SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Guided image synthesis enables everyday users to create and edit photo-realistic images with minimum effort. The key challenge is balancing faithfulness to the user inputs (e.g., hand-drawn colored strokes) and realism of the synthesized images. Existing GAN-based methods attempt to achieve such balance using either conditional GANs or GAN inversions, which are challenging and often require additional training data or loss functions for individual applications. To address these issues, we introduce a new image synthesis and editing method, Stochastic Differential Editing (SDEdit), based on a diffusion model generative prior, which synthesizes realistic images by iteratively denoising through a stochastic differential equation (SDE). Given an input image with user guide in a form of manipulating RGB pixels, SDEdit first adds noise to the input, then subsequently denoises the resulting image through the SDE prior to increase its realism. SDEdit does not require task-specific training or inversions and can naturally achieve the balance between realism and faithfulness. SDEdit outperforms state-of-the-art GAN-based methods by up to 98.09% on realism and 91.72% on overall satisfaction scores, according to a human perception study, on multiple tasks, including stroke-based image synthesis and editing as well as image compositing.
Problem:: 기존 Guided Image Synthesis 방법들은 사용자의 입력에 대한 Faithfulness와 생성된 이미지의 Realism 사이의 균형을 맞추기 어려움
Solution:: 사용자 가이드 이미지에 노이즈가 추가된 이미지를 초기값으로 사용하여
Novelty:: 별도의 Task-Specific 학습 데이터나 손실 함수 없이 다양한 편집 작업 수행 가능 / 완전한 노이즈가 아닌, 노이즈가 추가된 사용자 가이드로부터 Reverse SDE를 시작하는 방식 제안 / Reverse SDE 시작 시점(
Note:: Editing의 기본이 되는 연구, 방법이 간단하고 직관적임
Summary
Motivation
- Guided Image Synthesis 및 Editing의 목표는 사용자가 제공한 가이드(예: 거친 색 스트로크)를 따르면서도 사실적인 이미지를 생성하는 것임
