Sparse Autoencoders for Scientifically Rigorous Interpretation of Vision Models
To truly understand vision models, we must not only interpret their learned features but also validate these interpretations through controlled experiments. Current approaches either provide interpretable features without the ability to test their causal influence, or enable model editing without interpretable controls. We present a unified framework using sparse autoencoders (SAEs) that bridges this gap, allowing us to discover human-interpretable visual features and precisely manipulate them to test hypotheses about model behavior. By applying our method to state-of-the-art vision models, we reveal key differences in the semantic abstractions learned by models with different pre-training objectives. We then demonstrate the practical usage of our framework through controlled interventions across multiple vision tasks. We show that SAEs can reliably identify and manipulate interpretable visual features without model re-training, providing a powerful tool for understanding and controlling vision model behavior. We provide code, demos and models on our project website: https://osu-nlp-group.github.io/SAE-V.
Problem:: Vision Model 해석 방법들이 해석 가능한 특징 제공과 인과적 통제를 동시에 수행 못함 / Feature Visualization은 관찰만 가능하고 검증 불가 / Adversarial Examples는 조작은 가능하나 해석 불가 / Network Dissection은 분산 표현과 Polysemanticity 문제로 신뢰성 부족
Solution:: Sparse Autoencoders (SAEs)를 Vision Transformer에 적용하여 해석과 통제를 통합 / Dense Activation을 Sparse Feature로 분해하여 각 차원이 특정 개념 담당 / 6단계 개입 프로세스로 특정 Feature 값 조작 후 모델 행동 변화 관찰 / Fine-grained Classification과 Semantic Segmentation에서 검증
Novelty:: 과학적 방법론 (관찰→가설→실험)을 Vision Model 해석에 체계적 적용 / Language Supervision이 만드는 추상화 차이 발견 (CLIP: 문화적/추상적 개념 vs DINOv2: 저수준 시각 패턴) / Feature 간 Pseudo-Orthogonality로 독립적 조작 가능 / 기존 모델에 재학습 없이 적용 가능한 Plug-and-Play 방식
Note:: Language Supervision을 이용한 학습이 Semantic 정보를 많이 가지는데, 우리가 해석 가능한 방식은 언어이므로 당연한거라고 봐아햐나?
Motivation
문제제기: Vision Model 이해의 한계

- Figure 1은 Genomics, Grad-CAM, SAEs의 과학적 방법론을 비교:
- Genomics: DNA 서열 관찰 → 유전자가 파란색 원인이라는 가설 → Gene Knockout으로 검증
- Grad-CAM: Blue Jay 예측 시 Saliency Map 생성 → 하지만 검증 방법이 없음 (빨간 물음표)
- SAEs: Blue Jay 예측 → "Blue Feathers" 특징 발견 → 특징 억제로 Clark's Nutcracker로 변경 확인
- 현재 방법들의 한계:
- Feature Visualization은 해석 가능한 관찰을 제공하지만 실제로 모델 행동을 주도하는지 검증 불가
- Adversarial Examples는 조작은 가능하지만 왜 작동하는지 해석 불가
SAE가 발견하는 다양한 특징들

