Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders
We address the problem of gaze target estimation, which aims to predict where a person is looking in a scene. Predicting a person's gaze target requires reasoning both about the person's appearance and the contents of the scene. Prior works have developed increasingly complex, hand-crafted pipelines for gaze target estimation that carefully fuse features from separate scene encoders, head encoders, and auxiliary models for signals like depth and pose. Motivated by the success of general-purpose feature extractors on a variety of visual tasks, we propose Gaze-LLE, a novel transformer framework that streamlines gaze target estimation by leveraging features from a frozen DINOv2 encoder. We extract a single feature representation for the scene, and apply a person-specific positional prompt to decode gaze with a lightweight module. We demonstrate state-of-the-art performance across several gaze benchmarks and provide extensive analysis to validate our design choices. Our code is available at: http://github.com/fkryan/gazelle
Problem:: 시선 타겟 예측에는 사람의 외모와 장면 콘텐츠에 대한 복합적 추론이 필요함/기존 방식은 복잡한 수작업 파이프라인으로 Scene Encoder, Head Encoder, 깊이/포즈 보조 모델 등의 특징을 별도로 융합함
Solution:: DINOv2 인코더의 고정된 특징을 활용한 Transformer 프레임워크 Gaze-LLE 제안/장면에 대한 단일 Feature Representation 추출 및 Person-Specific Positional Prompt 적용
Novelty:: 복잡한 수작업 Pipeline 대신 General-Purpose Feature Extractor 활용/단일 특징 표현과 Lightweight 디코딩 모듈을 통한 간소화/Person-Specific Positional Prompt를 통한 효과적인 시선 디코딩
Note:: 코드는 GitHub에서 공개 (http://github.com/fkryan/gazelle)
Summary
Motivation
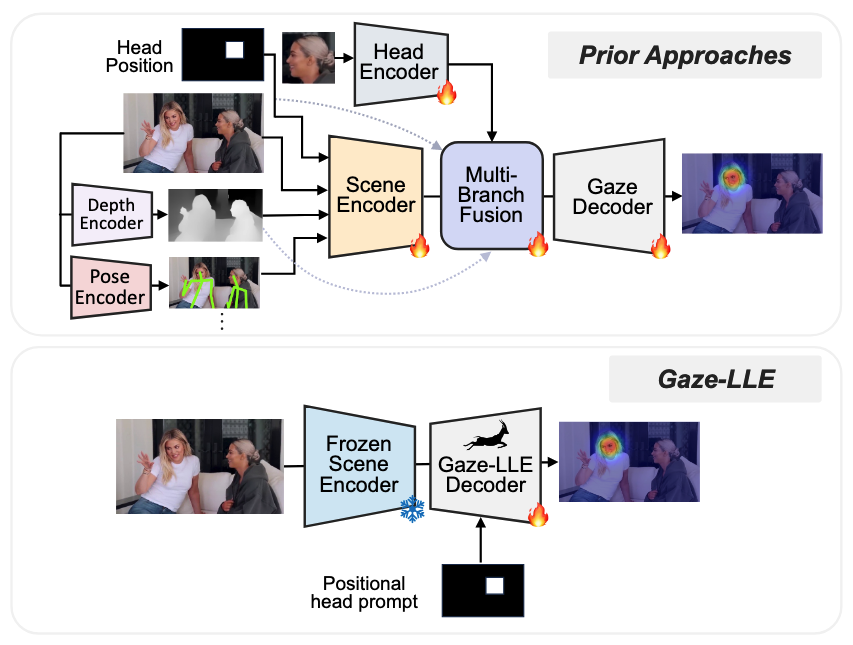
