Diffusion-Refined VQA Annotations for Semi-supervised Gaze Following
Training gaze following models requires a large number of images with gaze target coordinates annotated by human annotators, which is a laborious and inherently ambiguous process. We propose the first semi-supervised method for gaze following by introducing two novel priors to the task. We obtain the first prior using a large pretrained Visual Question Answering (VQA) model, where we compute Grad-CAM heatmaps by ‘prompting’ the VQA model with a gaze following question. These heatmaps can be noisy and not suited for use in training. The need to refine these noisy annotations leads us to incorporate a second prior. We utilize a diffusion model trained on limited human annotations and modify the reverse sampling process to refine the Grad-CAM heatmaps. By tuning the diffusion process we achieve a trade-off between the human annotation prior and the VQA heatmap prior, which retains the useful VQA prior information while exhibiting similar properties to the training data distribution. Our method outperforms simple pseudo-annotation generation baselines on the GazeFollow image dataset. More importantly, our pseudo-annotation strategy, applied to a widely used supervised gaze following model (VAT), reduces the annotation need by 50%. Our method also performs the best on the VideoAttentionTarget dataset. Code is available at https://github.com/cvlab-stonybrook/GCDR-Gaze.git.
Problem:: 시선 목표 추정 데이터 셋 라벨링이 너무 힘듬
Solution:: VQA의 Grad-CAM으로 후보군을 추리고 Diffusion으로 Refine하여 Pseudo-Label 생성
Novelty:: 최초의 Semi-supervised Gaze Following 연구
Note:: 아이디어를 현존하는 VQA랑 Diffusion으로 손쉽게 구현한 연구, 다 있던거지만 잘 구성한 듯
Summary
Motivation
- Gaze Following Task의 주요 문제점
- 인간 주석자에 의한 시선 대상 좌표 주석(Annotation)은 매우 노동 집약적이고 본질적으로 모호함
- 기존 방법들은 소수의 라벨링된 데이터에 의존하여 성능이 제한적
- 라벨링되지 않은 대량의 데이터를 효과적으로 활용하는 방법 필요
Method
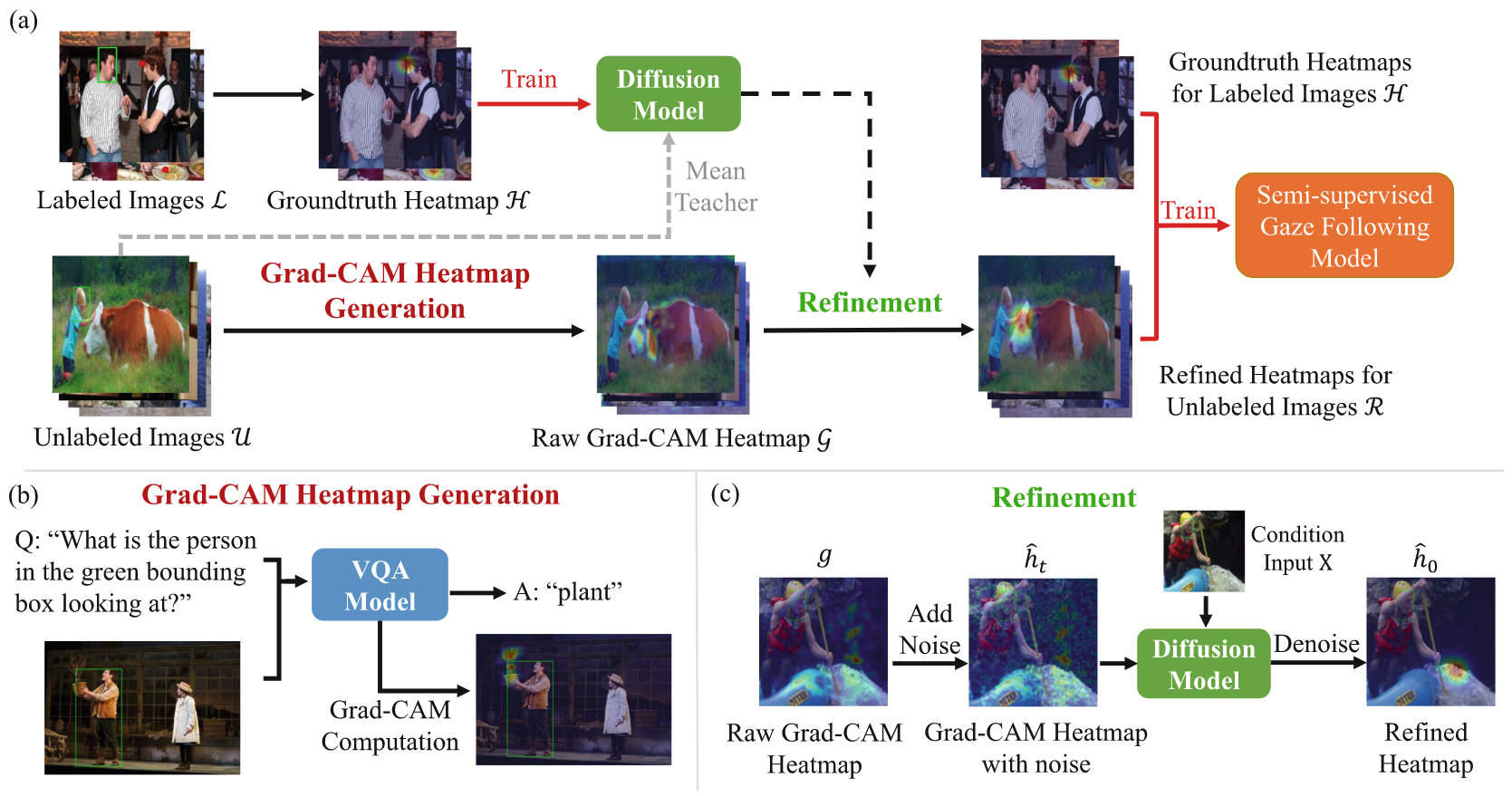
Mean Teacher는 단순히 Diffusion Model 성능 향상을 위한 기법
- 두 가지 핵심 Prior 도입
- 대규모 사전 훈련된 Visual Question Answering (VQA) 모델을 활용한 초기 주석 생성
- Grad-CAM 히트맵을 이용해 시선 대상 위치 추정
