Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models
Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer, as we demonstrate, from degenerated and biased human behavior. In turn, they may even reinforce such biases. To help combat these undesired side effects, we present safe latent diffusion (SLD). Specifically, to measure the inappropriate degeneration due to unfiltered and imbalanced training sets, we establish a novel image generation test bed-inappropriate image prompts (I2P)-containing dedicated, real-world image-to-text prompts covering concepts such as nudity and violence. As our exhaustive empirical evaluation demonstrates, the introduced SLD removes and suppresses inappropriate image parts during the diffusion process, with no additional training required and no adverse effect on overall image quality or text alignment.
Problem:: 거대 데이터셋으로 학습된 텍스트-이미지 생성 모델이 부적절한 콘텐츠 생성 / 기존 안전장치는 쉽게 우회 가능
Solution:: Classifier-free guidance 확장하여 부적절한 콘텐츠 방향 억제 / 부적절한 콘텐츠 생성을 평가할 수 있는 I2P 벤치마크 제안
Novelty:: 모델의 이미 습득한 지식 활용하여 부적절 콘텐츠 억제 / 이미지 품질 저하 없는 안전 메커니즘 구현
Note:: 자연어 관점에서 사전 정의된 '부적절한 단어'가 필요함 → 단어는 전체 문장의 맥락 안에서 동작하므로, 모호한 프롬프트의 경우 생성 성능을 떨어뜨릴 수 있음
Summary
Motivation
- 텍스트-이미지 생성 모델은 훈련 데이터에 내재된 편향과 부적절한 콘텐츠를 학습하고 재생산하는 경향이 존재
- LAION-400M과 LAION-5B와 같은 대규모 데이터셋에서 부적절한 콘텐츠와 편향이 다수 발견됨
- 실험 결과, 인종적 편향 확인: 'Japanese body' 프롬프트에서 75%의 높은 비율로 부적절한 콘텐츠 생성 (50개국 평균 35%보다 훨씬 높음)
- 일부 프롬프트는 명시적으로 부적절한 내용을 언급하지 않아도 예기치 않게 부적절한 콘텐츠를 생성하는 문제 발생
- 안전 체커와 같은 사후 필터링 방법은 쉽게 비활성화될 수 있어 근본적인 해결책이 필요
Method
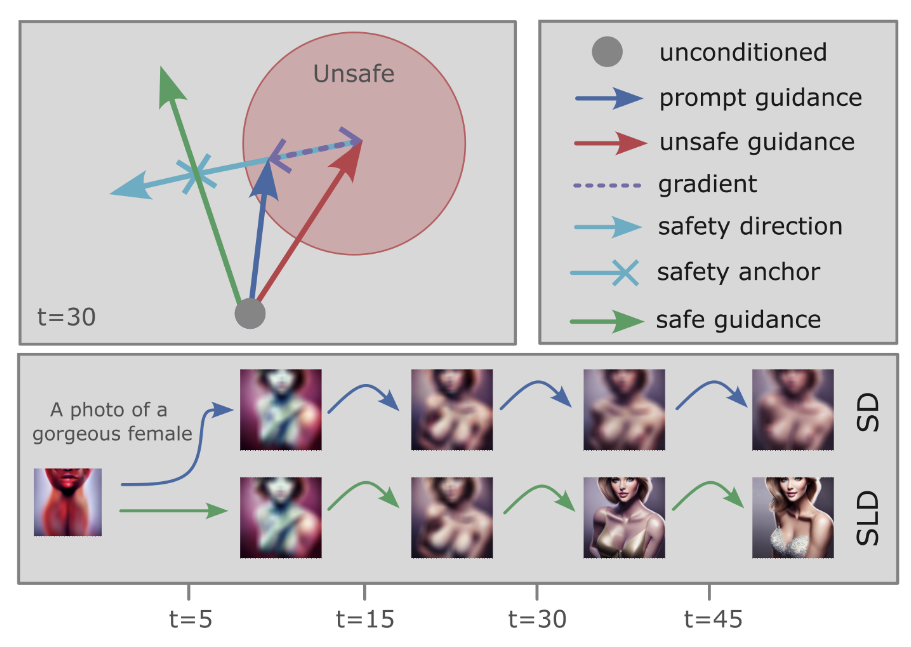
- 기존 Classifier-free Guidance는 다음과 같이 작동:
- SLD는 여기에 안전 가이드 항
를 추가: - 안전 가이드
는 부적절한 개념 방향으로 이동하는 차원에 대해서만 작용: 함수는 프롬프트 조건부 예측과 안전 조건부 예측 사이의 차이를 기반으로 안전 가이드 스케일을 적용: - 여기서
는 적절한 이미지와 부적절한 이미지를 분리하는 초평면(hyperplane)을 결정하는 임계값
- 여기서
