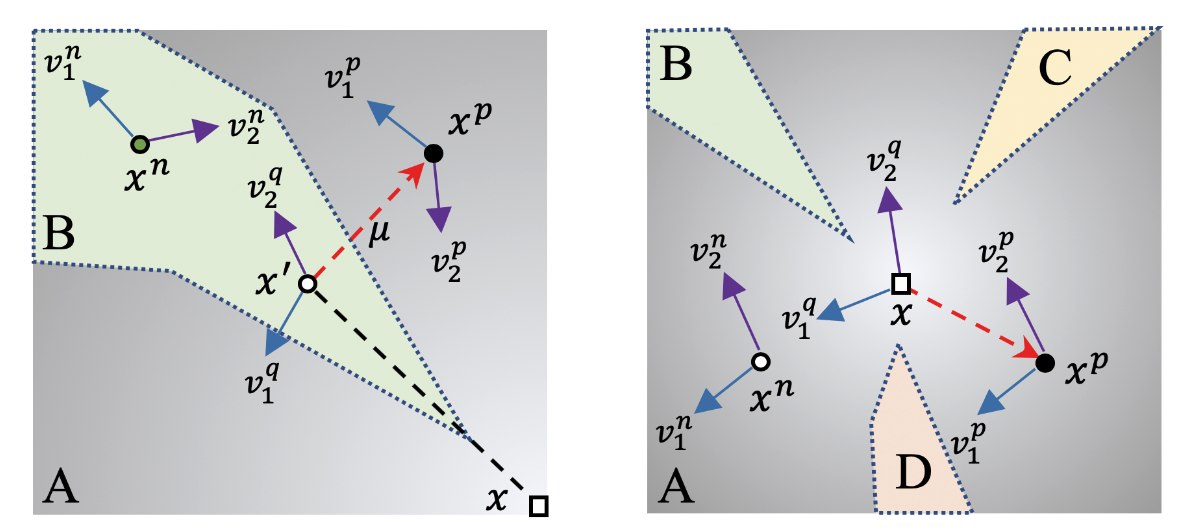
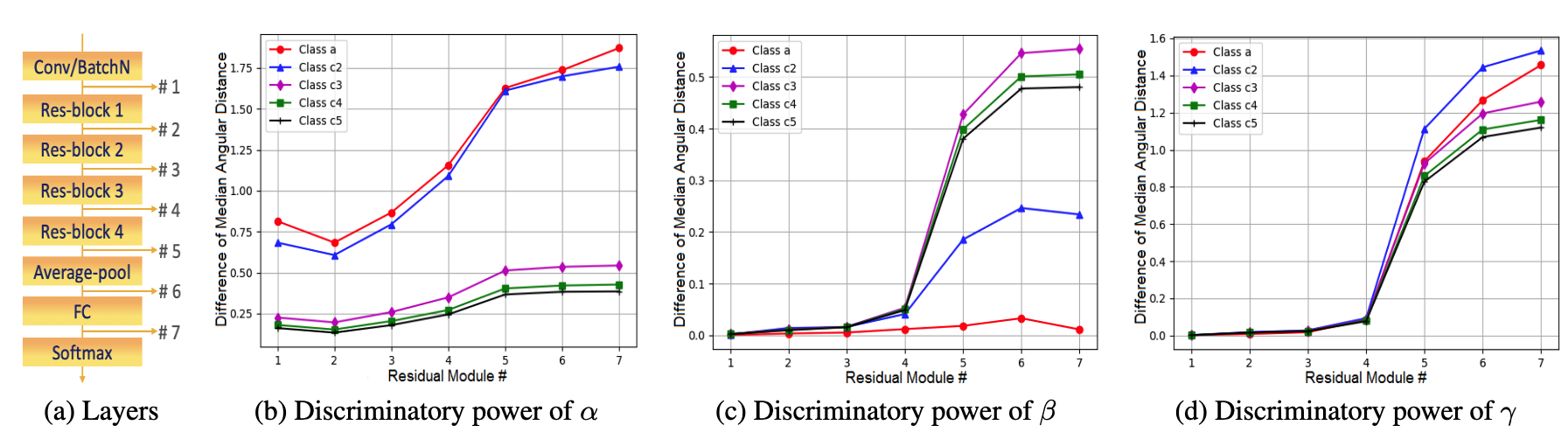
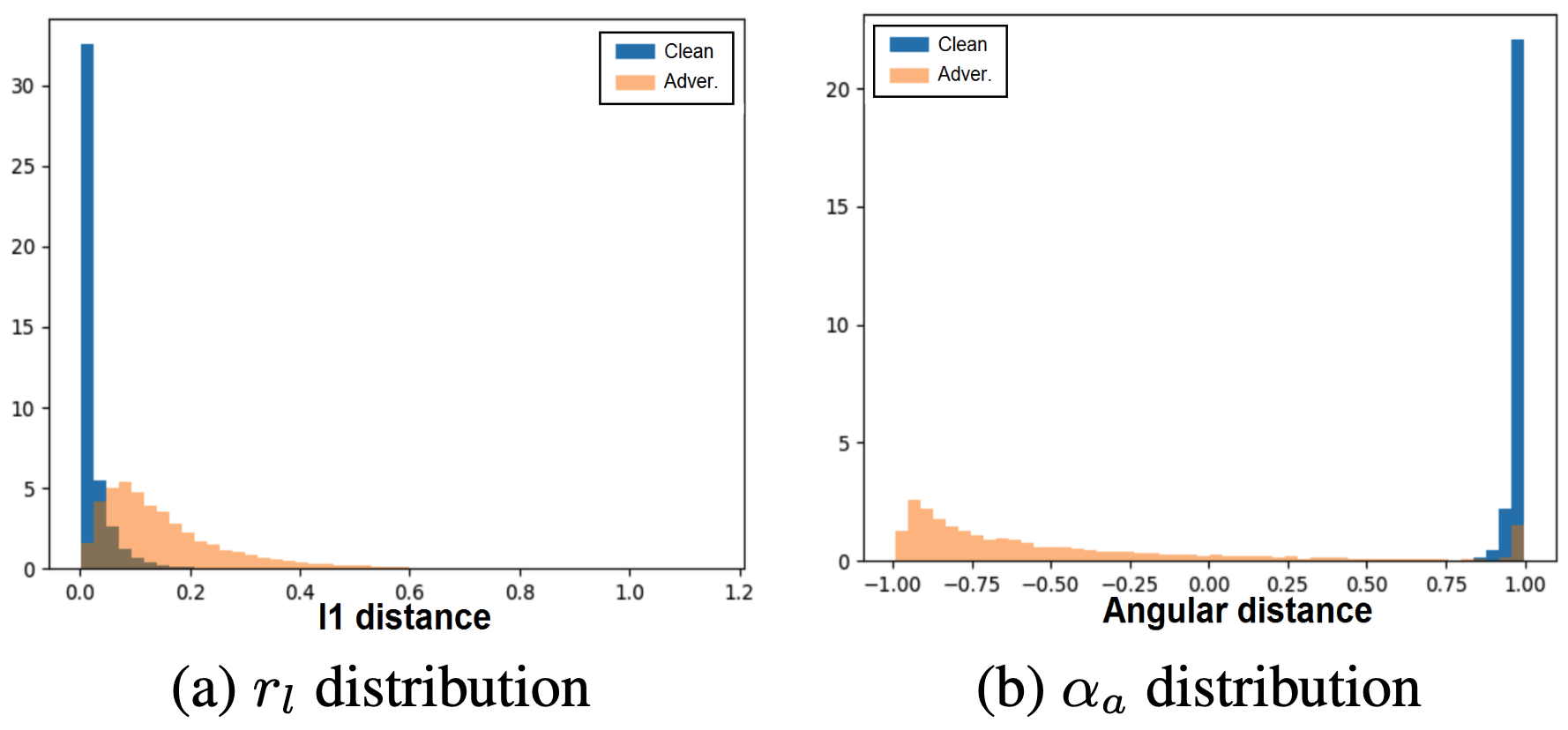
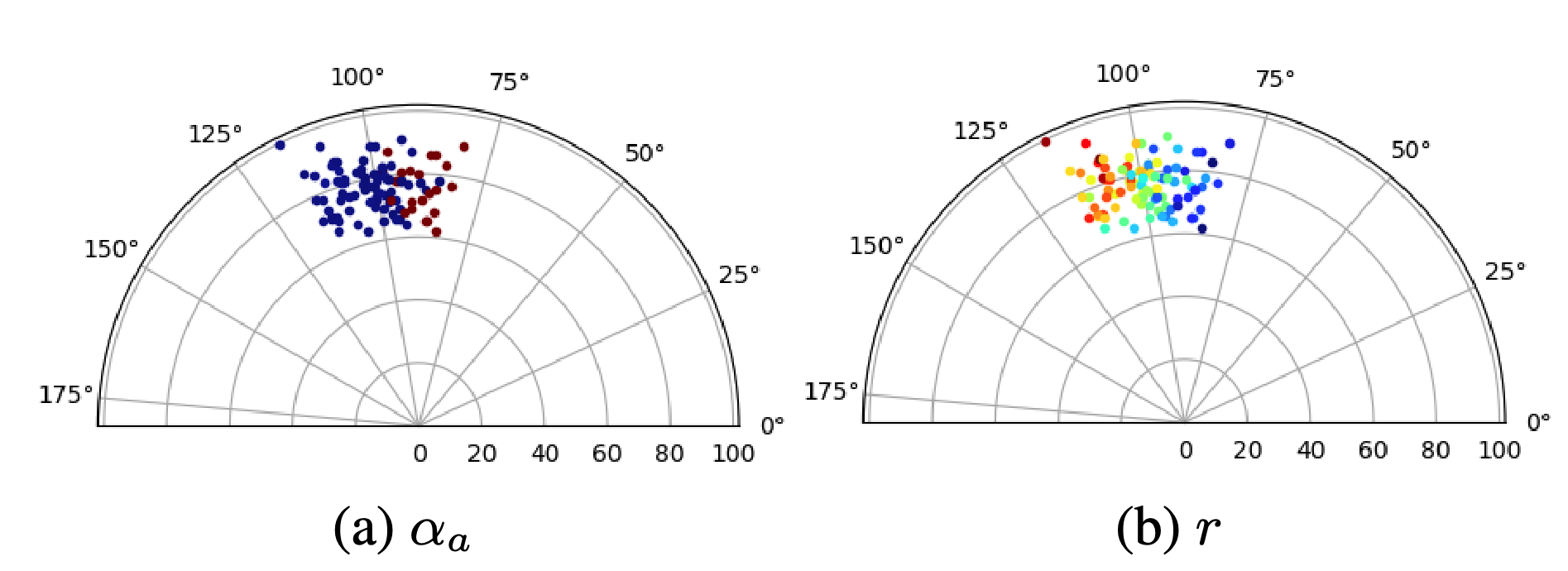
Adversarial examples are input examples that are specifically crafted to deceive machine learning classifiers. State-of-the-art adversarial example detection methods characterize an input example as adversarial either by quantifying the magnitude of feature variations under multiple perturbations or by measuring its distance from estimated benign example distribution. Instead of using such metrics, the proposed method is based on the observation that the directions of adversarial gradients when crafting (new) adversarial examples play a key role in characterizing the adversarial space. Compared to detection methods that use multiple perturbations, the proposed method is efficient as it only applies a single random perturbation on the input example. Experiments conducted on two different databases, CIFAR-10 and ImageNet, show that the proposed detection method achieves, respectively, 97.9% and 98.6% AUC-ROC (on average) on five different adversarial attacks, and outperforms multiple state-of-the-art detection methods. Results demonstrate the effectiveness of using adversarial gradient directions for adversarial example detection.
Synth
Problem:: 적대적 예제 탐지를 위한 기존 방법들은 여러 변환(Perturbation)을 필요로 하여 계산 비용이 높음/양성 예제 분포 추정을 위한 많은 참조 데이터가 필요해 실용성이 제한됨