DI-MaskDINO: A Joint Object Detection and Instance Segmentation Model
This paper is motivated by an interesting phenomenon: the performance of object detection lags behind that of instance segmentation (i.e., performance imbalance) when investigating the intermediate results from the beginning transformer decoder layer of MaskDINO (i.e., the SOTA model for joint detection and segmentation). This phenomenon inspires us to think about a question: will the performance imbalance at the beginning layer of transformer decoder constrain the upper bound of the final performance? With this question in mind, we further conduct qualitative and quantitative pre-experiments, which validate the negative impact of detection-segmentation imbalance issue on the model performance. To address this issue, this paper proposes DI-MaskDINO model, the core idea of which is to improve the final performance by alleviating the detection-segmentation imbalance. DI-MaskDINO is implemented by configuring our proposed De-Imbalance (DI) module and Balance-Aware Tokens Optimization (BATO) module to MaskDINO. DI is responsible for generating balance-aware query, and BATO uses the balance-aware query to guide the optimization of the initial feature tokens. The balance-aware query and optimized feature tokens are respectively taken as the Query and Key&Value of transformer decoder to perform joint object detection and instance segmentation. DI-MaskDINO outperforms existing joint object detection and instance segmentation models on COCO and BDD100K benchmarks, achieving +1.2
Problem:: Object Detection과 Instance Segmentation 간의 성능 불균형(Imbalance)
Solution:: Decoder Query에 Detection에 효과적인 정보를 주입/Decoder Key&Value를 Task에 맞도록 변형하여 사용
Novelty:: Detection-Segmentation 간의 성능 불균형(Imbalance) 문제를 해결하는 전용 모듈을 최초로 제안
Note:: 인코더에서 뽑은 feature를 디코더에 넣을때 query와 feature 둘 다 손봄/단순한 Loss weight 조정은 성능 향상/하락에 영향이 적음
Summary
Motivation
- 본 연구는 Object Detection과 Instance Segmentation 간의 성능 불균형(Imbalance) 문제를 해결하고자 함
- 저자들이 관찰한 주요 현상은, MaskDINO의 Transformer Decoder 초기 레이어에서 Object Detection의 성능이 Instance Segmentation보다 현저히 낮다는 점이며, 이로 인해 두 Task의 협력적 학습이 제한되어 궁극적인 성능 상한(Upper Bound)을 저하시킴
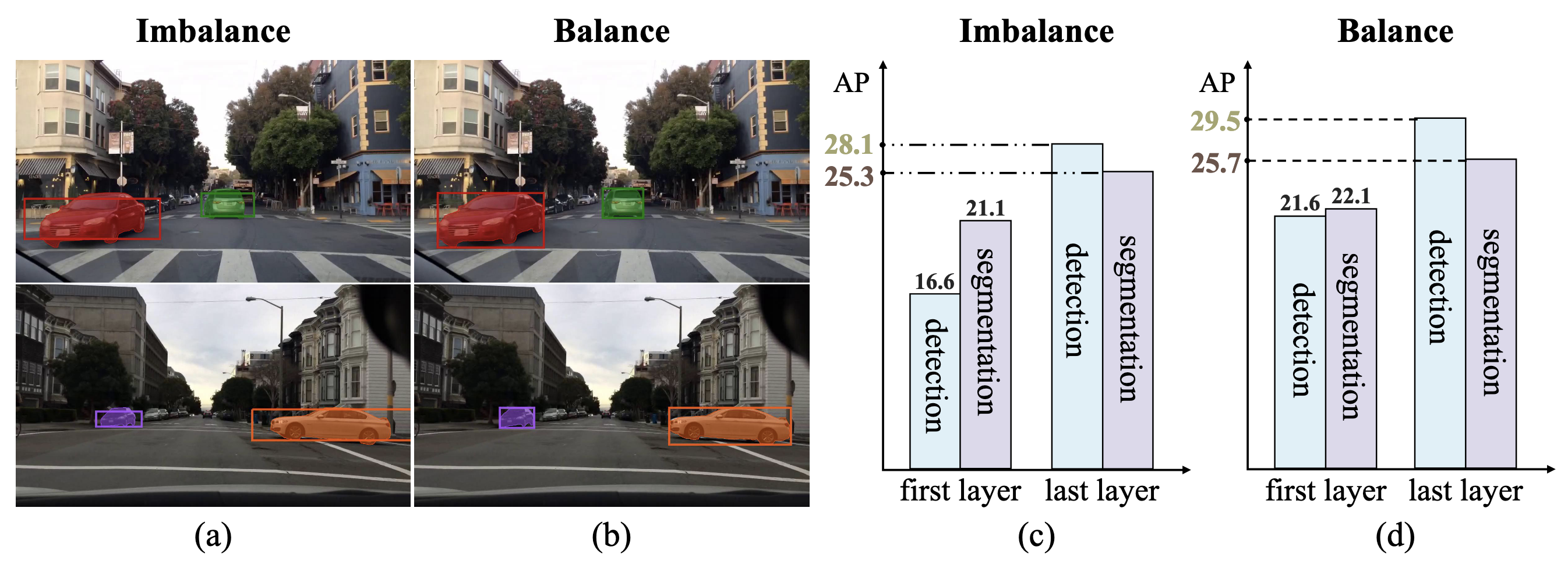
(a), (c): MaskDINO, (b), (d): DI-MaskDINO
- 성능 불균형 문제의 원인은:
- Task의 특성 차이: Segmentation은 픽셀 단위로 정밀한 정보를 필요로 하는 반면, Detection은 객체 전반의 글로벌한 위치 정보를 요구함
- 감독 방식 차이: Segmentation은 픽셀 단위로 밀집 감독(Dense Supervision)이 이루어지지만, Detection은 Bounding Box 4차원 좌표의 희소 감독(Sparse Supervision)이 이루어짐. 이로 인해 두 Task의 학습 속도가 달라지면서 불균형이 발생
Method
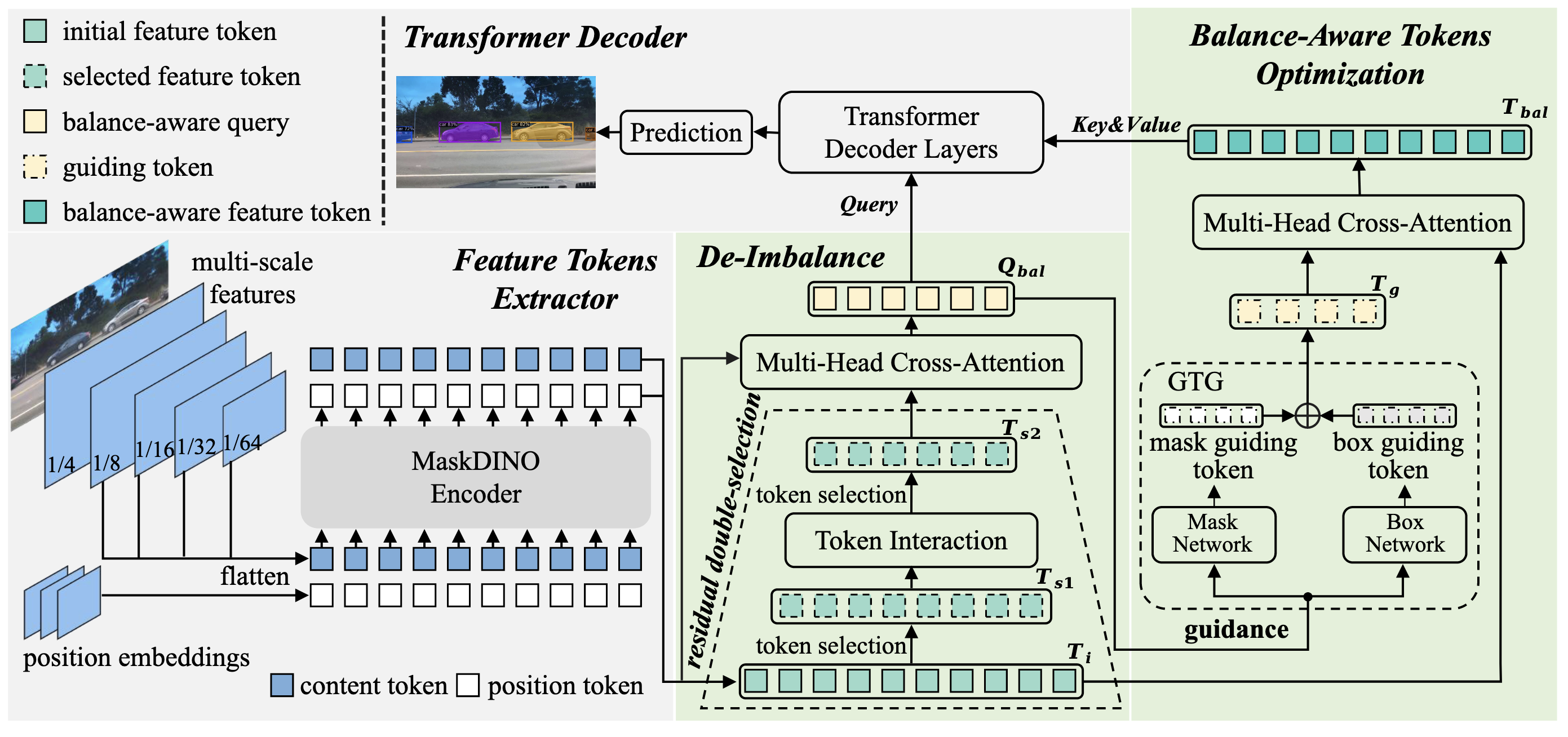
회색 영역: MaskDINO, 연두색 영역: 제안 방식
편의성을 위해, 연두색 영역에는 Content Token과 Position Token을 따로 구분하지 않음 → 실제로 둘 다 존재함
- 제안 모델은 크게 두 가지 모듈을 도입하여 문제를 해결:
- De-Imbalance (DI) 모듈: Decoder에 들어가는 Query를 개선하는 과정
- Residual Double-Selection 메커니즘을 통해 Detection Task의 성능을 강화하여 불균형을 완화
- Selection은 Class Embed의 Score를 기준으로 Top k를 뽑는 방식으로 진행됨
