MultiLoRA: Democratizing LoRA for Better Multi-Task Learning
LoRA achieves remarkable resource efficiency and comparable performance when adapting LLMs for specific tasks. Since ChatGPT demonstrated superior performance on various tasks, there has been a growing desire to adapt one model for all tasks. However, the explicit low-rank of LoRA limits the adaptation performance in complex multi-task scenarios. LoRA is dominated by a small number of top singular vectors while fine-tuning decomposes into a set of less important unitary transforms. In this paper, we propose MultiLoRA for better multi-task adaptation by reducing the dominance of top singular vectors observed in LoRA. MultiLoRA scales LoRA modules horizontally and change parameter initialization of adaptation matrices to reduce parameter dependency, thus yields more balanced unitary subspaces. We unprecedentedly construct specialized training data by mixing datasets of instruction follow, natural language understanding, world knowledge, to cover semantically and syntactically different samples. With only 2.5% of additional parameters, MultiLoRA outperforms single LoRA counterparts and fine-tuning on multiple benchmarks and model scales. Further investigation into weight update matrices of MultiLoRA exhibits reduced dependency on top singular vectors and more democratic unitary transform contributions.
Problem:: LoRA의 소수 특이값 의존 현상 때문에 MTL 성능이 저하됨 / 기존 MTL 방식들은 NLU에 국한됨
Solution:: 수평적 확장을 통해 동일한 파라미터 개수로 특이값 의존 현상 개선 / 더 다양한 태스크로 구성된 데이터 셋 구성
Novelty:: 특이값 분석을 통한 의존 현상 확인
Note:: 수학적으로 A 행렬에 대한 병렬화는 단순히 랭크를 늘린 것과 동일하지만, B 행렬에 대한 병렬화는 표현력 크게 향상시킴
Summary
Motivation
- 자연어 처리 모델의 일반적인 패러다임은 일반 도메인 데이터로 대규모 사전 학습 후 특정 작업/도메인에 적응시키는 것
- 모델 크기가 커질수록 모든 파라미터를 재학습하는 전체 파인튜닝(Full Fine-Tuning)이 비실용적
- LLaMA 모델은 7B에서 65B, GPT-3는 175B 파라미터로 메모리와 저장 비용 부담 심각
- 각 다운스트림 작업마다 전체 파라미터를 재학습시키는 것은 비효율적
- LoRA는 단일 작업에 효과적이지만 복잡한 다중 작업 환경에서의 성능은 확인되지 않음
- 기존 다중 작업 PEFT 방법의 한계:
- 추론 과정에 추가 오버헤드 발생
- 주로 NLU 태스크에 집중되어 있어 생성형 AI에 중요한 작업 고려 부족
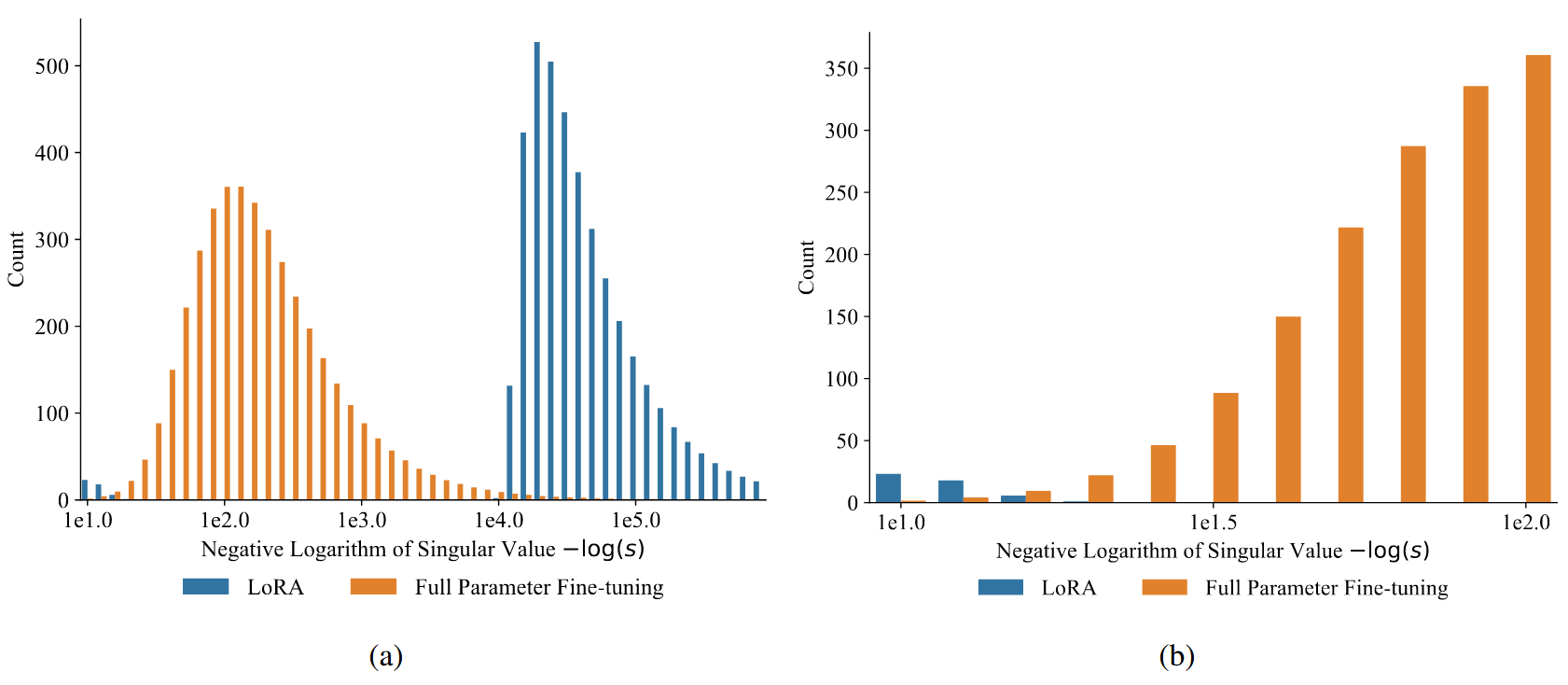
