Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Concept Bottleneck Models (CBMs) have recently been proposed to address the 'black-box' problem of deep neural networks, by first mapping images to a human-understandable concept space and then linearly combining concepts for classification. Such models typically require first coming up with a set of concepts relevant to the task and then aligning the representations of a feature extractor to map to these concepts. However, even with powerful foundational feature extractors like CLIP, there are no guarantees that the specified concepts are detectable. In this work, we leverage recent advances in mechanistic interpretability and propose a novel CBM approach -- called Discover-then-Name-CBM (DN-CBM) -- that inverts the typical paradigm: instead of pre-selecting concepts based on the downstream classification task, we use sparse autoencoders to first discover concepts learnt by the model, and then name them and train linear probes for classification. Our concept extraction strategy is efficient, since it is agnostic to the downstream task, and uses concepts already known to the model. We perform a comprehensive evaluation across multiple datasets and CLIP architectures and show that our method yields semantically meaningful concepts, assigns appropriate names to them that make them easy to interpret, and yields performant and interpretable CBMs. Code available at https://github.com/neuroexplicit-saar/discover-then-name.
Problem:: 기존 Concept Bottleneck Model은 사람이 특정 과제에 맞춰 사전에 개념을 정의해야 함 / 정의된 개념을 모델이 실제로 탐지할 수 있다는 보장이 없어 설명의 충실도(Faithfulness)에 문제가 생길 수 있음 /새로운 Task마다 개념을 다시 정의하고 학습해야 해 비효율적
Solution:: Sparse Autoencoder를 이용해 Task-Agnostic하게 모델이 이미 학습한 개념들을 자동으로 발견 / SAE의 Decoder 가중치와 CLIP의 텍스트 임베딩 간 유사도를 측정하여 발견된 각 개념에 자동으로 이름을 부여함 / 완성된 개념을 고정시킨 뒤 선형 분류기만 추가하여 과제를 수행
Novelty:: 사람이 개념을 정의하고 모델을 맞추는 것이 아닌, 모델이 아는 개념을 먼저 발견하고 후에 이름을 붙이는 역발상적 'Discover-then-Name' 패러다임 / 특정 과제와 무관하게(Task-Agnostic) 한 번만 개념을 추출하면 여러 과제에 재사용할 수 있는 효율성 / Sparse Autoencoder의 'Decoder 가중치'를 직접 CLIP 텍스트 임베딩과 매칭하여 개념을 자동으로 명명하는 새로운 기법 / 과제마다 LLM에 물어볼 필요 없이 범용적인 개념 집합을 구축함
Note:: 핵심은 잘 정의된 언어 임베딩들을 컨셉으로 이용하는 것 / 언어적으로 이해할 수 없지만 모델 입장에서 이해하기 쉬운 개념들이 존재한다면 해석 가능성은 낮아도 성능은 향상시킬 수 있을까?
