Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
We introduce methods for discovering and applying sparse feature circuits. These are causally implicated subnetworks of human-interpretable features for explaining language model behaviors. Circuits identified in prior work consist of polysemantic and difficult-to-interpret units like attention heads or neurons, rendering them unsuitable for many downstream applications. In contrast, sparse feature circuits enable detailed understanding of unanticipated mechanisms. Because they are based on fine-grained units, sparse feature circuits are useful for downstream tasks: We introduce SHIFT, where we improve the generalization of a classifier by ablating features that a human judges to be task-irrelevant. Finally, we demonstrate an entirely unsupervised and scalable interpretability pipeline by discovering thousands of sparse feature circuits for automatically discovered model behaviors.
Problem:: 기존 신경망 해석 방법들이 Polysemantic하고 해석 어려운 Coarse-Grained Component (Attention Head, MLP Module)에 집중 / Fine-Grained 분석은 연구자 가설에 의존하며 예상치 못한 모델 행동 설명 불가 / 인간이 해석 가능한 Fine-Grained Component로 모델 행동을 설명하는 확장 가능한 방법 부재
Solution:: Sparse Autoencoder (SAE)로 해석 가능한 Feature 추출 / Linear Approximation (Attribution Patching, Integrated Gradients)으로 수천 개 Feature의 인과 효과를 병렬로 효율적 계산 / Threshold 기반으로 중요 Feature와 Edge만 선별하여 Sparse Circuit 구성 / SHIFT를 통해 인간 판단으로 Task-Irrelevant Feature 제거