(a)는 전체 View, (b)는 큰 특이값 부분만 확대한 View → LoRA는 FT와 달리 소수의 큰 특이값만 존재
- 특이값 분해(SVD)로 가중치 업데이트 행렬(
) 분석 - 파인튜닝의 특이값 분포: 종 모양 곡선으로 균등한 분포
- LoRA의 특이값 분포: 양극단에 집중된 이중 모달 분포
- 최소
개의 특이값이 0 - 상위 특이값이 불균형적으로 많음
- 최소
- SVD로 분석으로 알 수 있는 것
- 파인튜닝: 원래 가중치 행렬의 순위에 해당하는 다수의 덜 중요한 유니터리 변환 활용
- LoRA: 명시적 저순위 제한(
)으로 소수의 중요한 유니터리 변환에 의존
- 즉, LoRA는 소수의 상위 특이값 벡터에 지배되는 반면, 파인튜닝은 더 균등한 유니터리 변환 기여도를 보임 → 이러한 지배 현상이 복잡한 다중 작업 적응 성능을 제한한다는 가설 수립
Method
MultiLoRA 설계
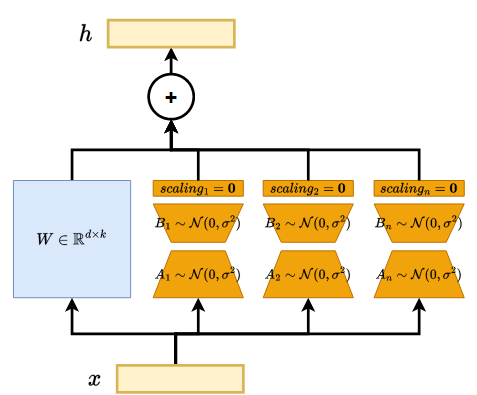
- MultiLoRA: LoRA 모듈을 수평적으로 확장하여 다양한 변환에 의존하도록 개선
- 파인튜닝과 유사한 부분 공간 및 특이값 분포 특성 보임
- 병렬 모듈 구조와 초기화 변경으로 유니터리 변환 기여도 균등화("민주화")
- 각 모듈이 서로 다른 특화된 기능을 학습하여 다중 작업 적응 능력 향상
- 핵심 구성 요소:
- 수평적 확장: 다수의 병렬 LoRA 모듈 사용하여 파라미터 의존성 감소
- 기존 LoRA:
- MultiLoRA:
- A 행렬과 B 행렬의 MultiLoRA에서의 차이:
- A 행렬에 대한 병렬화는 수학적으로 단순히 Rank를 증가시키는 것과 동일한 효과를 가짐 → 병렬 모듈
을 사용하는 것은 이들을 수직으로 쌓은 하나의 큰 행렬 을 사용하는 것과 동일하기 때문에 표현력 측면에서 추가적인 이득이 없음 - B 행렬에 대한 병렬화는 각 모듈이 독립적으로 서로 다른 특화된 변환을 학습할 수 있어 표현력을 크게 향상시킴 → 각
는 서로 다른 입력 패턴에 특화될 수 있으며, 이는 특이값 분석에서 관찰된 것처럼 다양한 유니터리 변환의 균등한 기여도("민주화")로 이어져 복잡한 다중 작업 시나리오에서 더 효과적인 적응 가능
