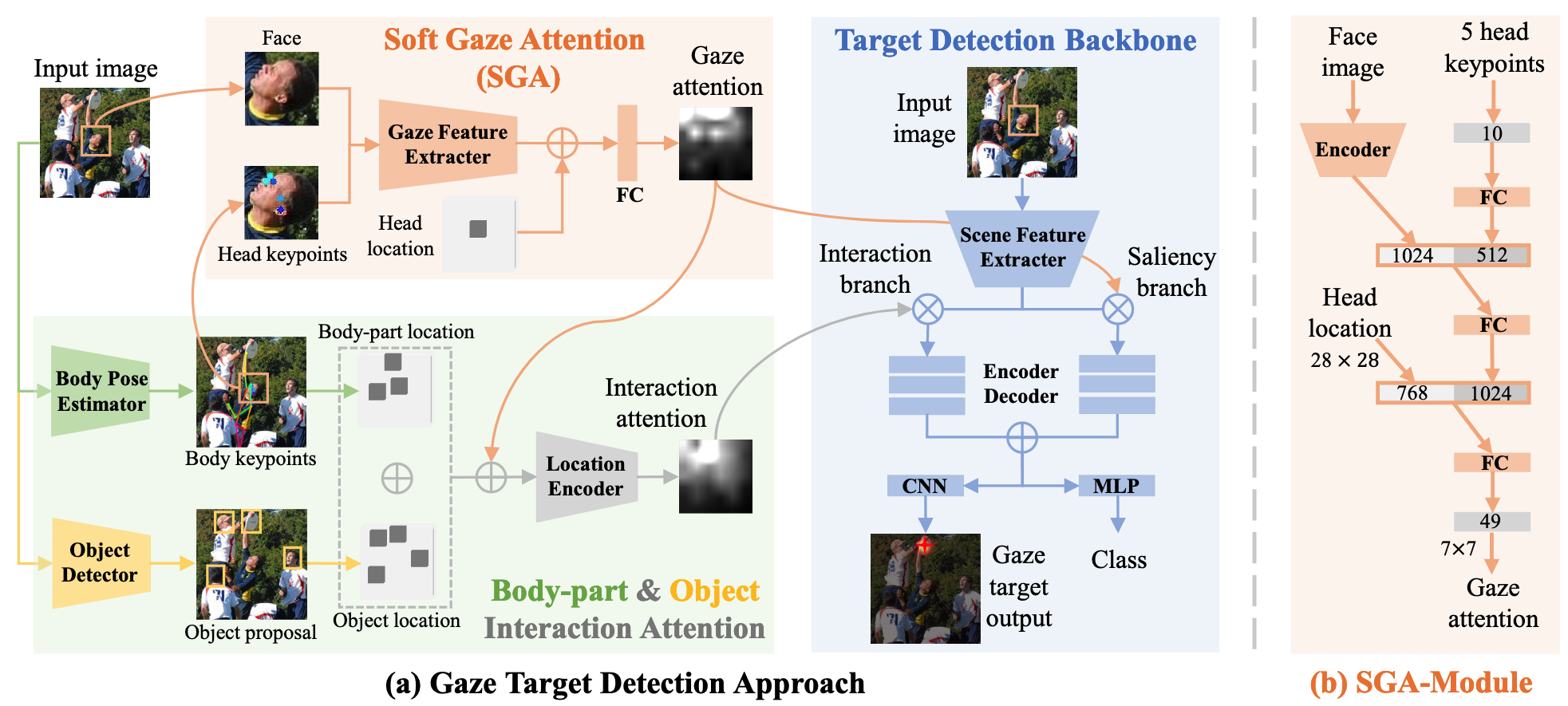
- 본 연구는 Soft Gaze Attention, Body-part & Object Interaction Attention, Target Detection Backbone 세 가지 주요 모듈로 구성
- Soft Gaze Attention: MobileNet으로 얼굴 특징 추출, 5개 머리 키포인트(코, 눈, 귀)와 함께 처리하여 시선 주의 맵(
) 생성 - 얼굴 이미지에서 추출된 벡터(
)와 머리 키포인트 벡터( ) 연결 후 FC 레이어 통과 - 머리 위치 맵(
)을 인코딩한 벡터( )와 함께 처리하여 7×7 시선 주의 맵 생성
- 얼굴 이미지에서 추출된 벡터(
- Body-part & Object Interaction Attention: 사전 학습된 포즈 추정기(RTMPose)와 객체 감지기(YOLOv3) 활용
- 5개 신체 부위(머리, 손, 발) 위치 맵(
)과 객체 위치 맵( )을 연결 - 시선 주의 맵(
)과 함께 처리하여 상호작용 주의 맵( ) 생성
- 5개 신체 부위(머리, 손, 발) 위치 맵(
- Target Detection Backbone: ResNet-50 기반 특징 추출, Saliency Branch와 Interaction Branch로 구성
- 머리 위치 맵과 장면 이미지 연결 후 ResNet-50으로 특징 추출
- Saliency Branch는 시선 주의(
)로 가이드되어 현저성 히트맵( ) 생성 - Interaction Branch는 상호작용 주의(
)로 가이드되어 상호작용 히트맵( ) 생성 - 두 히트맵 결합 후 CNN과 MLP로 최종 시선 목표 예측 및 프레임 밖 여부 판단
- 손실 함수: Saliency Branch 손실(
), 융합 예측 손실( ), 분류 손실( )의 가중 합 에 대한 정답값은 존재하지 않아 따로 손실 함수가 없음
Method 검증
- GazeFollow 데이터셋 성능 평가: 기존 모델들과 비교 실험
- 최소 L2 거리에서 20.8%, 평균 L2 거리에서 13.9% 성능 향상 → Baseline 대비 복잡한 배경에서도 시선 목표 감지 능력 향상
- 3D 재구성 기반 최신 방법(Bao)과 비교해도 평균 L2 거리에서 3.3% 향상 → 2D 정보만으로도 3D 방법보다 우수한 성능 달성
- VideoAttentionTarget 데이터셋 성능 평가: 프레임 밖 시나리오 검증
- Body-part & Object Interaction 모듈 없이도 L2 거리에서 20.9%, AP에서 7.3% 향상 → Soft Gaze Attention 모듈의 독립적 효과성 입증
- 정성적 분석: 복잡한 배경 속 소형 객체 감지 능력 평가
- 실제 시선 목표가 복잡한 배경에 숨겨진 작은 객체일 때 Baseline보다 우수한 성능 → Human Attention과 Activity Cues 융합의 효과 확인

얼굴이 제대로 보이지 않거나 이미지 변형으로 인해 인식이 제대로 되지 않는경우 실험
- Soft Gaze Attention 모듈 분석: 얼굴 가시성이 제한된 상황 실험
- 기존 얼굴 기반 시선 추정 방법 대비 더 높은 정확도 → 머리 키포인트와 얼굴 방향 간 공간적 상관관계 활용의 효과 입증
- Interaction Branch 분석: 다양한 모듈 구성 실험
- 특정 신체 부위-객체 상호작용 접근법이 전신-객체 상호작용보다 효과적 → 세분화된 신체 부위 활용의 중요성 확인
- 시선 주의를 상호작용 모듈에 주입 시 성능 향상 → 두 모듈 간 시너지 효과 입증
- 계산 복잡성 평가: 추론 속도 측정
- 경량 모델 활용으로 이미지당 처리 시간 75ms (DETR based Gaze Target Detection) 미만 → 실시간 응용 가능성 확보 및 경쟁 방법 대비 효율성 입증