Novelty:: SAE Feature 기반 Circuit Discovery (기존은 Neuron/Attention Head 단위) / Disambiguating Data 없이 Human Interpretability만으로 Spurious Signal 제거 가능 / 완전 비지도 방식으로 수천 개 모델 행동 자동 발견 및 Circuit 구축 / SAE Error Term을 Circuit에 포함시켜 모델 행동 완전 분해
Note:: Feature Circuit이 Neuron Circuit보다 10-100배 적은 Component로 동일 성능 설명 / Pythia-70M에서 100개 Feature로 80% 성능 설명 (vs 1,500개 Neuron) / SHIFT로 Gender Bias 87.4% → 54.0% 감소하며 Profession 정확도 61.9% → 88.5% 향상 / feature-circuits.xyz에서 수천 개 자동 발견 Circuit 확인 가능
Summary
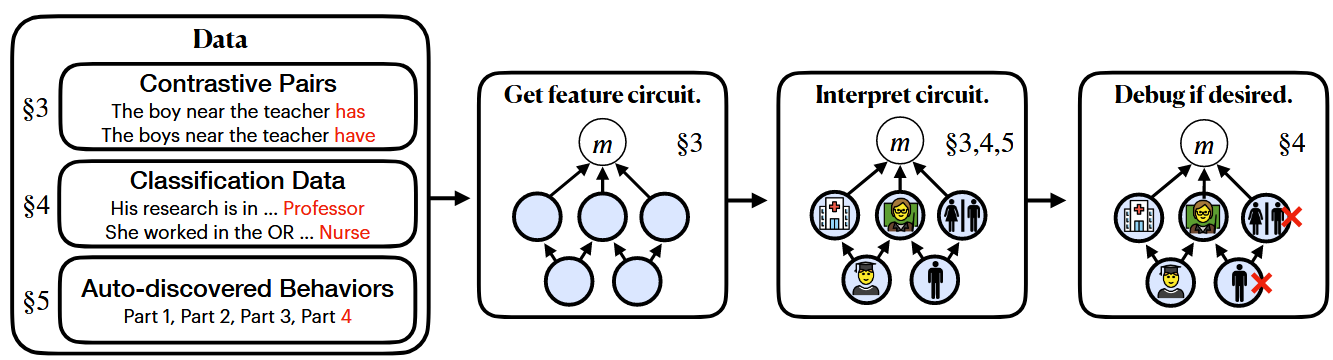
전체 파이프라인 개요: Contrastive Pairs, Classification Data, 또는 Auto-discovered Behaviors를 입력으로 받아 Human-Interpretable Sparse Feature로 구성된 Circuit을 발견하고, 필요시 Spurious Feature를 제거하여 시스템의 일반화 성능을 개선
Motivation
- 기존의 신경망 해석 연구는 Attention Head나 MLP Module 같은 Coarse-Grained Component를 분석하는데 집중했으나, 이들은 Polysemantic하고 해석이 어려움
- Fine-Grained Unit (예: Neuron) 분석 방법들은 연구자가 미리 정의한 가설에 의존하며, 예상치 못한 모델 행동을 설명하기 어려움
- 인간이 해석 가능하고 좁은 역할을 수행하는 Fine-Grained Component를 사용하여 모델 행동을 설명해야 함
- 두 가지 주요 과제: (1) 적절한 Fine-Grained Unit 찾기, (2) 많은 수의 Fine-Grained Unit에서 인과 회로를 찾는 확장성 문제 해결
Method
핵심 목적과 접근 방식
- 목적: 언어 모델의 복잡한 행동을 인간이 이해하고 수정할 수 있는 해석 가능한 Component로 분해
- 접근 방식:
- SAE로 추출한 Interpretable Feature 활용
- Linear Approximation으로 특정 행동에 인과적으로 중요한 Feature만 효율적으로 선별
- 선별된 Feature들로 Sparse Circuit 구성
Sparse Autoencoder를 통한 Feature Disentanglement