Summary
Motivation
- 기존 CBM은 특정 작업에 맞춰 사람이 먼저 개념을 정의하고 모델을 학습시켜야 했음
- 사전 정의된 개념이 Feature Extractor에 의해 실제로 탐지될 수 있다는 보장이 부재
- 각기 다른 Downstream Task에 대해 매번 새로운 개념 집합을 정의하고 모델을 학습해야 하는 비효율성이 발생
- 따라서, 모델이 이미 알고 있는 개념을 먼저 발견하고, 그 후 발견된 개념에 이름을 부여하여 더 충실하고 효율적인 CBM을 만들고자 함
Method
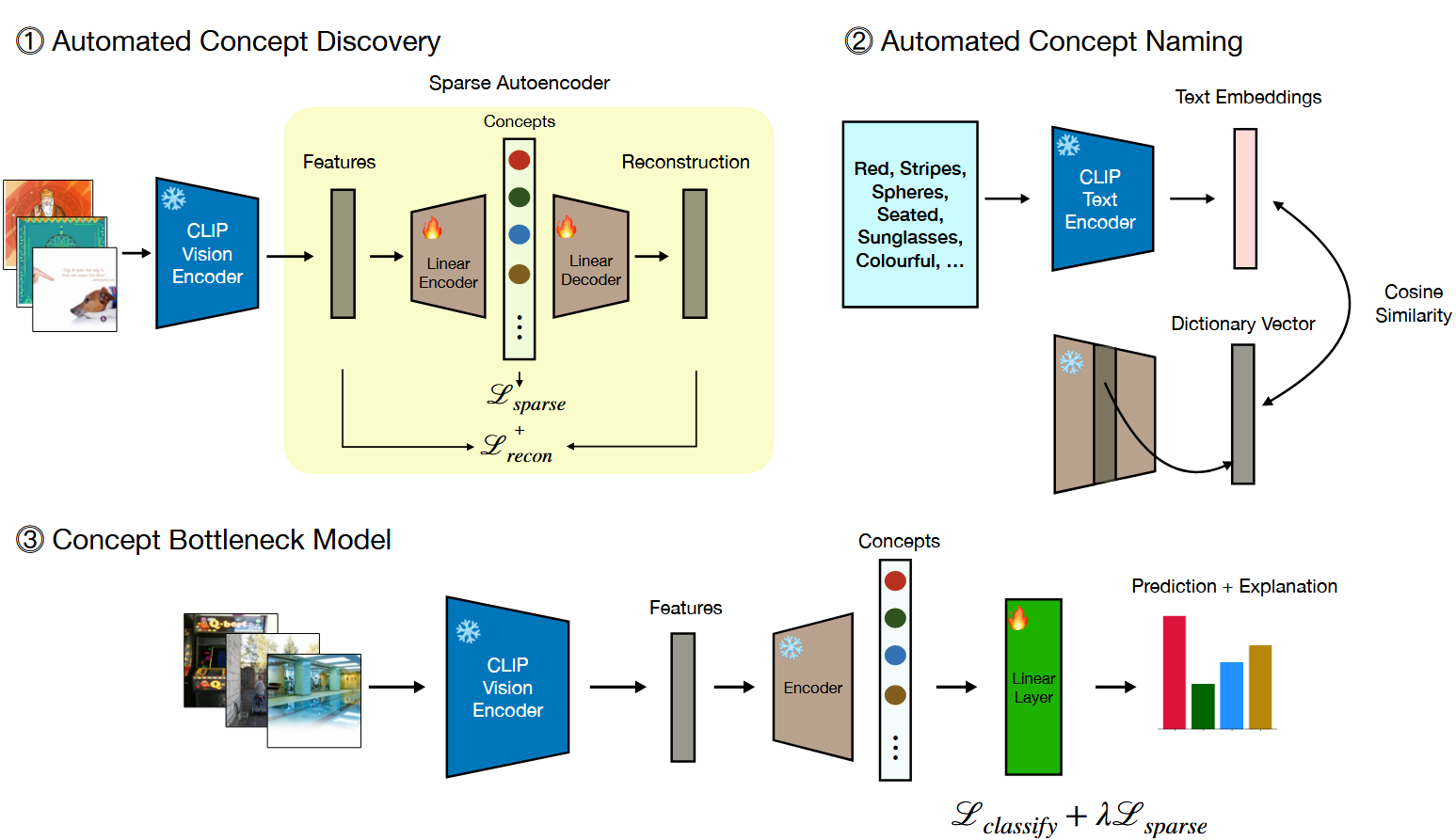
DN-CBM의 전체 파이프라인은 Automated Concept Discovery, Automated Concept Naming, Concept Bottleneck Model의 3단계로 구성됨
-
1. Automated Concept Discovery
- CLIP Vision Encoder에서 추출된 Feature를 입력받아, 희소하지만 더 높은 차원의 공간으로 표현하는 Sparse Autoencoder (SAE) 학습
- SAE는 원본 Feature를 잘 복원하면서(
Reconstruction Loss), 동시에 은닉층의 활성화(Concept)가 희소(Sparse)해지도록( Sparsity Loss) 학습
- 이 과정은 레이블 없는 대규모 데이터셋(CC3M)으로 학습되며 특정 작업에 종속되지 않음 (Task-Agnostic함).
