Label-Free Concept Bottleneck Models
Concept bottleneck models (CBM) are a popular way of creating more interpretable neural networks by having hidden layer neurons correspond to human-understandable concepts. However, existing CBMs and their variants have two crucial limitations: first, they need to collect labeled data for each of the predefined concepts, which is time consuming and labor intensive; second, the accuracy of a CBM is often significantly lower than that of a standard neural network, especially on more complex datasets. This poor performance creates a barrier for adopting CBMs in practical real world applications. Motivated by these challenges, we propose Label-free CBM which is a novel framework to transform any neural network into an interpretable CBM without labeled concept data, while retaining a high accuracy. Our Label-free CBM has many advantages, it is: scalable - we present the first CBM scaled to ImageNet, efficient - creating a CBM takes only a few hours even for very large datasets, and automated - training it for a new dataset requires minimal human effort. Our code is available at https://github.com/Trustworthy-ML-Lab/Label-free-CBM. Finally, in Appendix B we conduct a large scale user evaluation of the interpretability of our method.
Problem:: 기존 Concept Bottleneck Model(CBM)은 Concept 레이블 데이터가 반드시 필요함 / 이로 인해 데이터 구축 비용과 시간이 많이 소요됨 / 또한, 일반 신경망에 비해 정확도가 저하되는 한계가 있음
Solution:: 데이터와 관련된 Concept을 GPT를 이용해 자동으로 생성 / CLIP을 이용해 Concept Text와 이미지간의 간의 활성화 패턴을 만들고 기존 Feature를 이용해 해당 활성화 패턴을 예측하도록 학습
Novelty:: GPT-3를 활용해 데이터셋에 맞는 Concept 집합을 자동으로 생성 / CBM을 ImageNet과 같은 대규모 데이터셋에 성공적으로 적용하고 높은 성능을 달성 / 모델의 해석 가능성을 이용해 수동으로 가중치를 편집하여 실제 모델 정확도를 향상시킨 사례 제시
Note:: 학습된 Feature를 해석 가능한 공간인 CLIP Feature Space와 연결하여 Interpretability를 향상시킴
Summary
Motivation
- Deep Neural Networks (DNNs)는 복잡한 구조로 인해 내부 동작을 이해하기 어려운 Black-Box 모델로 여겨짐
- CBM은 모델의 중간 Layer(Bottleneck Layer)에 있는 각 뉴런이 인간이 이해할 수 있는 Concept에 해당하도록 학습하여 해석 가능성을 높이는 방법임
- 이를 통해 최종 예측은 해석 가능한 Concept들의 선형 결합으로 표현됨
- 문제 제기: 기존 CBM은 두 가지 결정적인 한계점을 가짐
- Concept 데이터 수집의 어려움: 사전에 정의된 모든 Concept에 대해 레이블링된 데이터를 수집해야 하며, 이는 시간과 노동 집약적인 작업임
- 성능 저하: 특히 복잡한 데이터셋에서 표준 신경망 모델에 비해 정확도가 크게 떨어지는 문제가 발생하여 실제 적용에 장벽이 됨
- 연구 목표: 이러한 문제를 해결하기 위해, Concept 레이블 데이터 없이 CBM을 구축하고, 기존 신경망의 높은 정확도를 유지하는 새로운 프레임워크를 개발하고자 함
Method
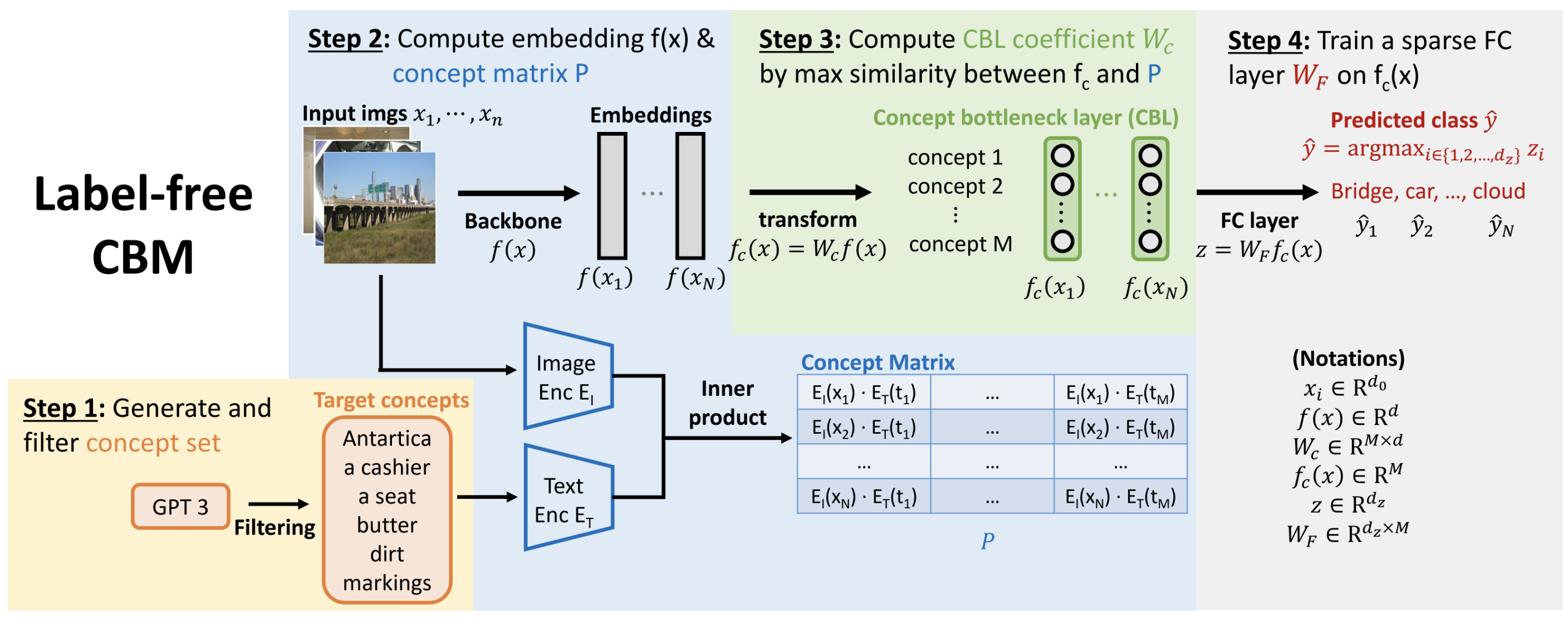
제안하는 Label-free CBM은 어떠한 신경망 Backbone이라도 총 4단계의 과정을 통해 해석 가능한 CBM으로 변환
- Step 1: Generate and Filter Concept Set
