AdaMerging: Adaptive Model Merging for Multi-Task Learning
Multi-task learning (MTL) aims to empower a model to tackle multiple tasks simultaneously. A recent development known as task arithmetic has revealed that several models, each fine-tuned for distinct tasks, can be directly merged into a single model to execute MTL without necessitating a retraining process using the initial training data. Nevertheless, this direct addition of models often leads to a significant deterioration in the overall performance of the merged model. This decline occurs due to potential conflicts and intricate correlations among the multiple tasks. Consequently, the challenge emerges of how to merge pre-trained models more effectively without using their original training data. This paper introduces an innovative technique called Adaptive Model Merging (AdaMerging). This approach aims to autonomously learn the coefficients for model merging, either in a task-wise or layer-wise manner, without relying on the original training data. Specifically, our AdaMerging method operates as an automatic, unsupervised task arithmetic scheme. It leverages entropy minimization on unlabeled test samples from the multi-task setup as a surrogate objective function to iteratively refine the merging coefficients of the multiple models. Our experimental findings across eight tasks demonstrate the efficacy of the AdaMerging scheme we put forth. Compared to the current state-of-the-art (SOTA) task arithmetic merging scheme, AdaMerging showcases a remarkable 11% improvement in performance. Notably, AdaMerging also exhibits superior generalization capabilities when applied to unseen downstream tasks. Furthermore, it displays a significantly enhanced robustness to data distribution shifts that may occur during the testing phase.
Problem:: Task Vector 기반 Multi-Task Learning에서 하나의 결합계수
Solution:: 레이어/태스크 별로 다른 결합 계수를 이용/Test-Time Adaptation으로 결합 계수 최적화
Novelty:: Entropy와 Training Loss간의 양의 상관관계를 발견 → Test-Time Adaptation을 위한 대리 목적 함수 Entropy 최적화 제안
Note:: 아마 최초로 레이어 및 태스크별로 다른 계수를 적용한 듯?
Summary
Motivation
- Multi-Task Learning(MTL)은 여러 작업을 동시에 처리하는 모델을 효율적으로 구현하기 위한 중요한 접근법
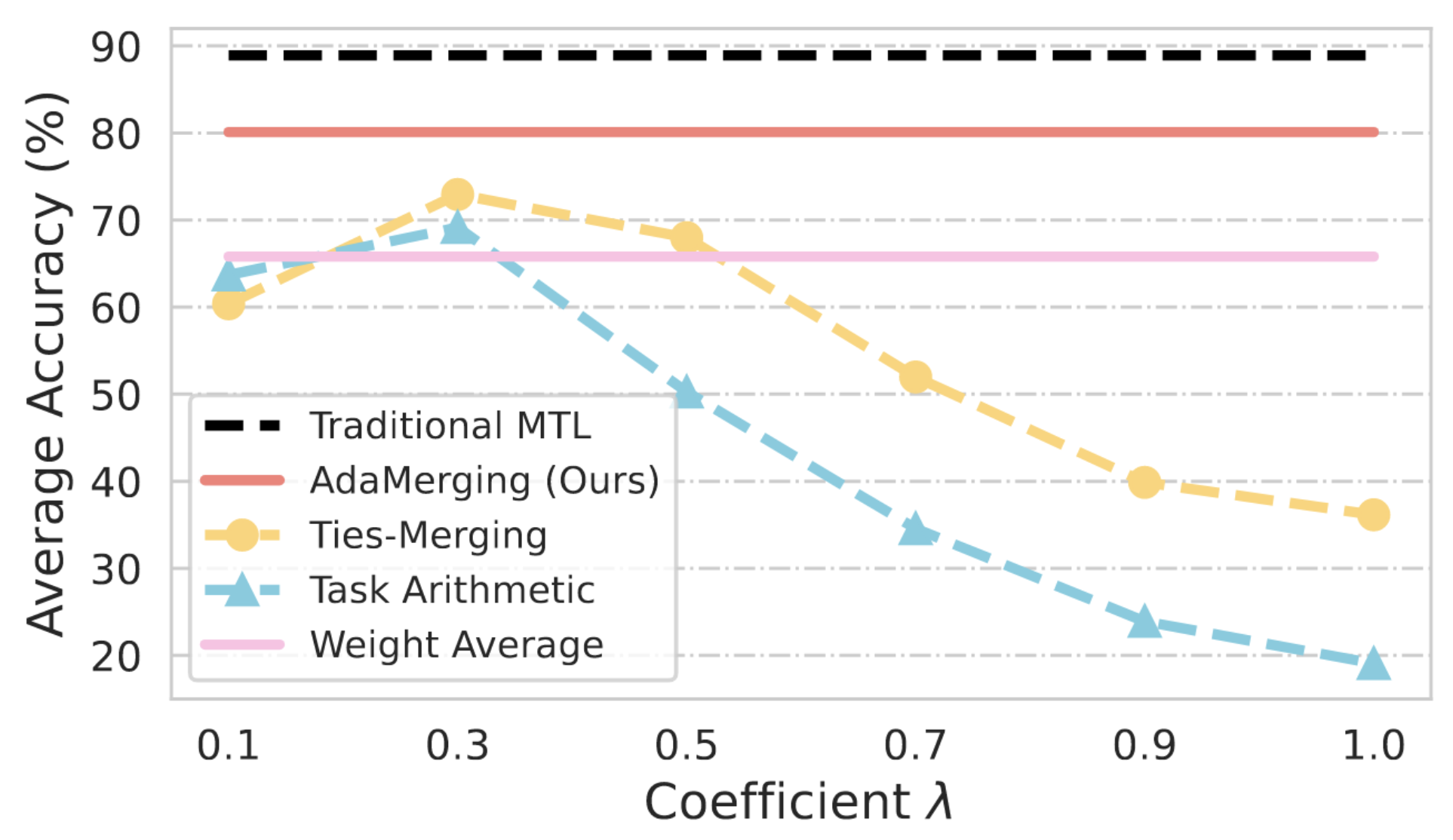
- 최근 Task Arithmetic 개념을 통해 각 Task에 맞게 Fine-tuning된 여러 모델을 직접 결합하여 MTL 수행 가능
- 그러나 단순한 모델 결합(Weight Average)은 Task 간 충돌과 복잡한 상관관계로 인해 심각한 성능 저하를 초래함
- [5-notes/PaperReview/ilharco2023editing|Task Vector]는 Pre-trained 모델 가중치(
)와 특정 Task에 Fine-tuning된 모델 가중치( )의 차이로 정의 - Task Arithmetic은 여러 Task Vector를 더하여 새로운 Multi-Task 모델 생성 → 기존 Task Arithmetic 방식은 **모든 Task에 동일한 가중치(