-
2. Automated Concept Naming
- 학습된 SAE의 Decoder 가중치 행렬(
)의 각 열 벡터( ) 를 개별 개념에 해당하는 것으로 간주 - CLIP의 Text-Image 정렬 특성을 활용하여, 각 개념 벡터(
)와 가장 높은 Cosine Similarity를 가지는 Text Embedding을 대규모 어휘 집합( )에서 찾아 해당 개념의 이름( )으로 부여
- 학습된 SAE의 Decoder 가중치 행렬(
-
3. Concept Bottleneck Model Construction
- 이전 과정에서 학습되고 명명된 개념 추출기(SAE)는 고정(Freeze)함
- SAE가 출력하는 희소한 개념 활성화 값을 입력으로 받아, 특정 Downstream Task를 수행하는 새로운 희소 선형 분류기(Sparse Linear Classifier)를 학습
- Cross-Entropy Loss와 가중치에 대한
Sparsity Loss를 함께 사용하여 해석 가능성을 높임
Method 검증
- 실험 1: Task-Agnosticity and Accuracy of Concepts (Qualitative)

- 실험 진행 방법: SAE로 발견하고 명명한 각 개념에 대해, 4개의 다른 데이터셋(ImageNet, CIFAR10, CIFAR100, Places365)에서 해당 개념을 가장 강하게 활성화하는 이미지를 시각화하여 비교
- 정성적 성능: 'asleep', 'sunglasses', 'stripes' 같은 개념들이 데이터셋 종류와 무관하게 이름과 매우 일관성 있는 이미지들을 활성화
- 통찰: 제안 방식이 Task-Agnostic하게 다양한 데이터셋에 걸쳐 의미적으로 일관되고 강건한 개념을 발견할 수 있음을 보여줌
- 실험 2: Concept Accuracy (Quantitative User Study)
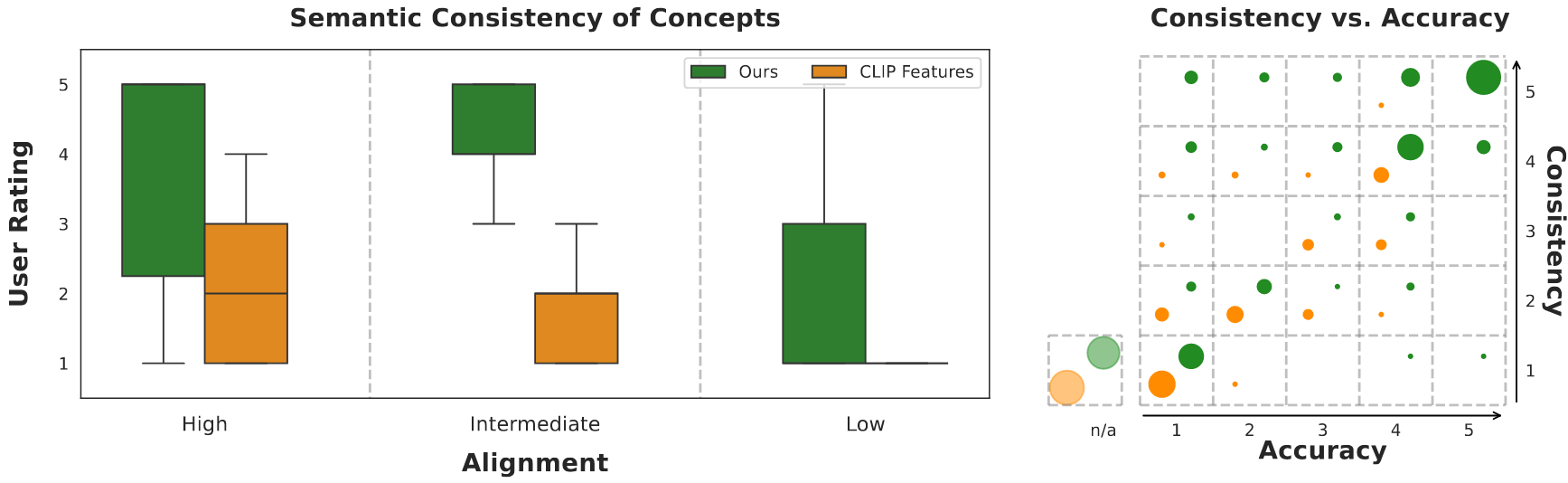
- 실험 진행 방법: DN-CBM이 발견한 개념과 Baseline(CLIP-Dissect)이 CLIP Feature에서 직접 추출한 개념에 대해, 사용자가 (1) 의미적 일관성, (2) 이름의 정확도를 5점 척도로 평가
- 정량적 성능: DN-CBM의 개념이 Baseline에 비해 의미적 일관성과 이름 정확도 양쪽에서 모두 훨씬 높은 점수를 받음
