Direct Unlearning Optimization for Robust and Safe Text-to-Image Models
Recent advancements in text-to-image (T2I) models have greatly benefited from large-scale datasets, but they also pose significant risks due to the potential generation of unsafe content. To mitigate this issue, researchers proposed unlearning techniques that attempt to induce the model to unlearn potentially harmful prompts. However, these methods are easily bypassed by adversarial attacks, making them unreliable for ensuring the safety of generated images. In this paper, we propose Direct Unlearning Optimization (DUO), a novel framework for removing NSFW content from T2I models while preserving their performance on unrelated topics. DUO employs a preference optimization approach using curated paired image data, ensuring that the model learns to remove unsafe visual concepts while retain unrelated features. Furthermore, we introduce an output-preserving regularization term to maintain the model's generative capabilities on safe content. Extensive experiments demonstrate that DUO can robustly defend against various state-of-the-art red teaming methods without significant performance degradation on unrelated topics, as measured by FID and CLIP scores. Our work contributes to the development of safer and more reliable T2I models, paving the way for their responsible deployment in both closed-source and open-source scenarios.
Problem:: 기존 프롬프트 기반 언러닝 방법은 적대적 공격에 취약 / 텍스트 공간의 많은 동의어나 간접 표현으로 인해 모든 위험 프롬프트 예측 불가능 / 텍스트 조건부 언러닝은 모델 내부 시각적 개념을 실제로 제거하지 않음
Solution:: 이미지 자체에서 안전하지 않은 시각적 특성을 직접 제거하는 Direct Unlearning Optimization(DUO) 제안 / 안전하지 않은 이미지와 안전한 대응 이미지를 쌍으로 구성하여 Preference Optimization 적용 / SDEdit으로 페어 데이터셋 생성 / Output-Preserving Regularization으로 안전한 콘텐츠 생성 능력 보존
Novelty:: 프롬프트 기반이 아닌 이미지 기반 언러닝 방식 최초 제안 / Preference Optimization을 언러닝 문제에 처음 적용 / 적대적 공격에 강건한 안전한 T2I 모델 개발
Note:: 화이트박스 공격 방어를 위해서는 내부 특성을 완전히 제거해야 함 / 관련된 의미의 텍스트로 생성한 사진과 시각적으로 유사한 이미지를 생성하는 경우 모두 잘 동작함
Summary
Motivation
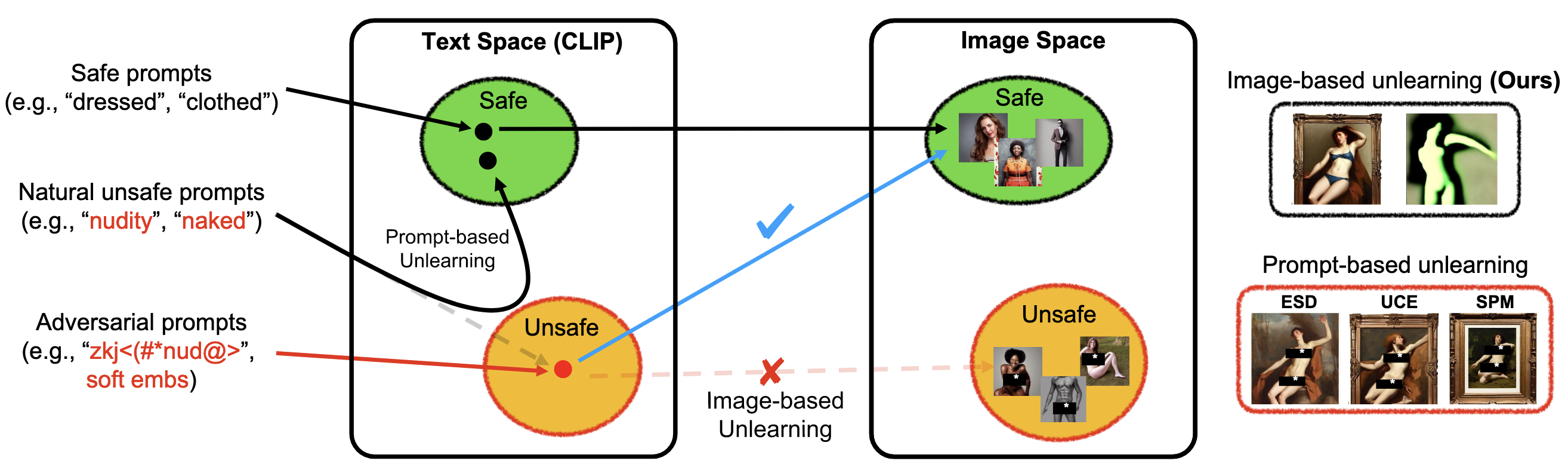
기존 Prompt-based Unlearning은 텍스트 임베딩을 수정함. 이 방식은 모델이 Unsafe 생성 성능을 잊은 것이 아니기 때문에 Unsafe Space를 찾는 Adv Attack에 취약함
- 최근 Text-to-Image(T2I) 모델들은 큰 발전을 이루었으나, 대규모 웹 크롤링 데이터로 학습되어 Not Safe For Work(NSFW) 콘텐츠, 저작권 침해, 개인정보 침해 등의 유해 콘텐츠 생성 위험 존재
- 기존 연구들은 주로 Prompt 기반 Unlearning 접근법을 사용하여 모델이 안전한 프롬프트를 받은 것처럼 동작하도록 학습
- 이러한 방법들은 Adversarial Prompt(Adversarial Attack)에 취약함
- 텍스트에는 NSFW 개념에 대한 많은 동의어나 간접적 표현 존재
- 모든 가능한 Adversarial Prompt를 사전에 예측하고 제거하는 것은 불가능
- 텍스트 기반 Unlearning은 모델 내부의 Visual Concept 자체를 제거하지 않음
- 이미지 기반 Unlearning은 단순히 타겟 이미지를 제거하는 방식으로 진행할 경우, 어떤 개념을 잊어야 할지 모호해짐
- 여성, 숲 등 관련 없는 개념도 함께 잊을 위험
- 이러한 모호성을 해결하기 위해 Preference Optimization 문제로 재구성 필요
Method