- 확산 모델(Diffusion Model)을 이용한 노이즈가 있는 초기 주석 정제
- 제한된 인간 주석 데이터로 훈련된 확산 모델 사용
- 역샘플링 과정을 수정하여 VQA 히트맵의 유용한 정보 보존
- 대규모 사전 훈련된 Visual Question Answering (VQA) 모델을 활용한 초기 주석 생성
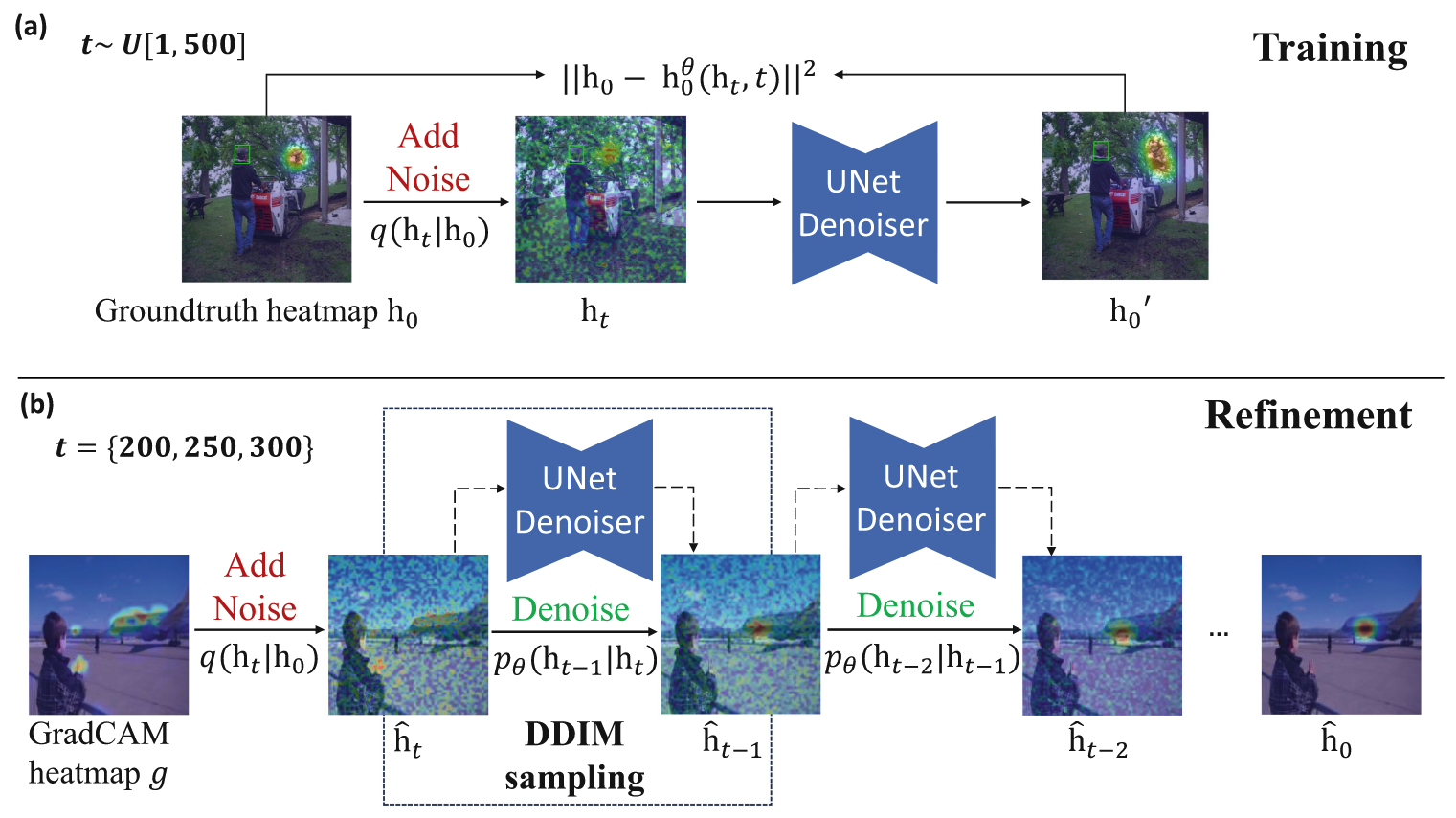
Diffusion Model Training
Method 검증
- 실험 데이터셋
- GazeFollow 이미지 데이터셋
- VideoAttentionTarget 비디오 데이터셋
- 주요 성능 검증 결과
- 단 5-10%의 라벨링된 데이터만으로 기존 완전 지도 학습 모델 성능 달성
- 이미지 및 비디오 Gaze Following 작업 모두에서 성능 향상
- 주석 비용을 최대 50% 절감
- Ablation
- Grad-CAM 히트맵의 잠재력 발견
- VQA 모델을 통해 생성된 Grad-CAM 히트맵이 예상외로 유용한 정보 포함
- 직접 Grad-CAM 히트맵을 입력으로 사용해도 성능 개선 확인
- VAT 모델에 Grad-CAM 히트맵 직접 입력 시 성능 향상 (+1.6 AP)
- 이는 대규모 사전 훈련된 VQA 모델이 이미 풍부한 시각적 지식을 학습했음을 시사
- 다양한 정제 전략 비교
- No Refinement: 원본 Grad-CAM 히트맵 그대로 사용 → 성능 저하
- Argmax Refinement: 최대값 지점에 가우시안 히트맵 생성 → 부분적 개선
- Direct Mapping: U-Net으로 직접 매핑 시도 → 성능 크게 하락
- Proposed GCDR: 확산 모델을 통한 정교한 정제 → 최고 성능 달성
- 확산 모델의 노이즈 추가 타이밍 분석
- 노이즈 추가 단계(timestep)에 따라 성능 크게 변동
- 250단계에서 노이즈 추가 시 최적의 성능 달성
- 조기 단계(100단계)에서는 Grad-CAM 응답 영역에 고착
- 후기 단계(400단계)에서는 정보 손실 심각
- Grad-CAM 히트맵의 잠재력 발견