Un-Gaze: A Unified Transformer for Joint Gaze-Location and Gaze-Object Detection
This paper proposes an efficient and effective method for joint gaze location detection (GL-D) and gaze object detection (GO-D), i.e., gaze following detection. Current approaches frame GL-D and GO-D as two separate tasks, employing a multi-stage framework where human head crops must first be detected and then be fed into a subsequent GL-D sub-network, which is further followed by an additional object detector for GO-D. In contrast, we reframe the gaze following detection task as detecting human head locations and their gaze followings simultaneously, aiming at jointly detect human gaze location and gaze object in a unified and single-stage pipeline. To this end, we propose GTR, short for Gaze following detection TRansformer, streamlining the gaze following detection pipeline by eliminating all additional components, leading to the first unified paradigm that unites GL-D and GO-D in a fully end-to-end manner. GTR enables an iterative interaction between holistic semantics and human head features through a hierarchical structure, inferring the relations of salient objects and human gaze from the global image context and resulting in an impressive accuracy. Concretely, GTR achieves a 12.1 mAP gain ( \mathbf 25.1% ) on GazeFollowing and a 18.2 mAP gain ( \mathbf 43.3% ) on VideoAttentionTarget for GL-D, as well as a 19 mAP improvement ( \mathbf 45.2% ) on GOO-Real for GO-D. Meanwhile, unlike existing systems detecting gaze following sequentially due to the need for a human head as input, GTR has the flexibility to comprehend any number of people’s gaze followings simultaneously, resulting in high efficiency. Specifically, GTR introduces over a \times 9 improvement in FPS and the relative gap becomes more pronounced as the human number grows.
Problem:: 기존 시선 추적 감지 시스템은 GL-D와 GO-D를 별도의 작업으로 분리하여 처리/사람 머리 crop을 입력으로 요구하여 추가 머리 검출기 필요/한 번에 한 사람의 시선 추적만 처리 가능하여 다수의 사람이 있는 경우 비효율적/전체 장면과 머리 포즈 특징을 분리해서 추출하여 맥락적 관계 이해 부족
Solution:: 시선 추적 감지를 사람 머리 위치와 시선 추적을 동시에 감지하는 문제로 재정의/시각 인코더와 두 개의 디코더로 구성된 단일 단계 파이프라인 설계/가중치 안내 임베딩(w-GE)을 통해 인간 쿼리와 전체 장면 맥락 간 동적 상호작용 구현/두 디코더 간 계층적이고 반복적인 정보 흐름을 통해 효과적인 관계 추론
Novelty:: 얼굴 검출과 시선 목표 추정을 개별 Branch에서 처리하는 최초의 연구
Note:: 여전히 통합된 Hungarian Matching을 사용함 → 두 Task간의 갈등이 존재 할 수 있음/논문에 보고된 두 Branch를 연결 하지 않았을 때 성능이 하락됨 → 두 Task를 별도의 처리 없이 하나의 Feature로 처리하면 성능이 하락됨
Summary