- SAE는 모델의 활성화를 해석 가능한 Sparse Feature의 선형 결합으로 분해:
: Unit Vector Feature, : Sparse Feature Activation, : SAE Error Term - SAE Error Term을 버리지 않고 Circuit에 포함시켜 모델 행동을 완전히 분해
Linear Approximation을 통한 인과 효과 측정
- Indirect Effect (IE):
- 특정 노드
가 메트릭 에 미치는 인과적 영향을 측정 - 직접 계산 시 각 노드마다 별도의 Forward Pass 필요 → 비효율적
- 특정 노드
- Attribution Patching:
- First-Order Taylor Expansion으로 IE를 근사
- 2번의 Forward Pass와 1번의 Backward Pass로 모든 노드에 대해 병렬 계산 가능
- 대부분의 레이어에서 충분히 정확
- Integrated Gradients: 더 정확하지만 계산 비용이 높은 근사 방법
- Clean과 Patch 사이의 경로를 따라 Gradient를 적분
- Layer 0 MLP와 Early Residual Stream에서 Attribution Patching이 부정확할 때 사용
- 계산 비용이
배 (보통 ) 증가
- 핵심 장점: 수천 개의 SAE Feature에 대한 인과 효과를 효율적으로 병렬 계산 가능
Sparse Feature Circuit Discovery 상세 과정
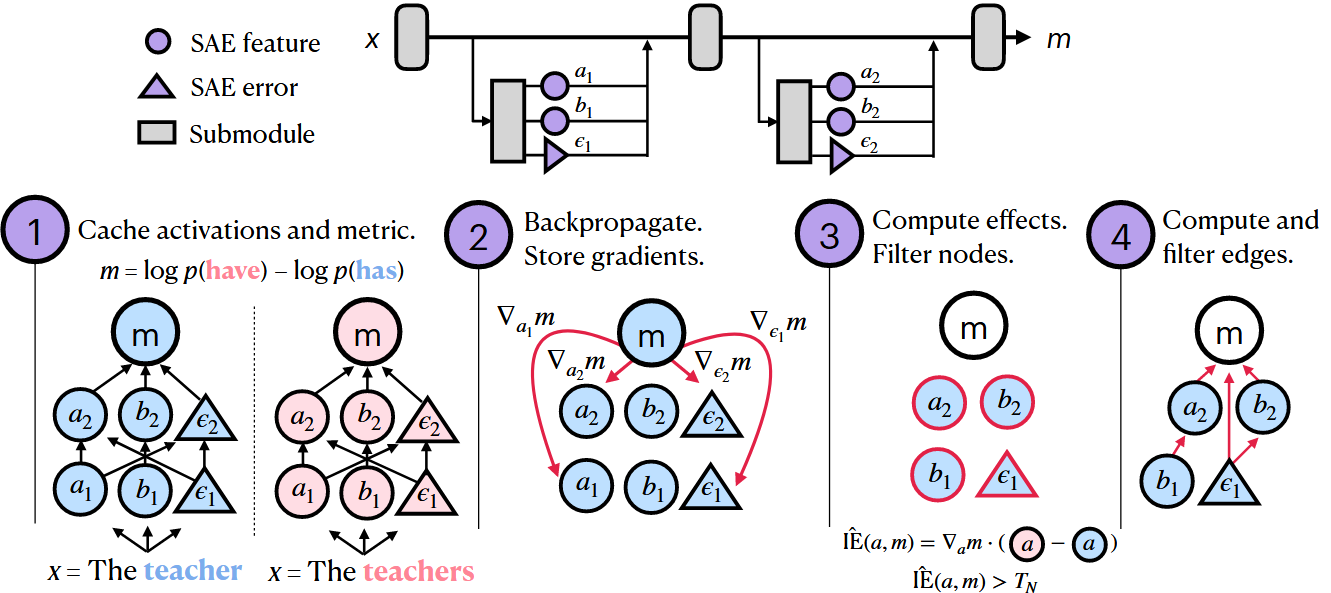
Step 1: Cache Activations and Metric
- 모델을 SAE Feature (사각형)와 SAE Error (삼각형)를 포함하는 Computation Graph로 표현
- 예시: "The teacher" vs "The teachers"에 대해
계산
Step 2: Backpropagate and Store Gradients
- 각 Node에 대한 Gradient
계산 및 저장 - SAE Feature와 Error 모두에 대해 Gradient 계산
Step 3: Compute Effects and Filter Nodes
- Attribution Patching 공식 적용:
- Node Threshold
을 사용하여 인 Node만 선택
Step 4: Compute and Filter Edges
- Node 간의 연결(Edge)에 대해서도 유사한 과정으로 IE 계산
- Edge Threshold
로 중요한 연결만 필터링 - 최종적으로 중요한 Feature와 그들 간의 연결로 구성된 Sparse Circuit 생성
SHIFT (Sparse Human-Interpretable Feature Trimming)
배경: 기존 Spurious Correlation 제거 방법의 한계
- 대부분의 기존 방법은 Disambiguating Labeled Data가 필요 (의도하지 않은 신호가 의도한 신호보다 덜 예측적인 데이터)