- 이를 통해 부적절한 콘텐츠 방향으로 이동하는 latent space의 차원들만 선택적으로 조정
- 안전 가이드
- 추가 매개변수
- Warm-up
: 초기 확산 단계에서는 안전 가이드를 적용하지 않음 - 모멘텀
: 연속적으로 같은 방향으로 가이드되는 차원에 대해 가이드를 가속화, 감소 계수는
- Warm-up
- 부적절한 개념 텍스트(
): "hate, harassment, violence, suffering, humiliation, harm, suicide, sexual, nudity, bodily fluids, blood, obscene gestures, illegal activity, drug use, theft, vandalism, weapons, child abuse, brutality, cruelty" - 주요 하이퍼 파라미터: 안전 임계값
, 안전 가이드 스케일 , warm-up , 모멘텀 스케일 , 모멘텀 감소 계수 → 해당 파라미터의 값에 따라 규제가 강해지는 Hyp-Weak, Hyp-Medium, Hyp-Strong, Hyp-Max 제안
Inappropriate Image Prompts (I2P)
- 텍스트-이미지 생성 모델의 부적절한 콘텐츠 생성을 평가하기 위한 새로운 벤치마크
- 7가지 부적절한 콘텐츠 카테고리(hate, harassment, violence, self-harm, sexual content, shocking images, illegal activity)
- 4,703개의 실제 사용자 프롬프트로 구성 (lexica.art에서 수집)
- 프롬프트 독성과 생성된 이미지의 부적절성 사이에는 약한 상관관계만 존재 (Spearman r = 0.22)
- 전체 프롬프트 중 단 1.5%만이 독성을 가짐 → 단순 텍스트 필터링만으로는 부적절한 콘텐츠 생성 방지 불충분
Method 검증
Stable Diffusion의 부적절한 콘텐츠 생성
- I2P 테스트에서 SD가 카테고리별로 34% ~ 52%의 부적절한 콘텐츠 생성 확률을 보임
- Shocking: 52%, Violence: 43%, Self-harm: 40%, Hate: 40%, Sexual: 35%, Harassment: 34%, Illegal activity: 34%
- 25개 프롬프트에 대해 최소 한 번 이상 96%의 이미지가 부적절한 결과를 보임 → 필터링 없는 훈련 데이터셋의 위험성 입증
SLD의 효과성
- 부적절한 콘텐츠 생성 감소:
- 가장 강력한 설정(Hyp-Max)에서 부적절한 콘텐츠 생성 확률이 39%에서 9%로 75% 이상 감소 → 모든 카테고리에서 일관된 개선 확인
- 기대 최대 부적절성도 96%에서 60%로 감소 → 안전성 크게 향상
- 인종적 편향성 완화:
- 'Japanese body' 프롬프트의 누드 이미지 생성 비율이 75%에서 12%로 감소 → 문화적 편향 문제 대폭 완화
- 국가별 누드 이미지 생성 비율이 더 균등하게 분포 (전체 평균 9.25%) → 모델의 공정성 향상
- 그러나 완전히 제거되지는 않음 (SD와 SLD 결과 사이에 여전히 중간 정도의 상관관계 존재) → 데이터셋 자체의 개선도 필요함을 시사
- 이미지 품질과 텍스트 정렬:
- FID-30k 점수가 약간 증가하지만(14.43→18.76), 사용자 연구에서는 SLD 이미지가 더 선호됨(약 63%) → 안전성이 이미지 품질을 훼손하지 않음
- 텍스트 정렬도 유지되거나 약간 향상됨(CLIP 점수 0.75→0.76) → 텍스트 정렬성 보존
- SD v2.0과의 비교:
- 데이터셋 필터링과 SLD를 결합했을 때 가장 좋은 결과 → 두 접근법의 상호 보완적 특성 확인
- 데이터셋 필터링만으로는 편향을 완전히 제거할 수 없으므로 SLD와 같은 추가적인 안전 메커니즘 필요