- Concept 자동 생성: 전문가의 개입 없이, GPT-3를 사용하여 주어진 Task의 Class들과 연관된 초기 Concept 집합을 자동으로 생성
- "Class를 인식하는 데 가장 중요한 특징은 무엇인가?", "Class 주변에서 가장 흔하게 보이는 것은 무엇인가?" 등의 Prompt를 활용
- Target Concepts
- Concept 필터링: 생성된 초기 Concept 집합의 품질을 높이고 크기를 줄이기 위해 5가지 필터를 적용
- Concept 길이 필터링: 너무 긴 Concept 제거
- Class와의 유사도 필터링: Class 이름 자체와 너무 유사한 Concept 제거 (e.g., '고양이' Class에 '고양이' Concept 제거)
- Concept 간 유사도 필터링: 의미적으로 중복되거나 동의어인 Concept 제거
- 데이터셋 내 존재 여부 필터링: CLIP을 활용하여 학습 데이터에 거의 나타나지 않는 Concept 제거
- Projection 정확도 필터링: Concept Bottleneck Layer에서 정확하게 표현되지 않는 Concept 제거 (Step 3 이후 수행)
- Concept 자동 생성: 전문가의 개입 없이, GPT-3를 사용하여 주어진 Task의 Class들과 연관된 초기 Concept 집합을 자동으로 생성
- Step 2 & 3: Learning the Concept Bottleneck Layer (CBL)
- Backbone의 Feature Space에서 Concept Space로 변환하는 Projection 행렬
를 학습함 - 핵심 아이디어: 레이블링된 Concept 데이터 없이, CLIP-Dissect 방법을 활용하여 CBL을 학습함
- CBL의 각 뉴런(
)의 활성화 패턴( )이 목표 Concept( )의 CLIP 기반 활성화 패턴( )과 유사해지도록 를 최적화함 - Training Data
가 주어짐 - 각 데이터
에 대해 Feature 를 계산 → CLIP Backbone을 이용하지 않아도 됨 로 Concept Space로 Projection ( ) 의 모든 데이터에 대해 수행하여 활성화 패턴 계산 가 CLIP의 Image Encoder 와 Text Encoder 를 이용해 계산한 활성화 패턴 와 유사해지도록 학습 → Projection이 이미지 → Concept의 텍스트 임베딩과 유사도 예측이 되도록 학습 - 이 최적화를 위해 미분 가능한 새로운 유사도 함수 Cos Cubed Similarity를 제안