- 이를 위해서는 생성된 이미지의 Realism과 사용자 입력 가이드에 대한 Faithfulness라는 두 가지 요건을 충족해야 함
- 기존 접근 방식:
- Conditional GANs: 원본 이미지에서 편집된 이미지로의 직접적인 매핑을 학습하지만, 새로운 편집 작업마다 데이터 수집 및 모델 재학습이 필요함
- GAN Inversions: 사전 훈련된 GAN을 사용하여 입력 이미지를 Latent Representation으로 변환 후 수정하지만, 작업별 손실 함수 설계 및 최적화 과정이 필요하며, 때로는 입력 이미지를 충실히 나타내는 Latent Code를 찾지 못할 수 있음
- 이러한 문제점들을 해결하고 Realism과 Faithfulness의 균형을 맞추기 위해, 사전 훈련된 SDE 기반 생성 모델을 활용하여 별도의 학습이나 Task-Specific Loss 없이 다양한 편집 작업을 수행할 수 있는 SDEdit을 제안함
Method
배경: SDE 기반 이미지 생성 (기존 방식)
- 기존 Diffusion Model 또는 SDE 기반 생성 방식은 두 단계로 구성됨
- Forward Process:
- 깨끗한 원본 이미지
에 점진적으로 Gaussian Noise를 추가하여 시간 에서 완전한 노이즈 로 변환함 - 수식
는 이 과정을 나타내며, 가 증가함에 따라 노이즈의 영향( )이 커짐
- 깨끗한 원본 이미지
- Reverse Process:
-
완전한 노이즈
에서 시작하여 점진적으로 노이즈를 제거해 원본 이미지 를 복원하는 과정 (이미지 생성) -
이 과정은 아래 수식 Reverse SDE로 표현되며, 핵심은 Score Function
임 - Score Function은 현재 노이즈 낀 이미지
에서 노이즈를 줄이는 방향(더 깨끗한 이미지 방향)을 알려주는 가이드 역할을 함
- Score Function은 현재 노이즈 낀 이미지
-
실제로는 Score Function을 모르므로, 딥러닝 모델
를 학습시켜 이를 근사함 -
이미지 생성 시,
부터 까지 아래 수식을 반복 적용하여 Denoising
-
SDEdit: SDE 기반 이미지 편집 (제안 방식)
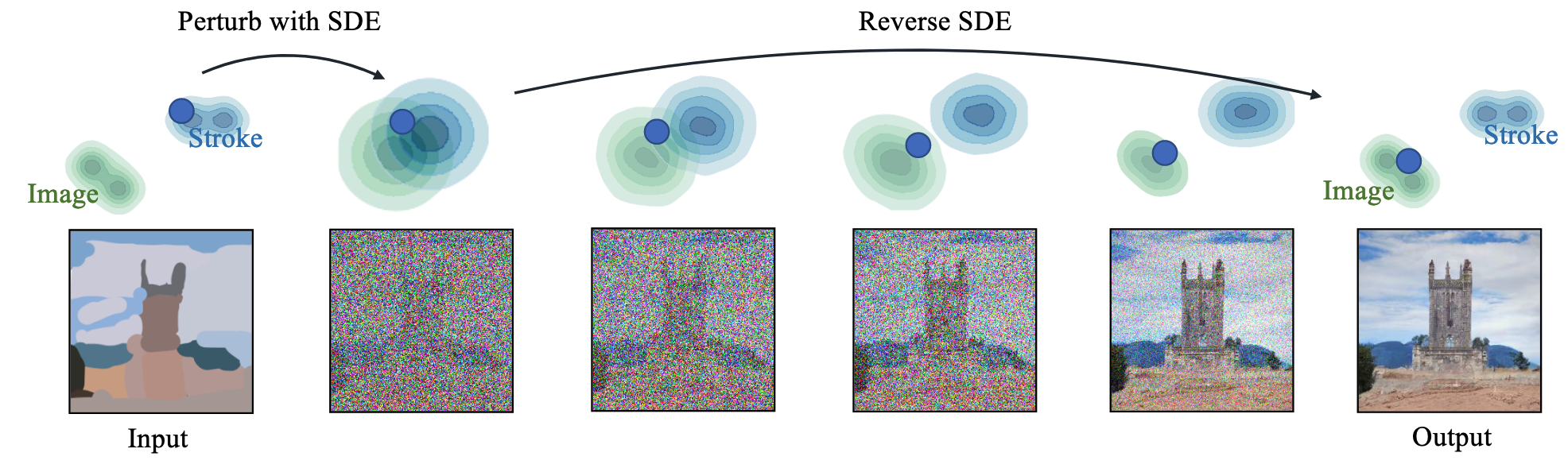
가이드에 노이즈를 추가해서 이미지와 Stroke를 가깝게 만듦 → 가까워 졌으니 Denoising에서 Stroke보다 Image에 가깝게 이동시킴
-
SDEdit: 기존 SDE 생성 모델의 Reverse SDE 능력을 이미지 편집에 활용하되, 완전한 노이즈(
)가 아닌, 사용자 가이드 이미지( )에 약간의 노이즈를 추가한 상태( )에서 Reverse SDE를 시작함 -
SDEdit 작동 방식:
- 사용자가 편집 가이드 이미지
(사실적이지 않을 수 있음)를 제공함 - 가이드 이미지
에 특정 시점 에 해당하는 노이즈를 추가하여 약간 노이즈 낀 가이드 를 생성 → 가이드의 부자연스러운 부분을 완화하면서 전체 구조는 유지하기 위함 - 노이즈 낀 가이드
를 시작점으로 삼아 Reverse SDE (수식 4)를 부터 까지 실행함 → 가이드의 구조를 따라가면서 사실적인 디테일을 채워 넣어 Faithful하면서 Realistic한 최종 이미지를 생성하기 위함
- 사용자가 편집 가이드 이미지
-
의 역할 (Realism-Faithfulness Trade-off): 는 SDEdit의 핵심 조절 변수로, Realism과 Faithfulness 간의 균형을 제어함 가 크면: 초기 노이즈가 많아져 Realism은 높아지지만 Faithfulness는 낮아질 수 있음 - Proposition 1은
가 클수록 원본 가이드와의 차이가 커질 수 있음을 수학적 시사
- Proposition 1은
가 작으면: 초기 노이즈가 적어 Faithfulness는 높지만 Realism이 떨어질 수 있음 - 사용자는 원하는 결과에 맞춰 적절한
값을 선택해야 함 (논문에서는 정도를 추천)