- Figure 2는 CLIP ViT-B/16에서 발견된 8개 특징 예시:
- 시각적 패턴: Rock 텍스처, Black and White Stripes, Container Ships
- 의미적 구조: Mobile Phones in Use, People Wearing Face Masks
- 24,576차원 Sparse Feature Space에서 각 차원이 특정 개념 포착
Method
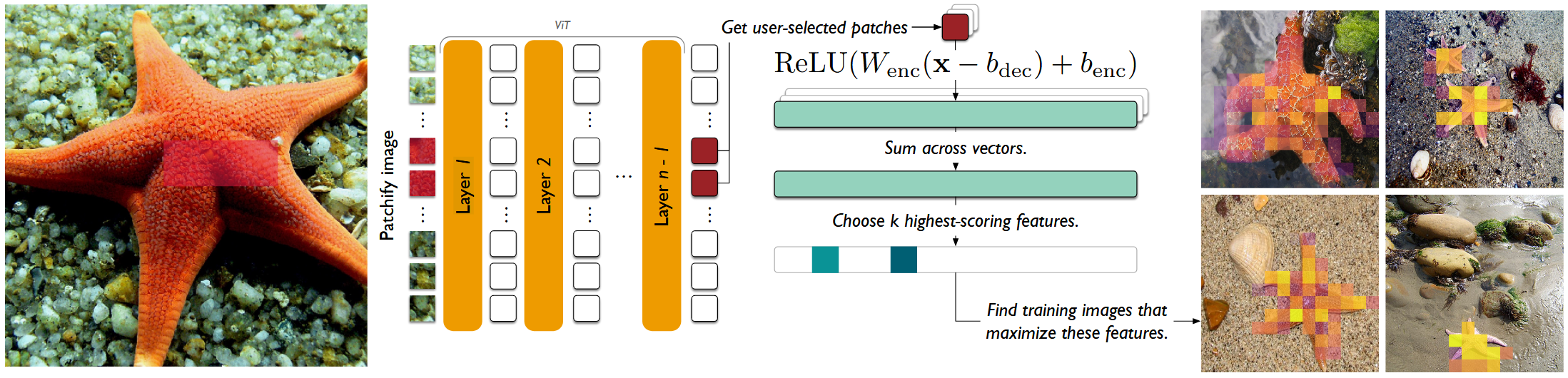
- 불가사리 이미지에서 특징 발견 과정 시각화:
- 사용자가 관심 패치 선택 (불가사리의 주황색 부분)
- 각 패치의 ViT Activation을 SAE로 인코딩
- Sparse Representation을 합산하여 Top-k Features 선택
- 해당 특징을 최대화하는 훈련 이미지들 검색
- 결과: 비슷한 색상과 질감의 불가사리 이미지들 발견
- 6단계 개입 과정:
- Encode and Reconstruct:
- Reconstruction Error 계산:
의 개별 값을 수정하여 생성 - 수정된 Activation 재구성:
- Error 추가:
- 출력 비교:
vs
- Encode and Reconstruct:
Method 검증
CLIP Vs DINOv2 비교 분석: 문화적 이해
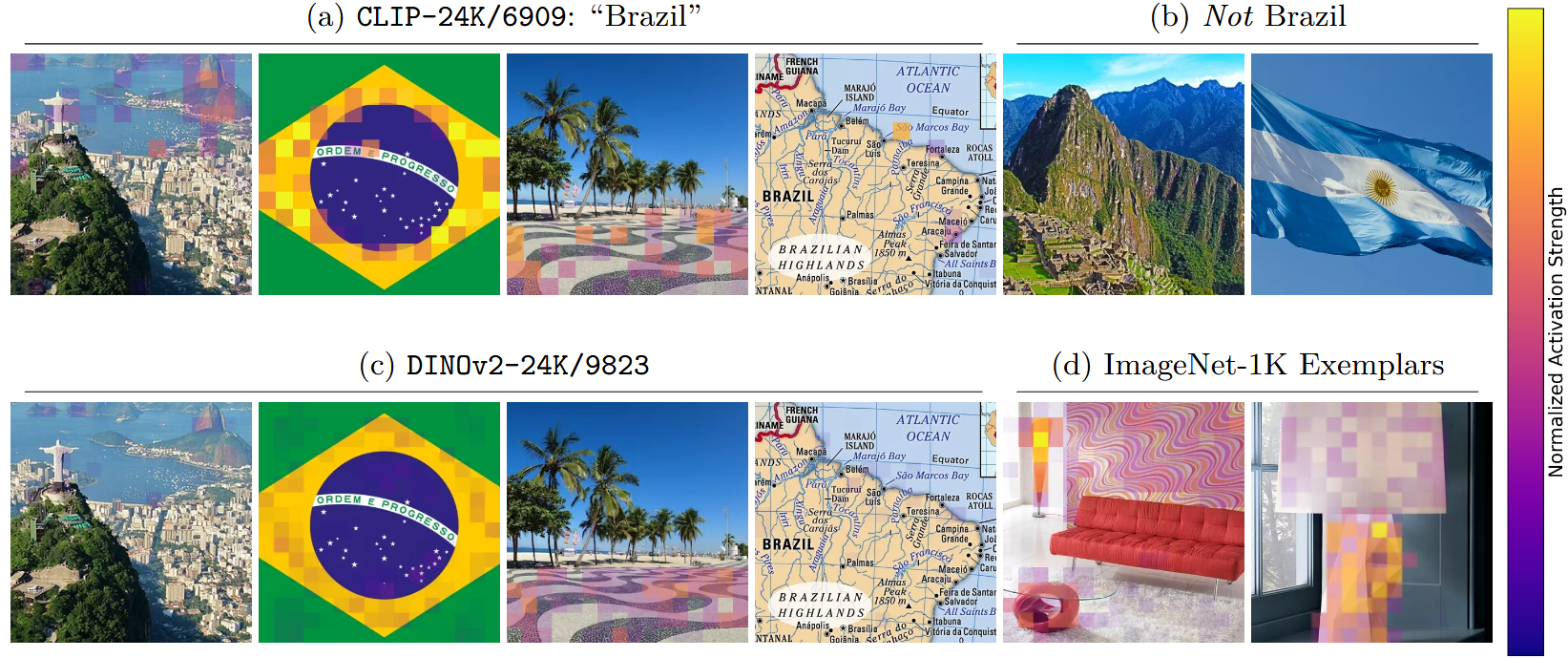
- "Brazil" 특징의 학습 차이를 보여줌:
- (a) CLIP-24K/6909: 브라질 관련 다양한 이미지에서 활성화
- Rio de Janeiro 도시 풍경, 브라질 국기
- Copacabana Beach의 상징적인 물결 타일 패턴
- 브라질 지도, 해변 풍경
- (b) Not Brazil: Machu Picchu나 아르헨티나 국기에는 반응하지 않음
- (c) DINOv2-24K/9823: 브라질 이미지에 일부 반응
- (d) ImageNet-1K Exemplars: 하지만 최대 활성화 예시는 램프 이미지들
- (a) CLIP-24K/6909: 브라질 관련 다양한 이미지에서 활성화
- CLIP은 문화적 심볼을 통합적으로 학습, DINOv2는 시각적 패턴만 학습
Style-Agnostic Semantic Abstraction