- 통찰: SAE를 통해 개념을 추출하는 것이 CLIP의 Raw Feature에서 직접 추출하는 것보다 훨씬 더 분리되고 인간이 이해하기 쉬운 개념을 생성함을 의미
- 실험 3: Impact of Vocabulary on Concept Name Granularity

- 실험 진행 방법: 어휘 집합에 더 세분화된 이름(e.g., 'arch bridge')을 추가하거나, 기존 이름(e.g., 'bridge')을 제거했을 때 개념 이름의 변화를 확인
- 정성적 성능: 세분화된 이름을 추가하면 더 정확한 이름이 할당되었고, 기존 이름을 제거하면 덜 정확한 이름이 할당됨
- 통찰: 개념 명명에 사용되는 어휘 집합의 크기와 세분성이 이름의 정확도에 큰 영향을 미치며, 이를 통해 사용자가 원하는 수준으로 개념의 세분성을 조절할 수 있음을 시사
- 실험 4: DN-CBM Classification Performance
- 실험 진행 방법: 4개 분류 데이터셋에서 DN-CBM의 정확도를 Task-Specific하게 설계된 다른 CBM Baseline(LF-CBM, LaBo, CDM 등)과 비교
- 정량적 성능: DN-CBM이 Task-Agnostic 접근 방식임에도 불구하고, 대부분의 경우 Task-Specific Baseline들의 성능을 능가했으며, 특히 Places365 데이터셋에서 가장 큰 성능 향상을 보임 (ResNet-50 기준, 52.70% → 53.53%)
- 통찰: 제안된 Task-Agnostic 개념 발견 방식이 매우 일반적이고 효과적이어서, 별도의 Task별 개념 엔지니어링 없이 높은 성능의 분류기를 만들 수 있음을 증명
- 실험 5: Effectiveness of Concept Interventions
- 실험 진행 방법: Waterbirds 데이터셋(배경과 새 종류 간의 허위 상관관계 존재)에 학습된 DN-CBM에서 (1) 새 관련 개념만 남기거나, (2) 새 관련 개념만 제거하는 개입을 수행하여 성능 변화를 측정함.
- 정량적 성능: 새 관련 개념만 남겼을 때, Worst Group 정확도가 15.3%p 크게 향상되었고, 반대로 새 관련 개념을 제거하자 전체 정확도가 22.0%p 급락함.
- 통찰: 발견된 개념들이 모델의 결정에 의미 있게 인과적으로 관여하고 있음을 보여주며, 이를 통해 모델의 잘못된 추론을 수정하는 등 디버깅에 효과적으로 사용될 수 있음.