- 두 번의 선택 과정을 통해 객체에 집중된 높은 신뢰도의 Token을 선택하고, 이를 다시 원본 토큰과 Residual 구조로 결합하여 Balance-Aware Query를 생성
- Token Interaction:
- 불균형은 초기 Detection 성능이 Segmentation보다 낮아서 발생
- Detection은 Region-Level, Segmentation은 Pixel-Level 정보가 요구됨
- MHSA를 통해 Region-Level 정보의 품질을 향상 → Detection 품질이 높은 Query를 이용해 불균형 완화
- Residual Double-Selection 메커니즘을 통해 Detection Task의 성능을 강화하여 불균형을 완화
- Balance-Aware Tokens Optimization (BATO) 모듈: Decoder에 들어가는 Key, Value를 개선하는 과정
- DI 모듈에서 생성된 Balance-Aware Query를 활용하여 초기 Feature Tokens을 최적화
- 이 과정에서 Detection과 Segmentation을 위한 각각의 Guiding Token을 생성하여 Feature Tokens 최적화를 유도함
- Guiding Token Generation
- Mask Network와 Box Network는 Embedding Layer
- Mask Guiding Token은
를 임베딩 한 후, Class Score를 기준으로 샘플링하여 생성 - Mask Guiding Token은 Key&Value로, Box Guiding Token은 Key의 Positional Embedding으로 사용됨
Method 검증
- COCO와 BDD100K 데이터셋에서 성능 검증을 수행
- 수치적 비교를 통해 기존의 최신 모델과 비교:
- 기존 SOTA인 MaskDINO 대비 COCO 데이터셋에서 Bounding Box AP +1.2, Mask AP +0.9의 성능 향상.
- Detection 전문 모델 DINO 대비 Bounding Box AP +1.0 향상, Segmentation 전문 모델 Mask2Former 대비 Mask AP +3.0 향상.
- 제안 방식 (DI, BATO) 적용에 따른 성능 변화를 보여 효과성 검증: DI, BATO > DI > BATO > DINO
- 각 Selection 단계의 토큰들 (
, , )를 대신 사용 하였을 때 성능 변화를 보임: - GTG 제거에 따른 성능 변화를 보임: w/ GTG > w/o GTG
- 각 Selection 단계의 토큰들 (
Tolerance Test

Loss Weight Constraint: 학습 시 Detection Loss의 가중치를 Segmentation의 1/10으로 설정
Position Token Constraint: Detection에 효과적인 Position Token을 Random Init하여 성능 평가
- 불균형 조건 하에서도 MaskDINO보다 성능 하락이 적음을 입증하여, 제안 모듈의 유효성 추가 입증