)를 적용 - 병합 계수(
)가 모델의 MTL 성능에 결정적 영향을 미침 → 값에 따른 심각한 성능 저하 발생 - 적절한
를 찾기 위해 원본 데이터가 요구됨 → 원본 학습 데이터 없이 Pre-trained 모델을 효과적으로 병합하는 방법 필요
- 적절한
Method
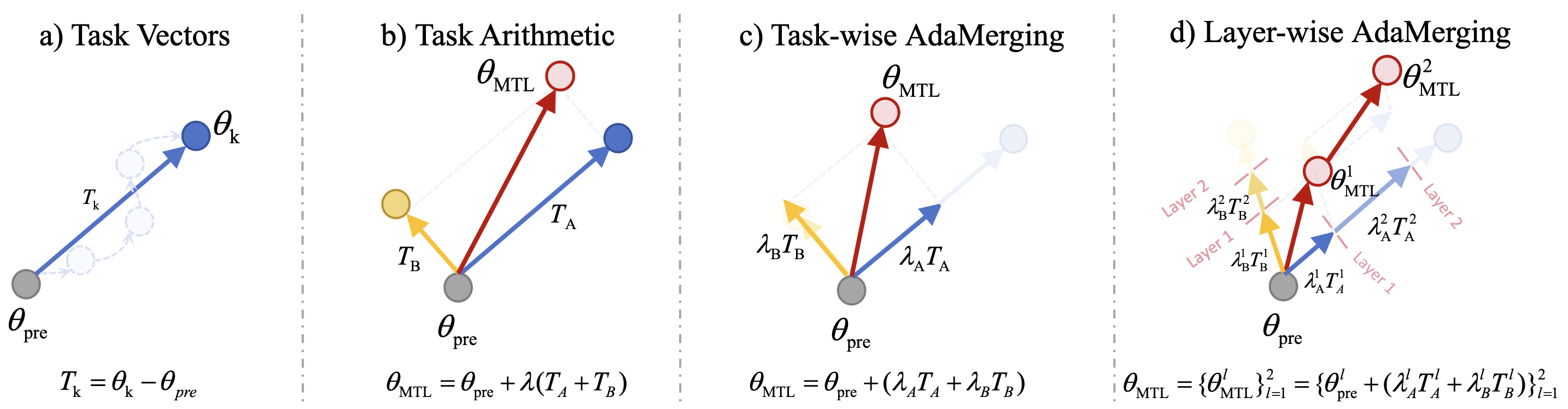
- AdaMerging은 세 가지 Variant를 제안
- Task-wise AdaMerging: 각 Task Vector별로 서로 다른 병합 계수(
) 학습 - Layer-wise AdaMerging: Task Vector의 각 Layer별로 서로 다른 병합 계수(
) 학습 - AdaMerging++: Ties-Merging에서 제안한 중복 파라미터 제거 및 부호 충돌 해결 후 최적화
- Task-wise AdaMerging: 각 Task Vector별로 서로 다른 병합 계수(
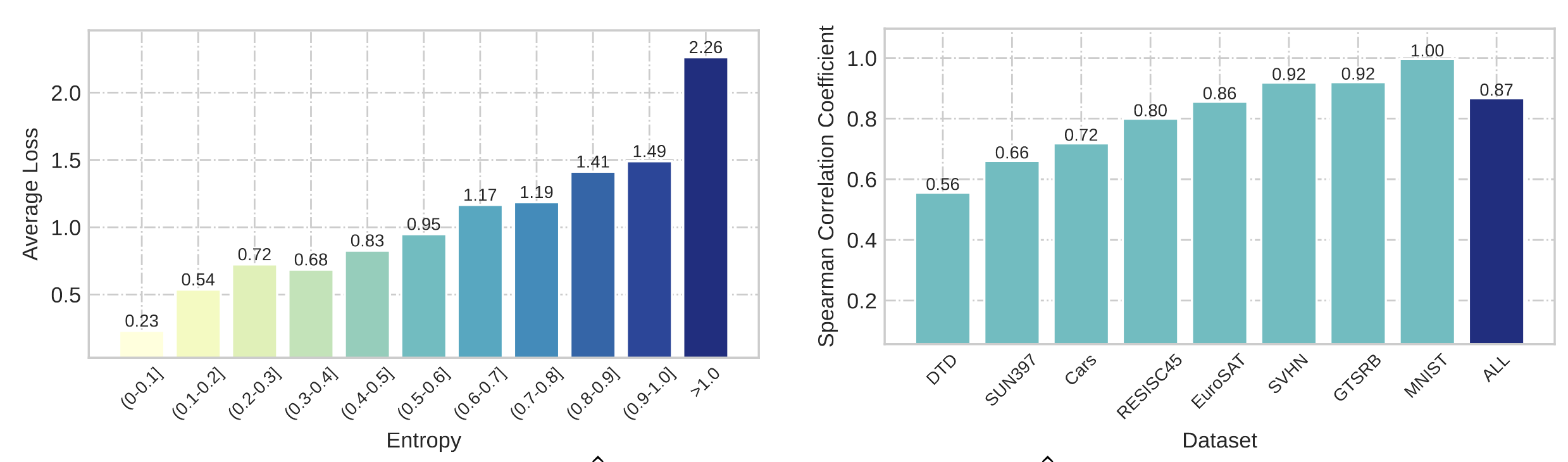
- 테스트 샘플의 엔트로피와 예측 손실 간의 강한 양의 상관관계 발견
- 낮은 엔트로피를 가진 샘플은 일반적으로 더 낮은 예측 손실을 보임 (Spearman 상관계수 0.87)
- Unsupervised Entropy Optimization: 각 Task의 Train Data에 접근 불가하므로, Test-Time Adaptation 이용
- 엔트로피 최소화를 Multi-Task 모델의 성능 향상을 위한 대리 목적 함수로 활용
- 레이블이 없는 테스트 데이터에서도 적용 가능한 비지도 접근법
- 최적화 목적 함수:
- Task-wise AdaMerging:
- Layer-wise AdaMerging: 각 층별로 다른 계수 최적화
- Task-wise AdaMerging:
- 엔트로피 최소화를 Multi-Task 모델의 성능 향상을 위한 대리 목적 함수로 활용
Method 검증
- 성능 향상 실험: 8개 Task에 대한 다양한 모델 병합 방식 성능 비교
- ViT-B/32: Layer-wise AdaMerging 80.1%, Task Arithmetic 69.1% → 11.0% 향상으로 Task Vector 기반 병합 방식의 성능 한계 극복
- ViT-L/14: AdaMerging 90.8%, Ties-Merging 86.0% → 4.8% 향상으로 모델 크기가 다른 환경에서도 일관된 개선 효과 입증
- 일반화 능력 실험: 6개 Task 병합 후 보지 못한 2개 Task에 대한 평가
- MNIST, EuroSAT: Task Arithmetic 61.7%, AdaMerging 70.0% → 8.3% 향상으로 미지 Task에 대한 우수한 적응 능력 입증
