D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
We introduce D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD). FDR transforms the regression process from predicting fixed coordinates to iteratively refining probability distributions, providing a fine-grained intermediate representation that significantly enhances localization accuracy. GO-LSD is a bidirectional optimization strategy that transfers localization knowledge from refined distributions to shallower layers through self-distillation, while also simplifying the residual prediction tasks for deeper layers. Additionally, D-FINE incorporates lightweight optimizations in computationally intensive modules and operations, achieving a better balance between speed and accuracy. Specifically, D-FINE-L / X achieves 54.0% / 55.8% AP on the COCO dataset at 124 / 78 FPS on an NVIDIA T4 GPU. When pretrained on Objects365, D-FINE-L / X attains 57.1% / 59.3% AP, surpassing all existing real-time detectors. Furthermore, our method significantly enhances the performance of a wide range of DETR models by up to 5.3% AP with negligible extra parameters and training costs. Our code and pretrained models: https://github.com/Peterande/D-FINE.
Problem:: 고정된 좌표값 예측은 불확실성 모델링이 어려움/기존 분포 기반 방식들은 앵커가 필요함/기존 분포 기반 방식들은 최대 거리가 고정이라 작은 물체에 취약/분포 방식의 Bin 크기가 고정/Localization Distillation은 효과적이나 앵커가 필요함
Solution: 초기 Fix Coord Head로 최대 거리 예측 + D-Fine Head로 분포 예측/각 Bin의 크기를 변화가 적으면 작게, 크면 크게 수정/앵커 없이 각 Decoder Layer에 Self-Distillation 적용
Novelty:: Anchor-Free 방식인 DETR 계열에 Anchor를 요구하던 분포 기반 예측 및 Localization Distillation 적용