Motivation
- 기존 시선 추적 감지 시스템은 Gaze Location Detection(GL-D)과 Gaze Object Detection(GO-D)을 별도의 작업으로 처리
- 이러한 시스템들은 다단계 프레임워크를 사용하여 작동:****
- 먼저 사람 머리 crop 검출 필요
- 이후 GL-D 서브네트워크로 입력
- 마지막으로 GO-D를 위한 추가 객체 검출기 필요
- 기존 접근 방식의 주요 한계점:
- 사람 머리 crop을 입력으로 요구하여 추가 머리 검출기 필요
- 한 번에 한 사람만 처리 가능하여 여러 사람이 있는 경우 비효율적
- 전체 장면과 머리 포즈 특징을 분리해서 추출하여 맥락적 관계 이해 부족
- GL-D와 GO-D를 통합하는 end-to-end 프레임워크 부재
Method
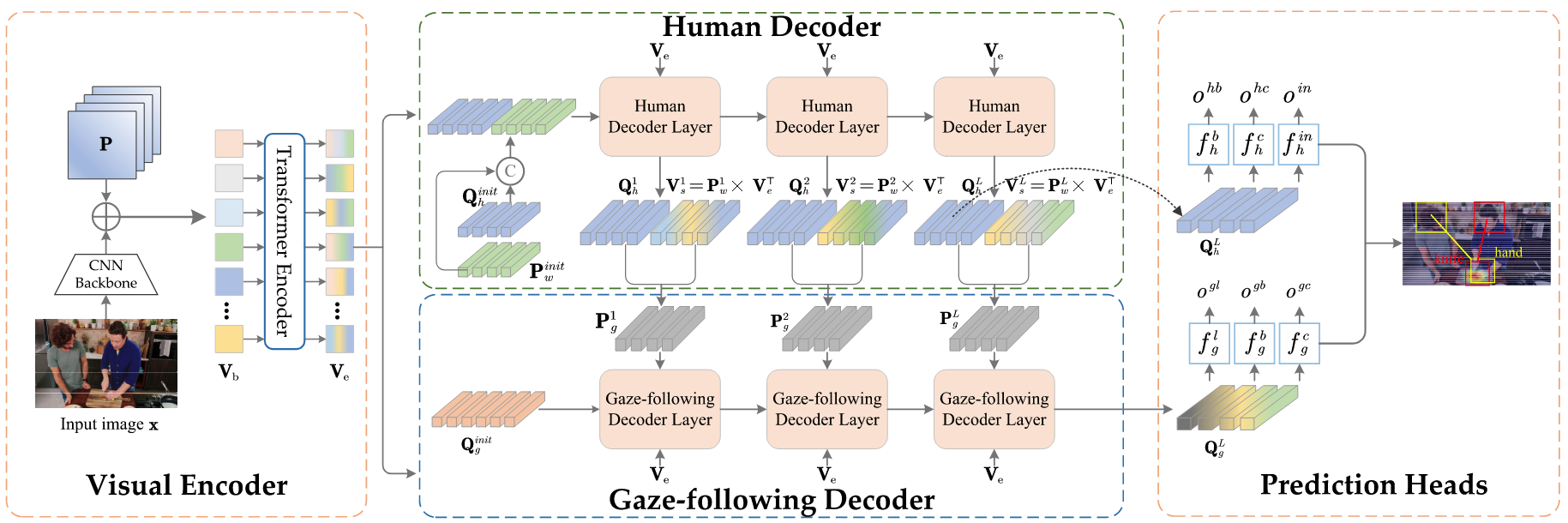
- 시선 추적 감지 작업을 사람 머리 위치와 시선 추적을 동시에 감지하는 문제로 재정의
- 입력: 이미지
- 출력:
개의 인간-시선-추적(HGF) 트리플릿
- 입력: 이미지
- GTR(Gaze following detection TRansformer) 제안:
- 시각 인코더와 두 개의 디코더(Human, Gaze-Following)로 구성된 단일 단계 파이프라인
- Visual Encoder:
- CNN 백본(ResNet)을 통해 고수준 시각 특징 추출
- Transformer 인코더로 컨텍스트 정보 강화
- Human Decoder:
- 사람 쿼리(
)를 통해 이미지 내 모든 사람 인식 - 가중치 안내 임베딩(w-GE)
학습하여 장면 내 다른 영역과의 관계 모델링
- 사람 쿼리(
- Gaze-Following Decoder:
- Human Decoder와 상호작용하며 각 사람의 시선 위치와 객체 추론
- 인간 쿼리와 장면 컨텍스트를 동적으로 결합한 가이드 집계(
) 사용 - 두 디코더 간 계층적이고 반복적인 정보 흐름 통해 풍부한 특징 추출
- Prediction Heads:
- 병렬 MLP를 통해 최종 예측 생성
- 인간 머리 경계 상자, 시선 위치 히트맵, 시선 객체 경계 상자 및 카테고리 예측
는 제로, 는 가우시안 임베딩으로 초기화
- Loss Calculation:
- 헝가리안 알고리즘 기반 이분 매칭으로 예측과 실측 간 일대일 대응 찾기
- 매칭 비용: 사람 머리 예측, 시선 위치 예측, 시선 객체 예측 비용의 가중 합
- 통합된 목적 함수: 경계 상자 회귀, 시선 위치 예측, GIoU 손실, 분류 손실 등 결합
Method 검증
Main Results
- 데이터셋:
- GL-D: GazeFollowing, VideoAttentionTarget
- GO-D: GOO(Gaze On Objects) - GOO-Synth, GOO-Real
- 주요 성능 향상:
- GL-D: GazeFollowing에서 12.1 mAP 향상(25.1%), VideoAttentionTarget에서 18.2 mAP 향상(43.3%) → 기존 방법보다 우수한 시선 위치 감지 능력
- GO-D: GOO-Real에서 19 mAP 향상(45.2%) → 시선 객체 감지에서도 큰 성능 향상
- 효율성: 기존 방법 대비 9배 이상의 FPS 향상, 특히 이미지 내 사람 수가 증가할수록 효율성 차이 더욱 두드러짐 → 실시간 응용 가능성 확보
- 효과성 분석:
- 모델 견고성: 이미지 품질 저하(블러, 노이즈, 밝기 변화 등) 상황에서도 우수한 성능 유지 → 실제 환경에서의 적용 가능성 입증
- 추가 분석 결과: 장거리 시선 행동 감지와 사회적 공유 시선 감지에서 우수한 성능 → 다양한 시선 관련 태스크에 활용 가능
Ablation Studies
- Visual Encoder:
- CNN+Transformer 인코더 사용 시 GL-D에서 23.4%, GO-D에서 34.0% 성능 향상 → 전역 컨텍스트 모델링의 중요성 입증
- Transformer 인코더의 Self-Attention이 장거리 시선 행동 감지에 특히 효과적 → 기존 방법 대비 장거리 시선 감지 능력 우수
- Two-Branch Decoders:
- Human Decoder와 Gaze-Following Decoder 구분이 GL-D에서 2.2%, GO-D에서 21.1% 성능 향상 → 태스크별 특화된 디코더의 효과 입증
- 가중치 안내 임베딩(w-GE)이 GL-D에서 18.5%, GO-D에서 39.1% 성능 향상 → 인간 쿼리와 장면 맥락 간 관계 모델링의 중요성 확인
- 두 디코더 간 계층적 연결을 제거하면 GL-D에서 6.9%, GO-D에서 14.8% 성능 저하 → 계층적 정보 흐름의 필요성 입증
- Loss Design:
- 통합된 손실 함수가 GL-D와 GO-D 동시 최적화에 효과적 → 단일 프레임워크에서 두 태스크의 성공적 통합
- 머리 위치 검출, 시선 위치 검출, 시선 객체 검출에 대한 가중치 조정으로 최적 성능 도출 → 고도로 튜닝된 손실 함수 설계