- Gaze Target Estimation은 사람이 장면에서 어디를 보고 있는지 예측하는 작업
- 이 작업은 사람의 외모와 장면 내용 모두에 대한 복합적인 추론 필요
- 기존 연구들은 점점 더 복잡해지는 수작업 Pipeline 개발
- Scene Encoder, Head Encoder 특징 분리
- Depth와 Pose 같은 신호를 위한 보조 모델 사용
- 복잡한 방식으로 다양한 특징 정보 융합
- 다양한 시각 작업에서 General-Purpose Feature Extractor의 성공에 영감을 받아 새로운 접근법 필요
Method
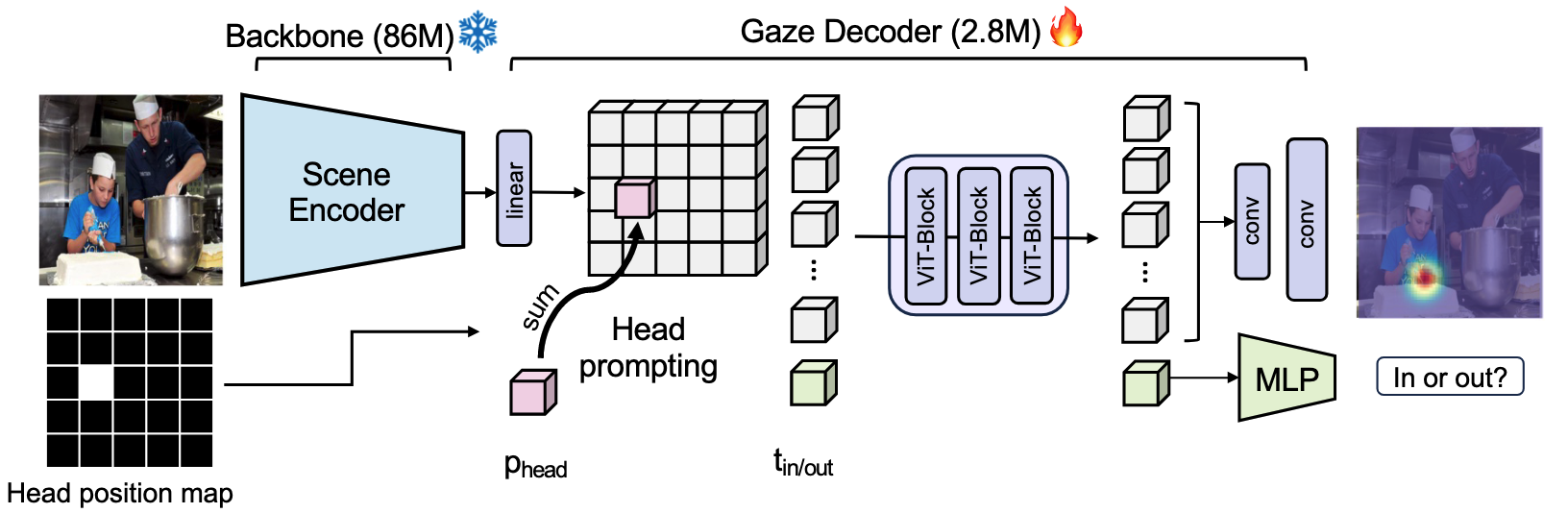
- Frozen DINOv2 Encoder의 특징을 활용하는 Transformer 프레임워크인 Gaze-LLE 제안
- 장면에 대한 단일 Feature Representation 추출
- 복잡한 다중 인코더 구조 대신 단일 인코더 활용
- 전체 이미지에서 관련 특징을 효과적으로 추출
- Person-Specific Positional Prompt 적용
- 각 인물에 맞춘 위치 정보 활용
- 시선 디코딩 과정에서 인물의 위치와 자세 정보 반영
- Lightweight Module을 통한 효율적인 시선 디코딩
- 복잡한 파이프라인 대신 경량화된 디코딩 구조
- 계산 효율성과 정확도 향상
Method 검증
벤치마크 성능
- GazeFollow 데이터셋에서 AUC 0.926 달성, 기존 SOTA 대비 1.5% 향상 → 단일 DINOv2 Encoder만으로도 복잡한 다중 인코더 방식보다 우수한 성능 달성 가능함을 입증
- VideoAttentionTarget 데이터셋에서 L2 거리 0.134 달성, 기존 방식 대비 12% 개선 → 시간적 정보가 있는 비디오 데이터에서도 효과적으로 작동함을 보여줌
- 모든 테스트 환경에서 계산량과 파라미터 수 크게 감소 → 간소화된 아키텍처가 효율성과 성능 모두에서 이점이 있음을 확인
- 인간 주석자 수준의 성능(Human Performance) 근접 → 제안된 방법이 실제 응용에서 실용적으로 사용될 수 있음을 시사
Ablation Study
- Person-Specific Positional Prompt 제거 시 AUC 3.2% 하락 → 인물의 공간적 맥락이 시선 예측에 중요한 요소임을 증명

그래도 Feature가 너무 좋아서, 사람이 적은 경우 Head 위치가 주어지지 않아도 유의미한 결과를 보임
- DINOv2를 다른 Encoder(ResNet, CLIP)로 대체 시 성능 감소 → Self-Supervised Learning 기반 DINOv2가 시선 예측에 필요한 특징 추출에 더 적합함을 확인
- DINOv2의 다양한 레이어 실험 결과, 중간 레이어(9-10)가 최적의 성능 → 저수준 특징과 고수준 특징 간의 균형이 중요함을 시사
- Decoder 구조 변형 실험에서 제안된 Lightweight Module이 최적의 Trade-off 제공 → 과도한 파라미터가 오히려 일반화 성능을 저하시킬 수 있음을 보여줌
- End-to-End 학습 vs Frozen Encoder 비교에서 Frozen Encoder가 더 효과적 → 대규모 사전학습 모델의 지식 활용이 소규모 데이터셋에서 유리함을 입증