Note:: ICLR 2025 Spotlight으로 기존 연구들의 아이디를 잘 가져와서 변형한 연구
Summary
Motivation
- 객체 감지에서 바운딩 박스 회귀 방식의 한계:
- 고정된 좌표값 예측(Dirac delta distribution)으로 위치 불확실성 모델링 어려움
- L1 손실과 IoU 손실에 제한되어 각 에지 독립적 조정에 불충분한 가이드 제공
- 작은 좌표 변화에 최적화 과정이 민감하게 반응하여 수렴 속도 저하 및 성능 저하
- 기존 방식(GFocal)의 한계:
- 앵커 의존성으로 예측 다양성 및 앵커 프리 프레임워크와의 호환성 제한
- 반복적 개선 없이 한 번에 예측하여 회귀 견고성 감소
- 고정된 거리 범위와 균일한 빈 간격으로 특히 작은 객체에서 정밀한 위치 파악 어려움
- Knowledge Distillation(KD)의 한계:
- Logit Mimicking, Feature Imitation 등 전통적 KD 방법은 객체 감지에 비효율적
- Localization Distillation(LD)이 효과적이지만 앵커 기반 아키텍처에 의존하고 학습 비용 증가
Method
Fine-grained Distribution Refinement (FDR)
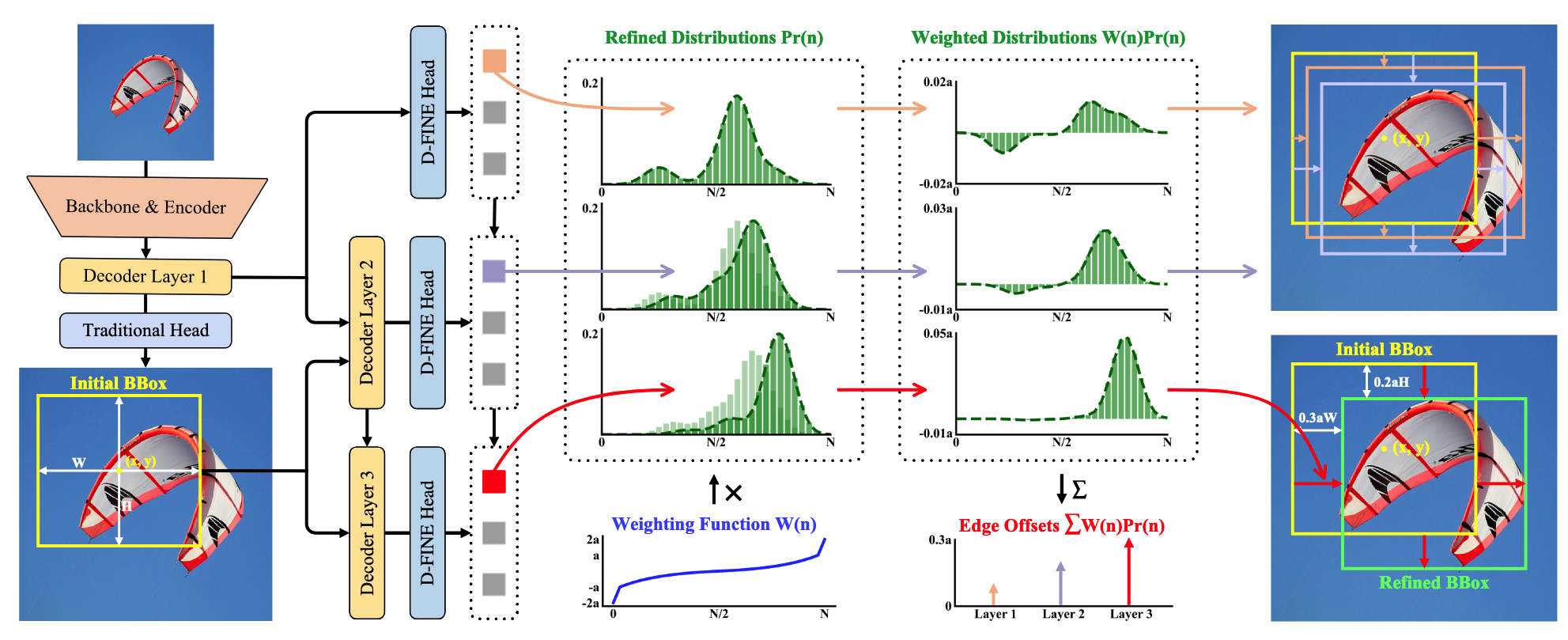
- 디코더 레이어별 작동 방식:
- 첫 번째 레이어: 전통적인 바운딩 박스 회귀 헤드와 D-FINE 헤드로 초기 바운딩 박스 및 확률 분포 예측
- 후속 레이어: Residual 방식으로 이전 레이어의 분포를 반복적으로 개선
- 확률 분포
의 역할: - 각 인덱스
이 현재 바운딩 박스 에지의 오프셋으로 얼마나 유력한지를 나타내는 확률 분포 - 디코더 레이어마다 반복적으로 정제됨 (이전 레이어의
에 residual 를 더해 업데이트)
- 각 인덱스
- 가중치 함수
활용: - 확률 분포를 바운딩 박스의 에지 오프셋으로 변환하는 가중치 함수
- 예측이 정확에 가까울 때는 작은 곡률로 미세 조정 가능
- 예측이 부정확할 때는 에지 근처 큰 곡률과 경계에서의 급격한 변화로 충분한 유연성 제공
- 최종 에지 위치는 모든 빈에 대한 가중 합(
)으로 계산
- 확률 분포를 바운딩 박스의 에지 오프셋으로 변환하는 가중치 함수
Fine-Grained Localization (FGL)
- Distribution Focal Loss(DFL) 기반으로 설계:
와 가장 가까운 두 빈( , )을 사용하여 보간 가중치 계산: , 는 Ground Truth와 초기 예측 사이의 상대적 오프셋:
- 이 가중치들은
가 두 빈 사이 어디에 위치하는지에 따라 결정됨 ( 가 에 가까울수록 가 커짐) - 예측 시에는 전체 분포를 사용하고(
), 학습 시에는 인접 두 빈만 고려하여 연속적 공간에서의 정확한 예측과 분포의 불확실성을 동시에 모델링 - Motivation
- 손실 함수 계산 시 두 인접 빈에만 가중치를 부여하는 이유: 분포를 날카롭게 만들어 정확한 위치 학습
- IoU 기반 가중치로 낮은 불확실성을 가진 분포를 더 집중되게 만들어 정밀한 바운딩 박스 회귀 가능