- RESISC45, SVHN: Ties-Merging 53.9%, AdaMerging 58.5% → 4.6% 향상으로 다양한 Task 유형에서의 일반화 능력 확인
- 강건성 실험: 7가지 데이터 분포 변화(Motion Blur, Noise 등)에 대한 평가
- Motion Blur: Task Arithmetic 69.4%, AdaMerging 80.6% → 11.2% 향상
- Gaussian Noise: Task Arithmetic 61.1%, AdaMerging 66.9% → 5.8% 향상
- JPEG Compression: Task Arithmetic 70.3%, AdaMerging 80.1% → 9.8% 향상
- 모든 왜곡 유형에서 평균 8.45% 성능 향상으로 데이터 분포 변화에 대한 뛰어난 강건성 확인
- 효율성 실험: 추가되는 파라미터 수 및 계산 비용 분석
- Task-wise: 8개 파라미터 추가(907M 대비 무시할 수준) → 최소한의 추가 비용으로 효율적 병합 가능
- 테스트 데이터 비율: 0.1% 사용 시 Task Arithmetic 대비 4.9% 향상 → 소량의 레이블 없는 데이터만으로도 실용적 성능 확보
- 훈련 시간: 7.5분 추가 훈련으로 2% 성능 향상 → 짧은 최적화 시간으로도 유의미한 개선 달성
Ablation Study
- Task Vector 관계 분석: 8개 Task Vector 간 Cosine 유사도 계산
- 대부분 유사도 0.03~0.05 수준 → Task Vector 간 거의 직교 관계로 효과적 병합 가능성 확인
- SVHN-MNIST만 유사도 0.16 → 유사 Task 간에도 적응적 계수로 간섭 최소화 가능
- Layer-wise 계수 패턴 분석: 각 Layer별 학습된 병합 계수 분석
- 얕은 층: 평균 0.2-0.3 수준의 낮은 계수 → 일반적 특징 추출층은 Pre-trained 모델에 더 의존
- 깊은 층: 평균 0.6-0.8 수준의 높은 계수 → Task 특화 층은 Fine-tuned 모델에 더 의존
- 이는 신경망에서 얕은 층이 일반 특징, 깊은 층이 특화된 특징을 담당한다는 이론과 일치
- 비지도 vs 지도 학습 비교: 실제 레이블을 사용한 지도 학습과 엔트로피 기반 비지도 학습 성능 비교
- Layer-wise 지도: 81.6%, 비지도: 80.1% → 1.5%p 차이로 엔트로피 최소화의 효과적인 대리 목적 함수 역할 입증
- AdaMerging++: 지도 82.0%, 비지도 81.1% → 레이블 없이도 최적에 가까운 성능 달성 가능