From the onset of infanthood, humans naturally develop the ability to closely observe and interpret the visual gaze of others. This skill, known as gaze following, holds significance in developmental theory as it enables us to grasp another person's mental state, emotions, intentions, and more [6]. In computer vision, gaze following is defined as the prediction of the pixel coordinates where a person in the image is focusing their attention. Existing methods in this research area have predominantly centered on pinpointing the gaze target by predicting a gaze heatmap or gaze point. However, a notable drawback of this approach is its limited practical value in gaze applications, as mere localization may not fully capture our primary interest understanding the underlying semantics, such as the nature of the gaze target, rather than just its 2D pixel location. To address this gap, we extend the gaze following task, and introduce a novel architecture that simultaneously predicts the localization and semantic label of the gaze target. We devise a pseudo-annotation pipeline for the GazeFollow dataset, propose a new benchmark, develop an experimental protocol and design a suitable baseline for comparison. Our method sets a new state-of-the-art on the main GazeFollow benchmark for localization and achieves competitive results in the recognition task on both datasets compared to the baseline, with 40% fewer parameters.
Synth
Problem:: 기존 시선 목표 추정 연구는 사실상 좌표 예측이라 실용성이 떨어짐/의미적 정보 추론을 위해선 카테고리가 한정된 검출 모델을 사용해야 함/Semantic 정보가 포함된 HOI 데이터 셋은 시선 목표 추정과 적합하지 않음
Solution:: 언어 모델 임베딩을 이용해 검출 모델 없이 의미적 정보와 시선 목표를 함께 추론/시선 목표 추정에 적합한 GazeHOI 데이터 셋 제안
Novelty:: 최초로 SAM 등의 파운데이션 모델을 이용해 시선 목표와 관련된 의미적 정보를 라벨링/언어 모델 임베딩을 활용한 Recognition 수행
Note:: 저자들은 Vocabulary 기반이라 Zero-Shot도 가능하다고 하지만 성능이 잘 나오진 않음. 다음 스텝으로 시선과 관련된 행동의 동기를 추정해 보는건 어떨까
Summary
Motivation
기존 Gaze Following 연구는 단순히 사람이 바라보는 위치(좌표)만 예측하고 대상의 의미적 정보는 무시함
시선 관련 실용적 응용에서는 대상이 무엇인지(의미적 정보)도 중요하나, 기존 방식으로는 불충분
기존 방식에서 의미 정보를 얻으려면 Object Detector를 별도로 사용해야 하나, 이는 비효율적이며 Uncountable 객체(벽, 바다 등)를 무시함
사람의 시선이 Object와 밀접한 관련이 있다는 점에서 Human-Object-Interaction 데이터를 사용할 수도 있으나, 해당 데이터의 경우 시선과 관련된 TV라는 객체의 존재와 본다라는 행동과 밀접한 관련이 있어 시선 목표 추정에 의도치 않은 상관관계를 부여 할 수 있음
Method
Text Vocabulary Based Gaze Target Estimation
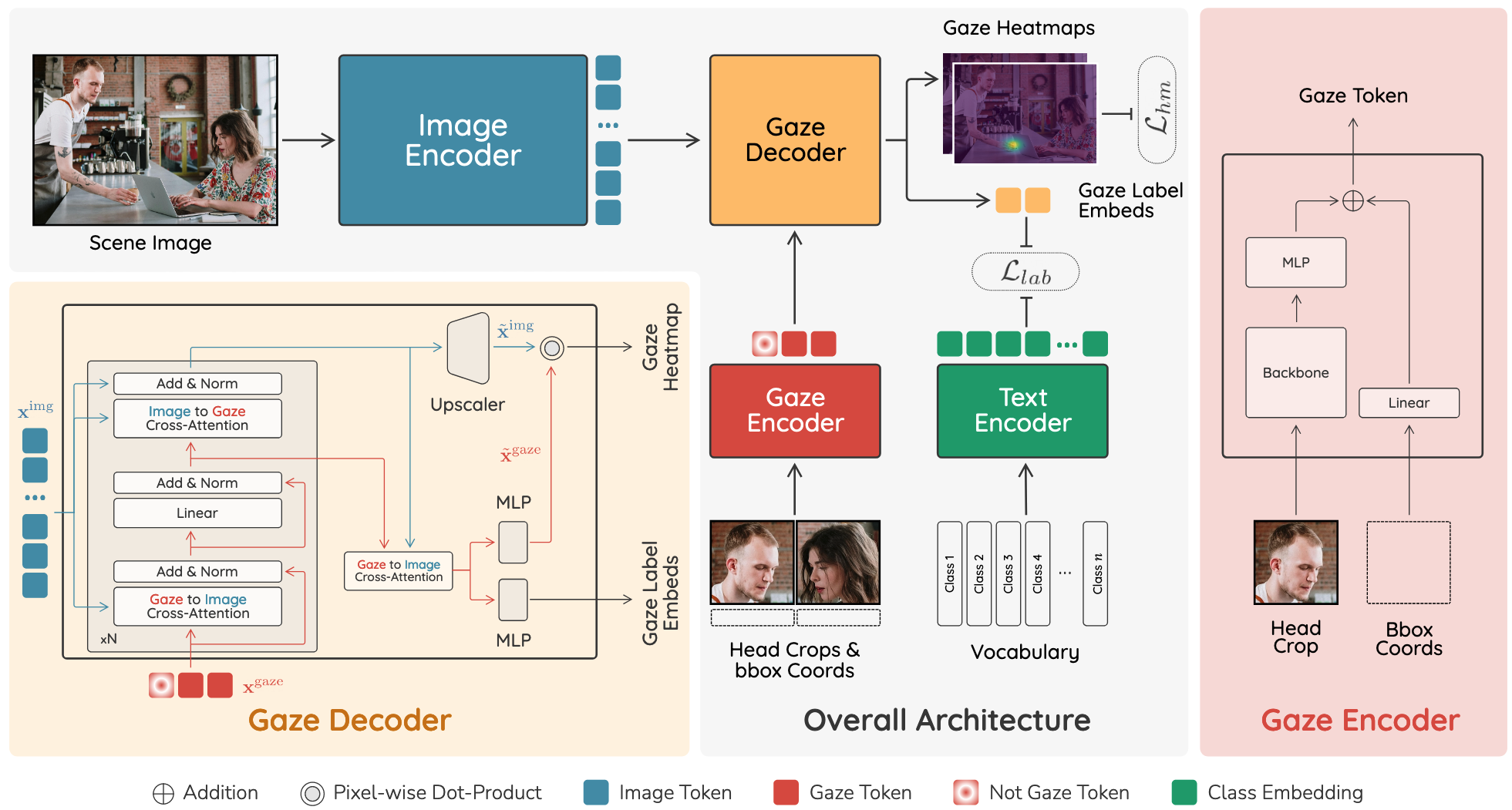
대상 위치와 의미적 라벨을 동시에 예측하는 End-to-End 아키텍처 제안
Visual-Text Alignment 기반 접근으로 학습 데이터셋에 없는 클래스도 일반화 가능
Scene Image와 Head 정보를 분리해 처리하는 Transformer 기반 구조로 다중 인물 처리 효율성 향상
Scene은 Image Encoder로 한 번만 처리하고, 각 사람의 Head와 위치 정보는 Gaze Encoder로 처리
Gaze Decoder에서 Cross-Attention 메커니즘으로 두 정보 결합
시선 대상 위치(Heatmap)와 라벨 임베딩을 동시 예측
CLIP 텍스트 인코더 활용해 다양한 클래스 어휘 지원
Loss
Heatmap Loss : 예측 히트맵과 GT 히트맵 간 MSE
Label Loss : 시선 임베딩과 GT 클래스 임베딩 간 대조 손실
공식
: 시선 라벨 임베딩
: GT 시선 라벨
시선 대상의 의미적 라벨을 예측하기 위한 대조 손실 함수
CLIP의 InfoNCE 손실을 기반으로 하지만 시선 추적 태스크에 맞게 수정됨
InfoNCE는 이미지 → 텍스트/텍스트 → 이미지의 양방향 대조 → 본 논문은 이미지 → 텍스트만 고려