- "사고/충돌" 개념의 추상적 학습을 보여줌:
- CLIP-24K/20652:
- 실제 자동차 사고 사진
- 비행기 추락 장면
- 만화 스타일의 충돌 묘사
- 손상된 금속 구조물
- 시각적 스타일을 초월한 "사고" 개념 포착
- DINOv2-24K/9672:
- 일부 사고 이미지에 반응하지만 일관성 없음
- ImageNet 예시는 "사고"와 무관한 이미지들
- CLIP-24K/20652:
Fine-Grained Classification 실험

- 과학적 방법론의 완전한 시연:
- Observe: CLIP이 "Blue Jay" 예측
- Hypothesis: 새의 날개 선택 → SAE가 "Blue Feathers" 특징 제안
- Experiment:
- Sparse Feature Space에서 "Blue Feathers" 값을 -5로 설정
- 다른 특징은 유지
- 결과: "Clark's Nutcracker"로 예측 변경
- 파란 깃털만 없는 유사한 새로 의미있는 변화
- 특징의 인과적 역할 검증
Semantic Segmentation 실험

- 공간적 특징 조작의 독립성 시연:
- Original Prediction: Sky, Tree, Palm Tree, Sand, Sea, Mountain
- Sand 패치 선택 → SAE가 "Sand" 특징 예시 제공
- "Sand" 특징 전체 억제 후:
- Sand → "Earth, Ground" 또는 "Water"로 변경
- 다른 클래스들은 영향받지 않음
- Sky, Tree, Mountain 등은 그대로 유지
- SAE 특징들의 Pseudo-Orthogonality 입증
주요 통찰과 시사점
- Language Supervision의 효과:
- CLIP은 문화적 개념(브라질), 추상적 의미(사고) 학습
- 시각적 스타일을 초월한 Human-Like Abstraction
- Pure Visual Training의 한계:
- DINOv2는 저수준 시각적 패턴에 집중
- 의미적 통합 부재
- SAE의 장점:
- 해석 가능한 특징 발견과 정밀한 조작 동시 가능
- 기존 모델에 Plug-and-Play 방식 적용
- 특징 간 독립적 조작으로 복잡한 개입 실험 가능