인 Concept들은 제거 (Step 1의 Concept 필터링 중 하나)
- 이 최적화를 위해 미분 가능한 새로운 유사도 함수 Cos Cubed Similarity를 제안
- Training Data
- Backbone의 Feature Space에서 Concept Space로 변환하는 Projection 행렬
- Step 4: Learning the Sparse Final Layer
-
학습된 CBL의 출력(
)을 입력으로 받아 최종 예측을 수행하는 Fully Connected Layer( )를 학습함 -
해석 가능성을 극대화하기 위해, Elastic Net 정규화를 사용하여
를 희소(Sparse)하게 만듦 : Cross-Entropy Loss : 최종 Fully Connected Layer의 가중치 : 최종 FC Layer의 편향(bias) - Elastic Net 정규화
: Frobenius norm : Element wise matrix norm
-
Method 검증
- 실험 1: Accuracy Comparison
- 실험 내용: CIFAR-10/100, CUB, Places365, ImageNet 데이터셋에서 제안 모델(Label-free CBM)의 정확도를 Standard 모델, Standard (sparse) 모델, Post-hoc CBM (P-CBM)과 비교
- 정량적 성능:
- ImageNet에서 Label-free CBM은 71.95%의 Top-1 정확도를 달성하여, Standard (sparse) 모델(74.35%)과 비견될 만한 성능을 보임
- CUB 데이터셋에서 전문가 Concept을 사용한 P-CBM(59.60%)보다 GPT-3로 자동 생성한 Concept을 사용한 제안 모델(74.31%)이 훨씬 높은 정확도를 기록함
- 전반적으로 제안 모델은 기존 CBM보다 월등히 높고, 표준 희소 모델과 유사한 정확도를 보이며 정확도 저하 문제를 해결함
- 통찰: 제안하는 Label-free CBM은 Concept 레이블 없이도 해석 가능성과 높은 정확도를 동시에 달성할 수 있으며, ImageNet과 같은 대규모 데이터셋으로 성공적으로 확장됨
- 실험 2: Explainable Global Decision Rules
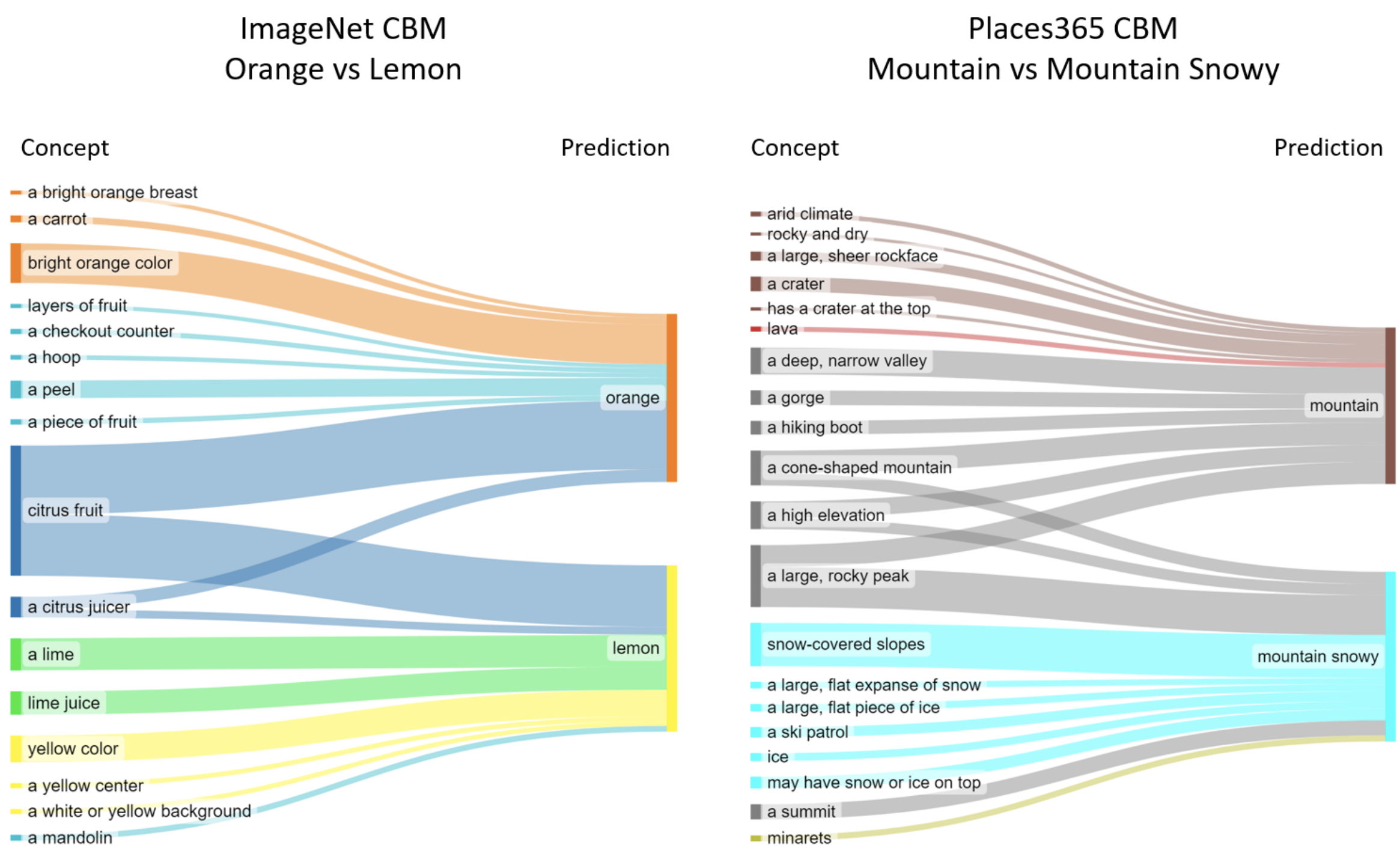
- 실험 내용: 학습된 희소 최종 Layer(
)의 가중치를 시각화하여 모델이 Class를 구별하는 전역적인(Global) 결정 규칙을 분석함 - 정성적 결과:
- ImageNet의 "Orange" vs "Lemon" 분류에서, "Citrus Fruit"은 두 Class 모두에 긍정적인 영향을 주고, "Bright Orange Color"는 "Orange"에, "Yellow Color"는 "Lemon"에 강하게 연결됨
- 이러한 결정 규칙은 인간의 직관과 매우 잘 일치함
- 통찰: 희소 최종 Layer의 가중치 시각화를 통해 모델 전체의 의사결정 방식을 직관적으로 이해할 수 있음
- 실험 내용: 학습된 희소 최종 Layer(
- 실험 3: Explainable Individual Decisions
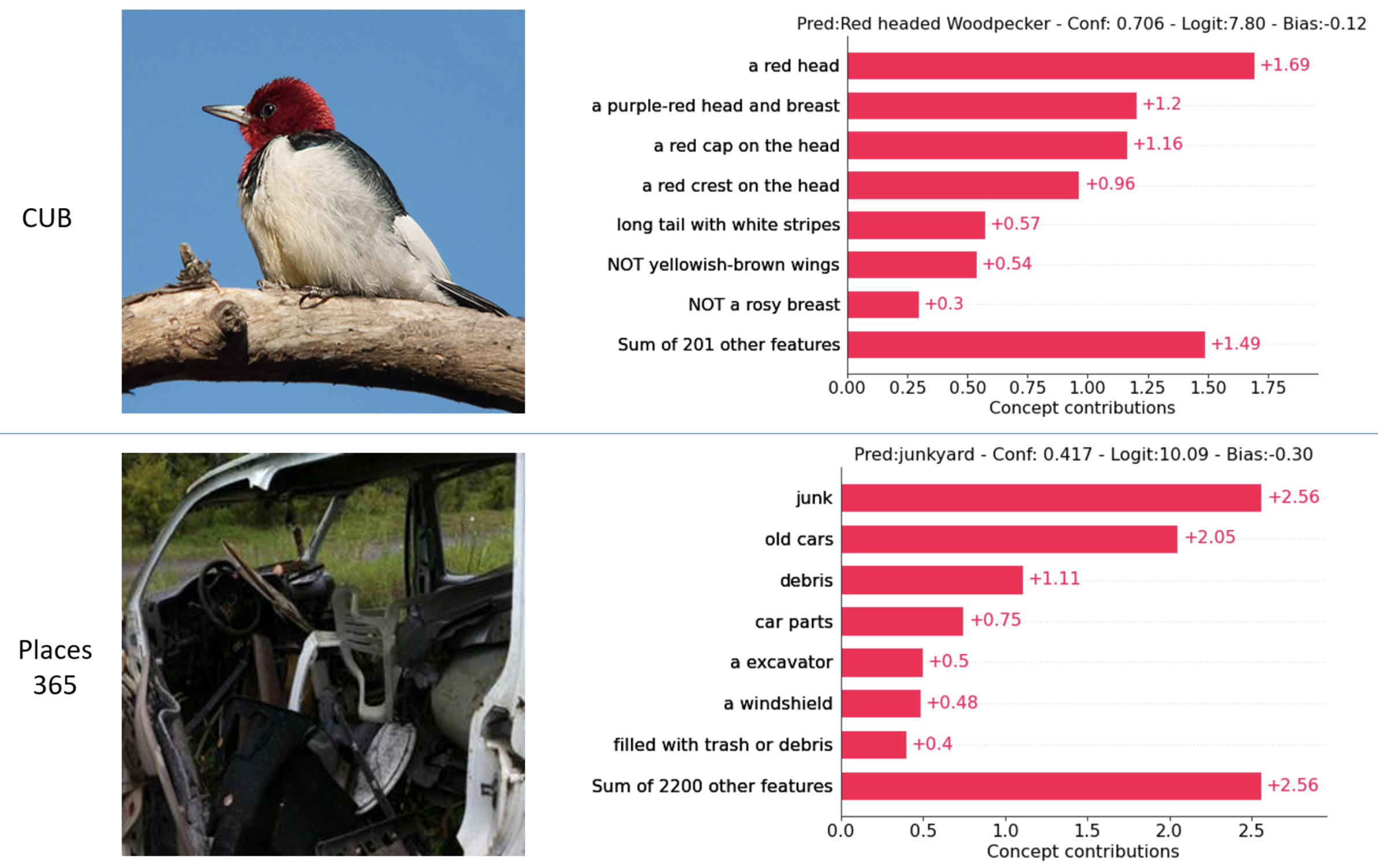
- 실험 내용: 개별 예측에 대해 각 Concept의 기여도(
)를 계산하고 시각화하여 지역적인(Local) 설명을 제공함 - 정성적 결과:
- CUB 데이터셋의 "Red headed Woodpecker" 예측에서, "A Red Head" Concept이 가장 높은 기여도를 보이며 정확한 근거를 제시함
- Places365의 "Junkyard" 예측에서, "Junk", "Old Cars" 등의 Concept이 높은 기여도를 보임
- 통찰: 개별 예측에 대한 정확하고 간결한 설명이 가능하며, 이는 모델의 신뢰성을 높임
- 실험 내용: 개별 예측에 대해 각 Concept의 기여도(
- 실험 4: Case Study: Manually Improving an ImageNet Model

- 실험 내용: 모델의 해석 가능성을 활용하여 잘못된 예측을 수정하기 위해 ImageNet 모델의 최종 Layer 가중치(
)를 수동으로 편집함 - 정량적 성능:
- "Cricket Insect"를 "Grasshopper"로 잘못 예측한 경우, "A Green Color" Concept에 대한 가중치를 "Grasshopper" Class에 대해서는 높이고 "Cricket Insect" Class에 대해서는 낮추는 방식으로 수정
- 총 5개의 예측 오류에 대해 수동 편집을 수행한 결과, ImageNet 검증 데이터셋의 전체 정확도가 71.98%에서 72.02%로 향상됨
- 통찰: 이는 대규모로 학습된 신경망의 가중치를 수동으로 편집하여 테스트 정확도를 향상시킨 최초의 사례 중 하나로, 제안 모델의 해석 가능성이 단순한 이해를 넘어 실제 모델 개선에 사용될 수 있음을 증명함
- 실험 내용: 모델의 해석 가능성을 활용하여 잘못된 예측을 수정하기 위해 ImageNet 모델의 최종 Layer 가중치(