중복성 발생 원인: 시선 대상은 "책", "전화기"와 같은 단순 클래스로, 여러 사람이 같은 종류의 물체를 볼 수 있음 → InfoNCE는 서로 하나의 클래스가 할당된다고 가정함
중복 처리 메커니즘: 배치 내 고유 클래스 집합 를 사용하여 분모 계산
학습된 온도 파라미터 를 사용해 유사도 분포 조절
Angular Loss : 시선 방향 예측을 위한 각도 손실 → 성능에는 영향이 적고, 해석에 도움이 됨
임베딩과 라벨 매칭 과정
예를 들어, 배치 크기가 4인 경우:
샘플 1: 사람이 "책"을 봄 → GT 라벨 = "책"
샘플 2: 사람이 "컴퓨터"를 봄 → GT 라벨 = "컴퓨터"
샘플 3: 다른 사람이 "책"을 봄 → GT 라벨 = "책"
샘플 4: 사람이 "전화기"를 봄 → GT 라벨 = "전화기"
이 경우:
고유 클래스 집합 U =
샘플 1의 visual embedding은 "책" class embedding과 매칭
샘플 2의 visual embedding은 "컴퓨터" class embedding과 매칭
샘플 3의 visual embedding도 "책" class embedding과 매칭
샘플 4의 visual embedding은 "전화기" class embedding과 매칭
원래 GazeFollow는 시선 목표에 대한 라벨이 없는데, 저자들은 Foundation을 이용한 Pseudo-Annotation으로 할당함
GazeHOI
시선 위치와 대상 클래스를 동시에 인식하기 위한 새로운 벤치마크 데이터셋
기존 Human-Object Interaction(HOI) 데이터셋을 시선 추적 목적으로 재구성
시선 대상의 의미적 레이블이 포함된 첫 번째 대규모 데이터셋
Method 검증
GazeFollow 데이터셋에서 위치 예측 SOTA 달성 (Avg. Dist 0.108, Min. Dist 0.051)
기존 최고 모델(Tafasca 등) 대비 4.4%, Jin 등 대비 8.5%의 위치 예측 정확도 향상
클래스 인식에서 44.7%의 Acc@1, 64.2%의 Acc@3 달성하며 기본 베이스라인 대비 높은 성능 기록
GazeHOI 데이터셋에서 72.3%의 GazeAcc와 58.3%의 Acc@1 달성
제로샷 설정에서도 GazeHOI에 대해 65.2%의 GazeAcc 기록하며 일반화 능력 입증
Ablation study를 통해 Label Loss, 배치 크기, Not Gaze Token 등 개별 컴포넌트의 기여도 검증
42% 적은 파라미터(116M vs 200M)로 경쟁력 있는 성능 달성
다중 인물 시나리오에서 처리 효율성이 기존 모델 대비 크게 향상됨을 입증
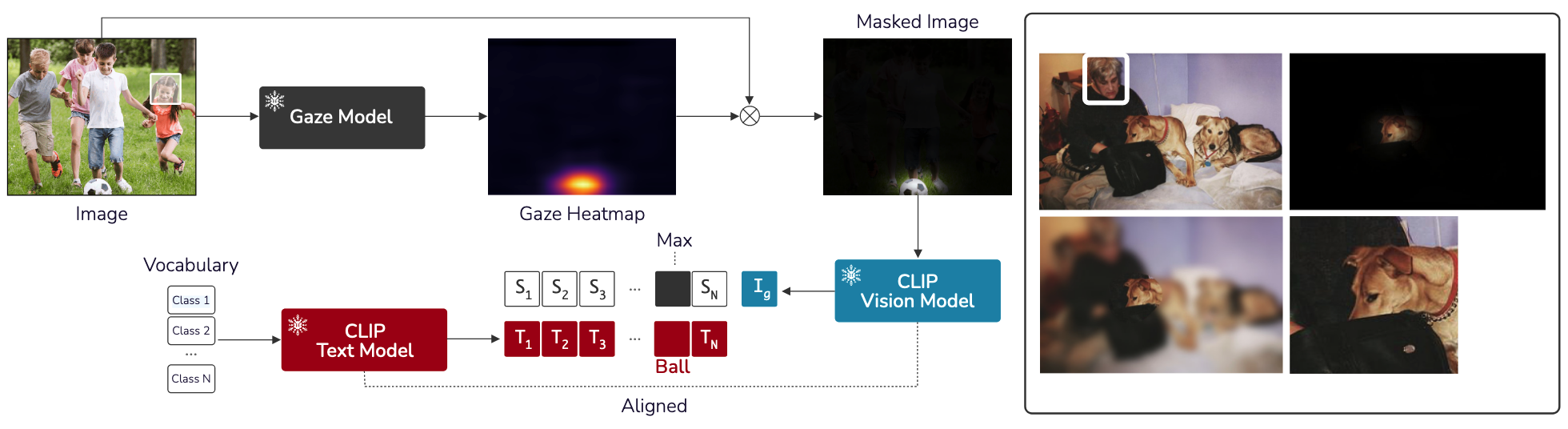
실험 파트의 Baseline은 Recognition 성능 비교를 위한 것으로, Heatmap만 가지고 Recognition을 했을 때의 성능을 나타냄. 아래 그림의 오른쪽 처럼 CLIP VIsion Model에 넣어 Recognition 성능을 측정하겠다는 의미