Global Optimal Localization Self-Distillation (GO-LSD)
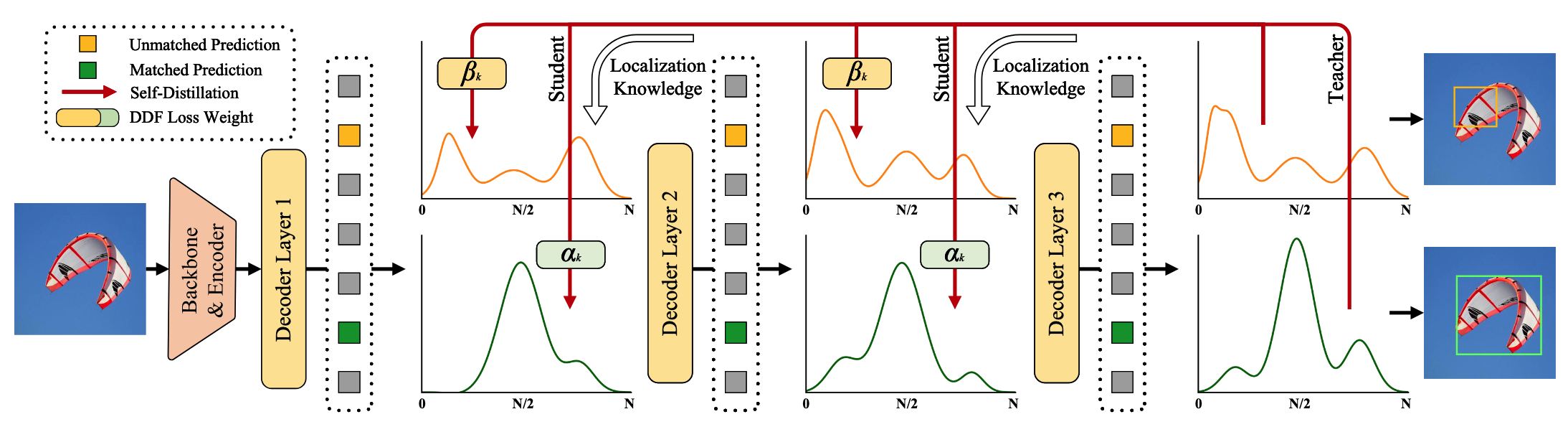
- 마지막 레이어의 정제된 분포에서 얕은 레이어로 위치 지식을 전달하는 양방향 최적화 전략
- Hungarian Matching을 각 레이어 예측에 적용하여 로컬 바운딩 박스 매칭 식별
- 모든 레이어의 매칭 인덱스를 통합된 Union Set으로 집계하여 전역 최적화 수행
- 각 레이어 별로 많이 나타난 매칭쌍이 우선순위로 설정 됨
- Class Score는 Union Set을 통한 매칭이 아닌 마지막 레이어의 인덱스를 이용함 → 중복 방지를 위함
- 매칭되지 않은 예측도 학습 중 최적화하여 전체 안정성 향상
- Decoupled Distillation Focal(DDF) Loss:
- 고 IoU지만 저 신뢰도의 예측에 적절한 가중치 부여
- 매칭된 예측(
)과 매칭되지 않은 예측( )의 수에 따라 가중치 조정: - 이를 통해 안정적이고 효과적인 증류 가능
Bag of Freebies
- 디코더 프로젝션 레이어 제거: 디코더 출력을 예측 헤드에 연결하기 전 변환하는 레이어 제거
- Target Gating Layer 도입: 이전 쿼리(
)와 크로스 어텐션 결과( )를 동적으로 결합 - 인코더의 CSP 레이어를 GELAN 레이어로 대체하고 hidden dimension 축소
- 불균형 샘플링 포인트 구현 (Small: 3, Medium: 6, Large: 3)
- RT-DETRv2 학습 전략 적용
Method 검증
주요 성능 결과
- COCO val2017에서 D-FINE-L/X 모델은 경쟁 모델보다 적은 파라미터와 낮은 지연시간으로 더 높은 성능 달성 → 확률 분포 기반 회귀와 증류 방식이 효율적인 실시간 객체 감지에 효과적임
- Objects365 사전 학습 후 성능이 대폭 향상(+3.1~3.5%) → FDR과 GO-LSD는 대규모 데이터셋에서 학습된 특징을 효과적으로 활용 가능
- YOLOv10 대비 14배 적은 에폭(300→21)으로 더 높은 성능 달성 → DETR 기반 모델이 대용량 데이터에서 더 효율적인 학습 특성을 가짐
다양한 DETR 모델에 대한 효과
- 다양한 DETR 모델에 적용 시 상당한 성능 향상(+2.0~5.3% AP) → FDR과 GO-LSD가 모델 구조에 독립적으로 적용 가능한 일반적인 방법임을 입증
- 기본 성능이 낮은 모델(DAB-DETR)에서 가장 큰 향상(+5.3%) → 확률 분포 기반 접근법이 기존 회귀 방식의 한계를 효과적으로 극복함을 시사
추가 성능 결과
- 경량화된 D-FINE-S/M 모델도 준수한 성능 유지 → 모바일 및 임베디드 환경에서도 적용 가능한 확장성 입증
- Knowledge Distillation 방법 비교에서 GO-LSD가 가장 큰 성능 향상(+1.5%) → 기존 증류 방법(Logit Mimicking, Feature Imitation)보다 위치 정보 증류가 객체 감지에 더 중요함을 증명
- GO-LSD는 적은 추가 비용(시간 +6%, 메모리 +2%)으로 큰 성능 향상 → 학습 효율성과 자원 효율성 측면에서 뛰어난 방법임을 입증