- 기존 LoRA:
- 수평적 확장: 다수의 병렬 LoRA 모듈 사용하여 파라미터 의존성 감소
- 파라미터 초기화 변경:
행렬을 0 대신 Kaiming-Uniform으로 초기화하여 표현력 강화 - 0으로 초기화된 스케일링 계수를 도입하여 시작점 초기화 유지
- 시작점 초기화의 이중성 고려:
- 사전 학습 모델의 국소 최적점 주변에서 효율적 최적화 가능
- 0 초기화는 중복성을 도입하고 표현력 제한 문제 존재
새로운 실험 환경
- NLU를 포함한 다중 작업 학습을 위한 종합적 데이터셋 구성:
- Alpaca: 지시 따르기
- MMLU: 세계 지식
- GSM8K: 산술적 추론
- SuperGLUE: 자연어 이해
- LLaMA 시리즈(7B~65B) 모델에 적용
- 비교 대상: 전체 파인튜닝(FT), 단일 LoRA
Method 검증
다중 작업 성능 결과
- MultiLoRA는 동일한 파라미터 예산에서 LoRA보다 일관되게 우수한 성능 달성
- LLaMA-7B에서 MMLU 성능 3.5% 향상, RTE 성능 5.9% 향상
- 평가된 작업의 평균 점수에서 LoRA 대비 2.8% 향상
- 작은 모델(7B, 13B)에서는 전체 파인튜닝보다 더 나은 성능 달성
- LLaMA-7B에서 전체 파인튜닝 대비 1.1% 성능 향상
- LLaMA-65B에서는 전체 파인튜닝 대비 0.3% 감소
성능 안정성
- LoRA는 작은 모델에서 작업 간 성능 변동이 크게 나타남
- LLaMA-7B에서 MultiRC, RTE, WIC 점수가 전체 파인튜닝 대비 3% 이상 변동
- MultiLoRA는 전체 파인튜닝과 유사하게 일관된 개별 작업 점수 유지
- 소수의 상위 특이값 벡터 의존도 감소로 인한 안정성 향상
자원 효율성
- 훈련 처리량: MultiLoRA는 전체 파인튜닝 대비 2배 빠른 처리 속도
- GPU당 초당 약 400 토큰 처리 (전체 파인튜닝은 약 208 토큰)
- VRAM 사용량: MultiLoRA의 병렬 모듈 수에 따라 선형적으로 증가
- 장점: 훈련 가능한 파라미터 수 감소로 더 많은 데이터 샘플 로드 가능