- 실험 6: Clustering Concept Vectors

- 실험 방법: Places365 데이터셋의 모든 이미지에 대한 개념 활성화 벡터들을 K-Means 알고리즘을 사용하여 클러스터링
- 결과: 의미적으로 유사한 개념과 관련 이미지들이 성공적으로 같은 클러스터로 그룹화됨을 확인함 (e.g., 'farming', 'fields' 등의 개념이 농업 관련 이미지들과 함께 클러스터 형성)
- 통찰: SAE가 학습한 잠재 개념 공간이 의미적으로 잘 구조화되어 있음을 증명하며, 발견된 개념들의 질이 높다는 것을 뒷받침함
- 실험 7: Interpretability of DN-CBM (Qualitative)
- Local Explanations (개별 이미지 설명)
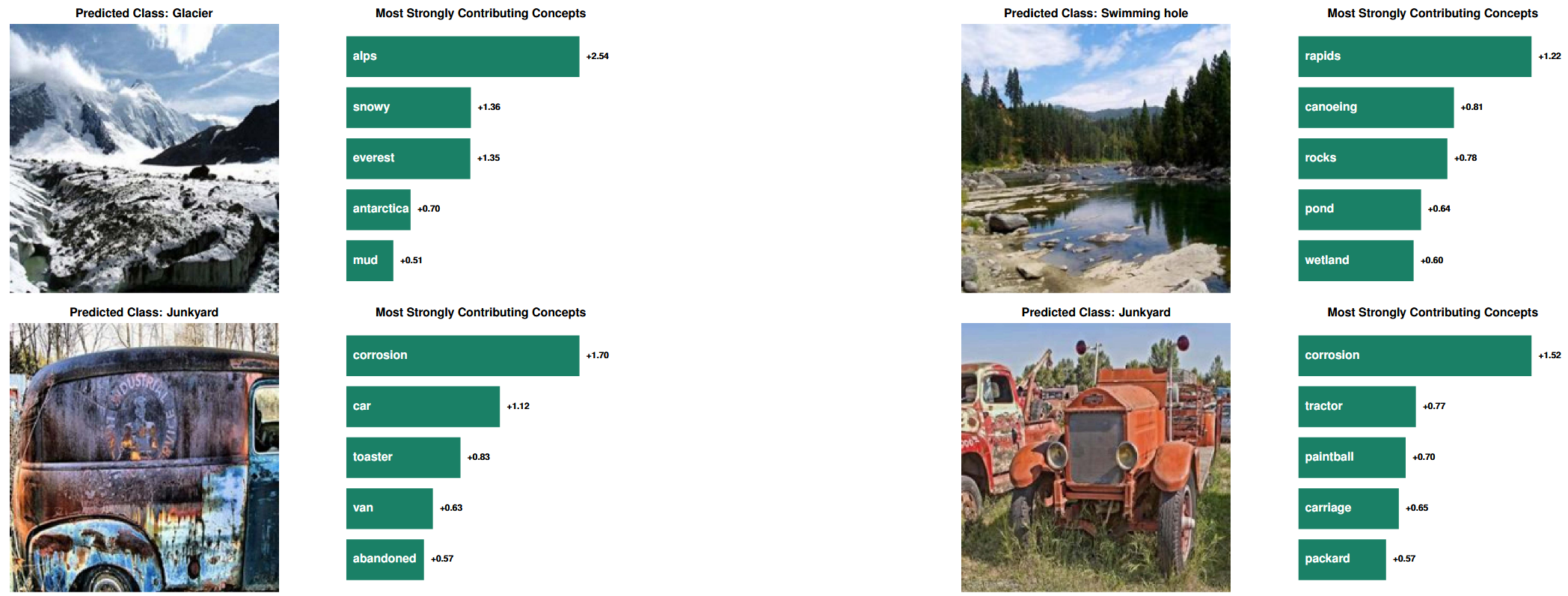
- 분석 내용: 모델이 특정 이미지를 어떻게 분류했는지, 가장 큰 영향을 미친 상위 개념들을 시각화하여 분석
- 결과 및 통찰: 단순히 이미지에 존재하는 객체('rocks')뿐만 아니라, 시각적으로 유사한 특징('toaster'의 외형), 고수준의 추상적 개념('abandoned'), 연관된 장소('alps') 등 다양한 종류의 개념을 활용하여 예측함을 확인