- Direct Unlearning Optimization(DUO): T2I 모델에서 NSFW 콘텐츠를 직접 제거하면서 관련 없는 주제에 대한 성능은 보존하는 프레임워크 → Unsafe Image/Text 페어만 가지고 Unlearning을 수행하면 해당 이미지에 포함된 다른 개념도 사라지므로 Safe/Unsafe를 모두 사용해서 Unsafe Text와 매칭되는 영역을 명시하는 방식
- 핵심 요소
- 안전하지 않은 이미지(
)와 안전한 대응 이미지( )를 쌍으로 구성 - Preference Optimization 접근법으로 모델이 안전한 이미지를 선호하도록 학습
- Output-Preserving Regularization을 통해 안전한 콘텐츠 생성 능력 보존
- 안전하지 않은 이미지(
- 데이터셋 구성
- SDEdit 방법을 사용해 안전하지 않은 이미지와 대응되는 안전한 이미지 생성
- 안전하지 않은 이미지
에 특정 양의 가우시안 노이즈를 추가하여 로 보냄 를 안전한 이미지 로 변환하기 위해 부정적 가이던스 적용 - 이를 통해 모델이 무엇을 잊어야 할지 명확하게 인식 가능
- Direct Preference Optimization
- Output-Preserving Regularization
- KL 발산 정규화의 한계로 인해 생성 능력 보존 필요 → 일반적인 생성 능력 보존을 위한 정규화 항 추가
- 완전 노이즈 상태(t=T)에서 원본 모델과 수정된 모델의 디노이징 능력 차이 최소화
- 이미지
수준에서의 정규화는 안전하지 않은 시각적 특성 제거를 방해할 수 있어 t=T로 제한
- 최종 손실 함수
는 KL 정규화의 강도를 제어하는 하이퍼파라미터, 는 Output-Preserving Regularization의 가중치
Method 검증
- 실험 설정: 누드와 폭력 컨텐츠 제거 실험
- Red Teaming 방법
- 블랙박스 공격: Ring-A-Bell(95개 누드 프롬프트, 250개 폭력 프롬프트), SneakyPrompt(200개 SD1.4v 학습 프롬프트)
- 화이트박스 공격: Concept Inversion(I2P 벤치마크 프롬프트로 생성한 이미지로 특수 토큰 학습)
- NudeNet detector로 누드 콘텐츠 감지, GPT-4o로 폭력성 콘텐츠 감지
- FID, CLIP 점수, LPIPS로 일반 성능 평가
- 누드 콘텐츠 제거 실험 결과
- 모든 Red Teaming 방법에 대해 약 90%의 방어 성공률 달성
- Prior Preservation 측면에서 기존 SOTA 방법인 SPM과 유사한 성능 유지
- Pareto Optimal 곡선에서 Unlearning 성능과 Prior Preservation 간 균형점 관찰
- 블랙박스 공격에는 β = 500, 화이트박스 공격에는 β = 250 설정이 최적
- MS COCO 30K에서 FID 13.59-13.65, CLIP 점수 19.88-30.84로 우수한 성능 유지
- 폭력성 콘텐츠 제거 실험 결과
- Ring-A-Bell과 Concept Inversion 모두에서 기존 방법들보다 높은 방어 성공률
- 폭력성은 추상적이고 복잡한 개념이라 완전한 제거가 더 어려움
- 누드 컨텐츠보다 β 파라미터에 따른 Trade-off가 더 가파름
- MS COCO 30K에서 FID 13.37-18.28, CLIP 점수 30.18-30.78로 일반 성능 유지
- Ablation Study
- Output-Preserving Regularization: 낮은 β 영역에서 Prior Preservation 크게 향상
- 정규화 없이는 COCO 생성 결과가 비사실적으로 심각하게 저하됨
- KL 발산 정규화가 없으면(β→0) 이미지 품질 저하 및 관련 없는 개념도 영향 받음
- 데이터셋 크기 실험: 64쌍 이상부터 성능 향상이 둔화됨
- 정성적 분석

- Concept Inversion 공격 시 완전히 손상된 이미지 생성 → 화이트박스 공격에 강력한 방어
- 화이트박스 공격을 방어하려면 내부 특성을 완전히 제거해야 함을 확인

- 시각적으로 유사하지만 안전한 개념(케첩, 딸기잼 등)에 대한 생성 능력 유지 → ESD는 특히 의미적으로 연관되어 있거나, 시각적으로 유사한 이미지에 대한 생성을 잘 하지 못함