- 단점: 긴 시퀀스 훈련 시 활성화를 위한 VRAM 사용량 증가 문제 존재
MultiLoRA 이해
특이값 분해 기반 부분 공간 비교
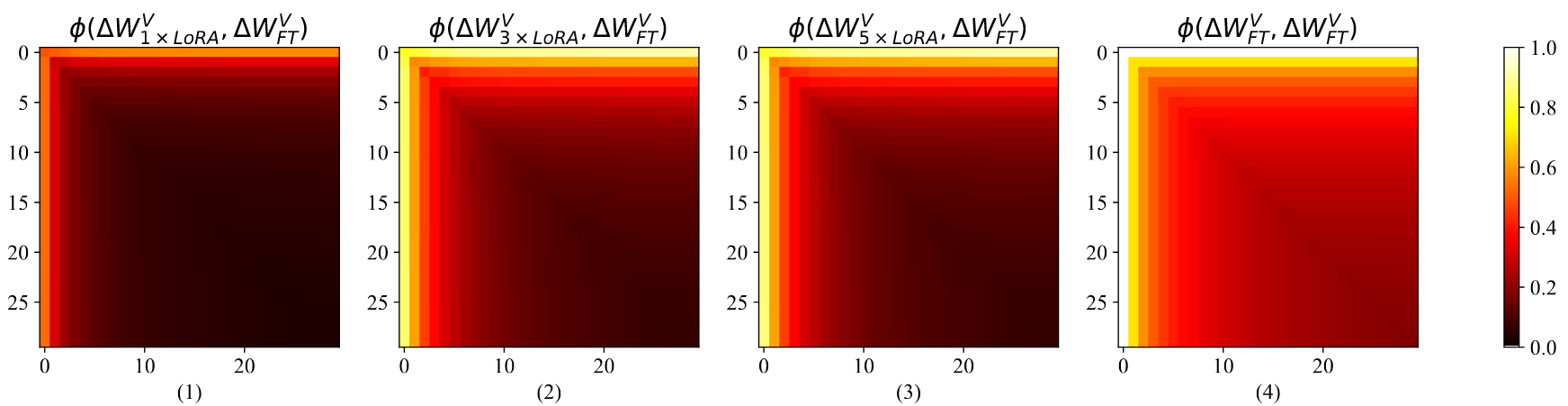
- 파인튜닝과의 부분 공간 유사성 측정:
- 수식:
와 는 각각 상위 개, 개의 특이 벡터로 구성된 행렬
- 수식:
- MultiLoRA는 동일 파라미터 예산의 LoRA보다 파인튜닝과 더 높은 부분 공간 유사성 보임
- LoRA의 히트맵은 전반적으로 어두운(낮은 유사도) 패턴이나 상위 특이 벡터는 일부 유사성 존재
- 병렬 모듈 수(
) 증가가 반드시 파인튜닝과의 유사성을 향상시키지는 않음 - 디코더 스택의 다양한 깊이와 모듈에서도 일관된 패턴 관찰됨
특이값 분포 분석
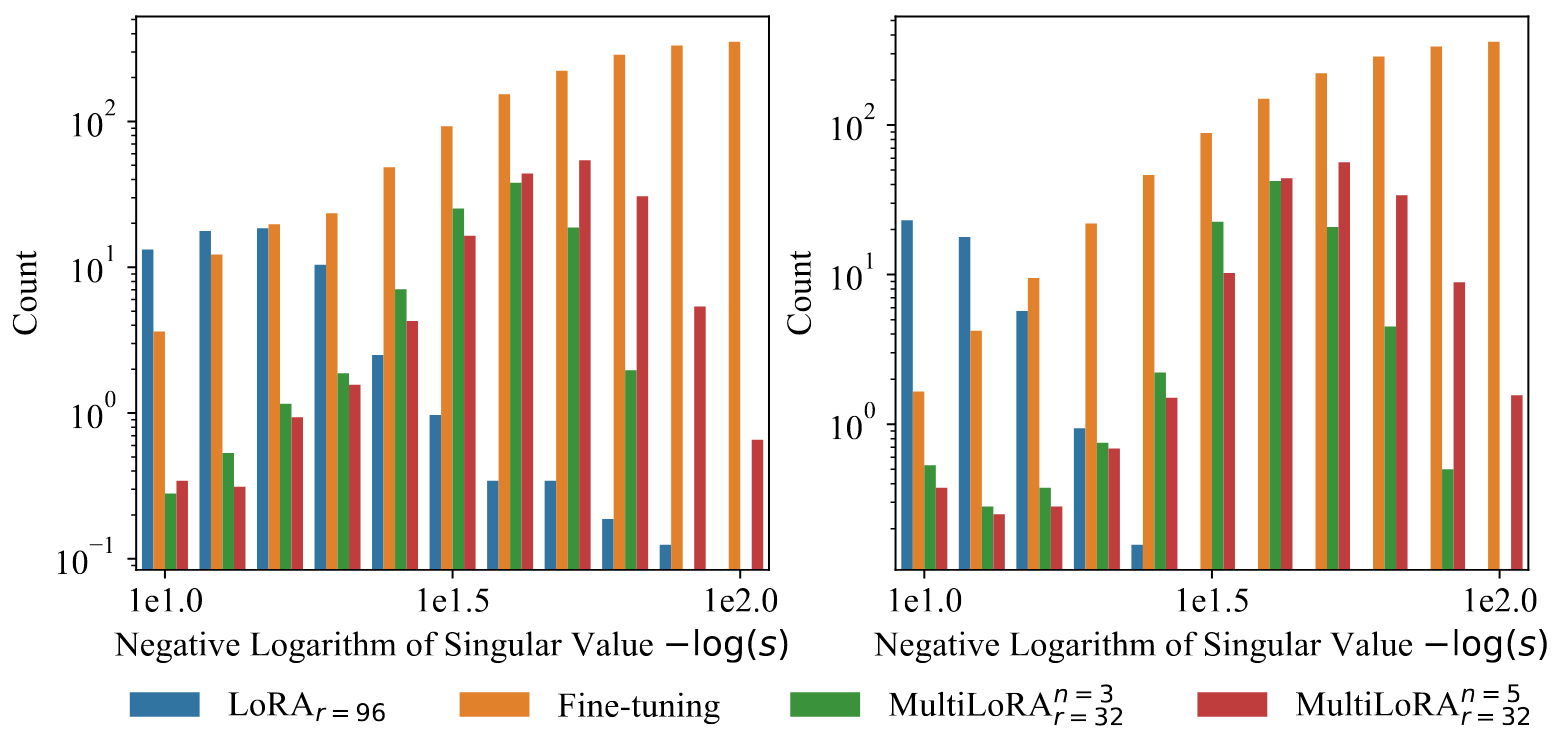
- MultiLoRA는 파인튜닝과 유사한 분포 패턴을 보임: 특이값 크기가 클수록 개수 감소
- LoRA는 소수의 큰 특이값에 의존하는 반면, MultiLoRA는 특이값 기여도가 더 균등하게 분포
- MultiLoRA(
, )는 MultiLoRA( , )보다 더 넓은 특이값 스펙트럼 보유 - 작은 특이값 비율 증가로 더 세밀한 가중치 업데이트 적합 가능
- 이는 파인튜닝이 다수의 덜 중요한 유니터리 변환을 활용하는 특성과 유사
MultiLoRA 모듈 간 부분 공간 유사도 변동성
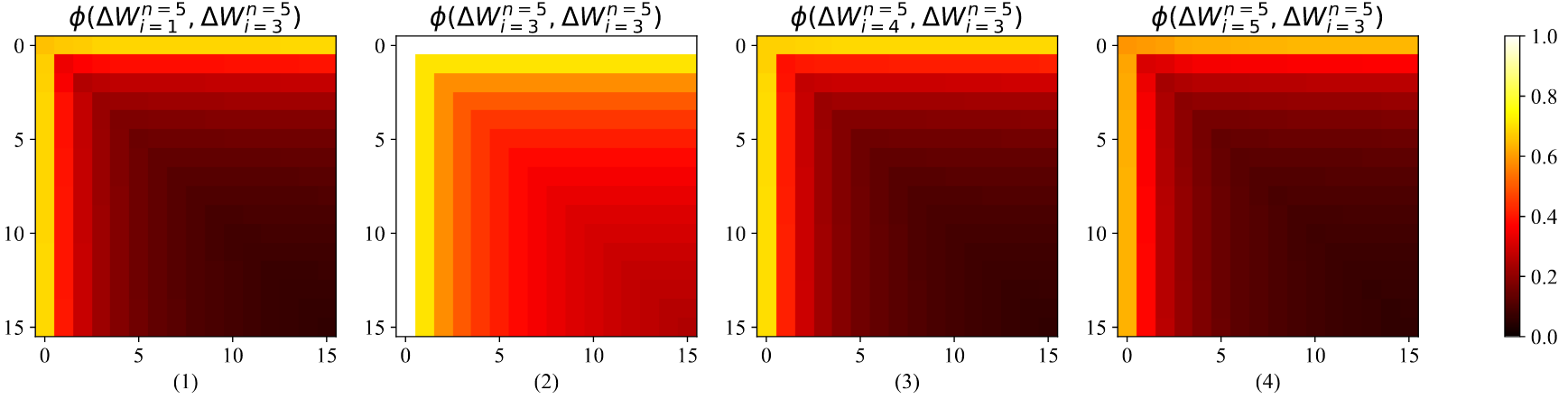
- 첫 번째 디코더 레이어의 down_proj 모듈에서 5개 병렬 LoRA 모듈 분석
- 모듈 간 상위 특이 벡터의 코사인 유사도는 평균적으로 약 0.6 수준
- 완전히 독립적이지는 않지만 상당한 차이 존재
과 , 와 , 와 간 유사도 패턴이 서로 다름 - 부분 공간 유사도의 변동성이 의미하는 것:
- 각 병렬 모듈이 서로 다른 특화된 패턴을 포착
- 서로 보완적인 부분 공간을 학습하여 표현력 향상
- 복잡한 다중 작업에 필요한 다양한 변환을 효과적으로 표현
- 단순히 LoRA의 순위를 증가시키는 것보다 더 풍부한 표현 공간 제공