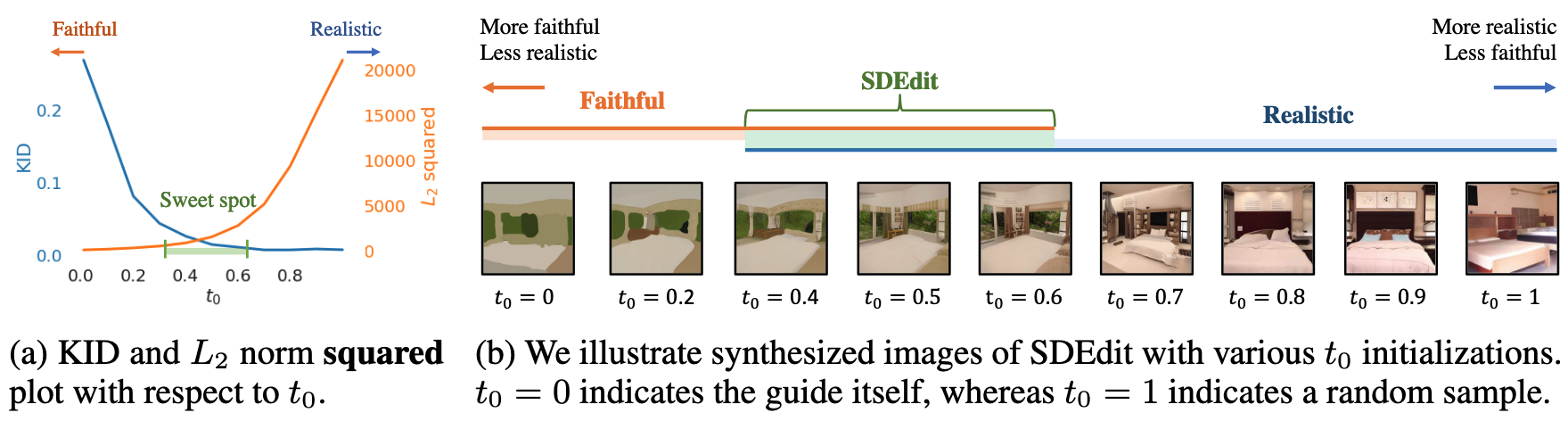
Trade-off를 시각적으로 보여줌
Method 검증
- Stroke-based Image Synthesis on LSUN (bedroom): 사람이 직접 그린 Stroke 또는 알고리즘 시뮬레이션 Stroke를 가이드로 사용하여 SDEdit과 GAN 기반 SOTA 방법들(StyleGAN2-ADA, In-domain GAN-1/2, e4e) 비교

- 정량적 성능 (User-created strokes): SDEdit이
거리(32.55 vs 53.76+)에서 가장 Faithful하고, MTurk 평가에서 Realism(최대 98.09% 선호) 및 Overall Satisfaction(최대 91.72% 선호)에서 Baseline을 크게 능가함 → SDEdit이 Faithful하면서 Realistic한 Stroke 기반 이미지 생성에 매우 효과적 - 정량적 성능 (Algorithm-simulated strokes): SDEdit이
거리(36.76 vs 52.40+) 및 KID(0.0030 vs 0.0464+) 모두에서 Baseline보다 우수함 → SDEdit의 우수성이 자동 생성된 대규모 데이터셋에서도 일관됨 - 정성적 성능: SDEdit은 Baseline과 달리 Stroke의 의미를 보존하며 현실적인 이미지를 생성하고, 동일 입력에 대해 다양한 결과 생성이 가능함 → SDEdit이 의미론적 일관성과 다양성을 모두 갖춤
- 통찰: SDEdit은 기존 GAN 기반 방법들보다 Stroke 기반 이미지 생성에서 Faithfulness와 Realism 모두 뛰어난 성능을 보이며, 특히 사용자의 만족도가 매우 높음
- 정량적 성능 (User-created strokes): SDEdit이
- Stroke-based Image Editing on LSUN (bedroom, church), CelebA-HQ: 실제 이미지에 사용자가 Stroke로 편집 가이드를 추가한 경우, SDEdit과 GAN 기반 Baseline들 비교

- 정성적 성능 (Figure 6): Baseline은 종종 Stroke 외부 영역에 원치 않는 변경이나 블러를 유발하지만, SDEdit은 입력 가이드에 Faithful하면서 Realistic한 편집 결과를 생성하고 원치 않는 변경을 피함 → SDEdit이 로컬 편집의 정확성과 전역적 일관성 유지에 더 효과적
- 통찰: SDEdit은 Stroke 기반 편집에서 원본 이미지의 품질을 유지하면서 사용자의 의도를 정확하고 사실적으로 반영하는 데 더 효과적임
- Image Compositing on CelebA-HQ: 한 이미지에 다른 이미지의 Patch를 사용하여 편집 가이드를 만들고 Mask를 지정한 경우, SDEdit을 전통적인 Blending 및 GAN 기반 Baseline들과 비교

- 정량적 성능: SDEdit이 Faithfulness (
: 21.70 vs 36.67+) 및 Undesired Changes (masked LPIPS: 0.03 vs 0.21+)에서 모든 Baseline과 Traditional 방법보다 우수하며, Overall Satisfaction (MTurk: 최대 83.73% 선호)에서도 가장 뛰어남 → SDEdit이 복잡한 합성 작업에서도 정확하고 자연스러운 결과를 생성 - 정성적 성능: SDEdit은 Traditional Blending이나 GAN 방식보다 더 현실적이면서 Faithful한 합성 결과를 보여줌 → SDEdit의 시각적 품질 우수
- 통찰: 이미지 합성에서 SDEdit은 높은 Faithfulness와 Realism을 동시에 달성하며, 특히 Mask 외부 영역의 원치 않는 변경을 최소화하는 데 강점을 보임
- 정량적 성능: SDEdit이 Faithfulness (