- Comparison with Baselines (타 CBM과 설명 비교)]
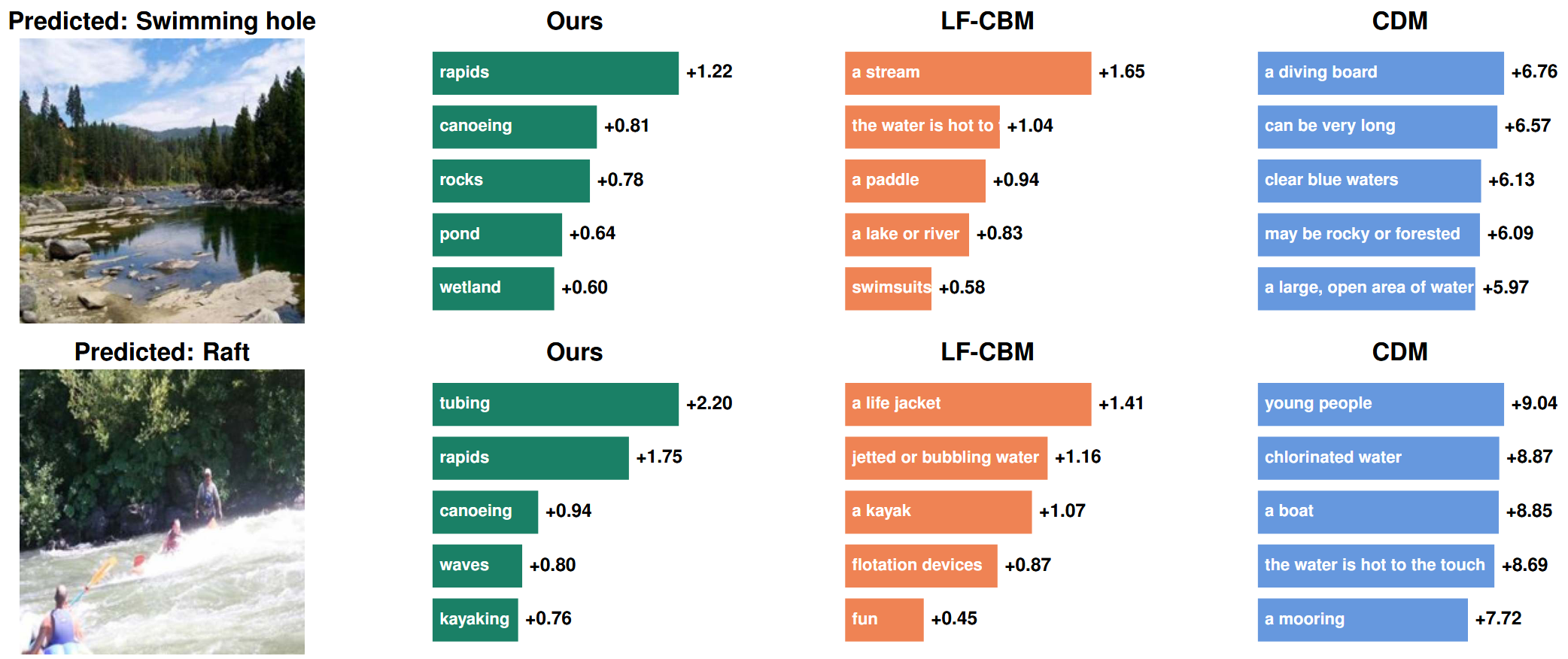
- 분석 내용: 동일한 이미지에 대한 DN-CBM의 설명을 LF-CBM, CDM과 같은 다른 최신 CBM들의 설명과 정성적으로 비교
- 결과 및 통찰: DN-CBM은 Task에 맞춰 개념을 최적화하지 않는 Task-Agnostic 방식임에도 불구하고, 다른 최신 CBM들과 유사한 수준의 설득력 있는 설명을 제공
- Global Explanations (클래스 단위 설명)

- 분석 내용: 특정 클래스 전체에 대해 가장 큰 평균 기여도를 보인 상위 개념들을 시각화하여, 모델이 해당 클래스를 어떻게 이해하는지 분석
- 결과 및 통찰: 클래스별 상위 개념들이 해당 클래스의 내용과 의미적으로 매우 일관성 있음을 확인함 (e.g., 'Amusement park' 클래스에 'playground', 'wheel', 'carnival' 등이 기여)
- Local Explanations (개별 이미지 설명)