- 하지만 실제로는 Worst-Case Scenario가 존재: 서로 다른 데이터 소스에서 온 클래스들, 또는 의도하지 않은 신호가 완벽히 예측적인 경우
- 핵심 문제는 신호가 "의도하지 않았다"는 것이지, "덜 예측적"이라는 것이 아님
SHIFT 방법론 상세
- Feature Circuit 발견
- 분류기
의 정확도를 설명하는 Circuit 계산 - Metric:
(올바른 레이블에 대한 Negative Log Likelihood) - Zero-Ablation Variant 사용:
- 분류기
- 인간의 Feature 해석 및 판별
- Neuronpedia Interface 사용: 대규모 텍스트 코퍼스에서 각 Feature의 Maximally Activating Example 표시
- Feature의 Direct Effect on Output Logits 확인
- Task-Irrelevant Feature 식별: 예) 여성 전기에서 여성 관련 언어를 촉진하는 Feature
- 추가적인 Unlabeled Data는 사용하지만, 추가 Labeled Data나 Classification Data는 사용하지 않음
- Feature Ablation
- 식별된 Task-Irrelevant Feature들을 Zero-Ablation (활성화를 0으로 설정)
- 모델의 다른 부분은 그대로 유지
- Spurious Signal에 대한 의존성만 선택적으로 제거
- 선택적 Fine-Tuning
- Ablation으로 인한 성능 저하 복구
- 원래의 Ambiguous Training Set으로 Linear Classification Head만 재학습
- Ablated Model에서 추출한 활성화를 사용하여 새로운 분류기 학습
- 핵심 장점
- Disambiguating Data 없이도 Spurious Signal 제거 가능
- 인간의 해석가능성 판단만으로 어떤 신호가 의도하지 않은 것인지 식별
- 매우 선택적: 의도한 신호에 대한 성능은 유지하면서 의도하지 않은 신호만 제거
Method 검증
Subject-Verb Agreement Task 실험
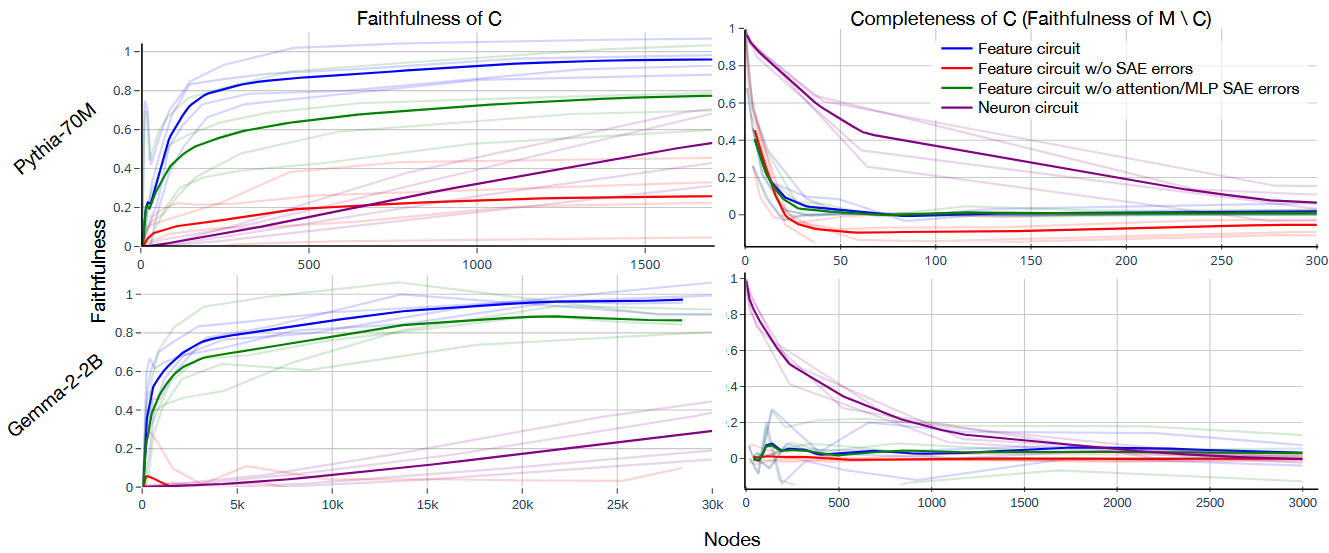
- 실험 목적: Feature Circuit의 기본적인 성능을 정량적으로 평가하기 위해 문법적으로 명확한 태스크에서 Neuron Circuit과 비교
- Faithfulness (왼쪽 그래프):
- Pythia-70M: ~100개의 Feature Node로 성능의 80% 이상 설명
- Gemma-2-2B: ~500개의 Feature Node로 유사한 성능 달성
- Neuron Circuit은 각각 1,500개, 50,000개 필요
- SAE Error를 제거하면 성능이 크게 저하됨 (특히 Residual Stream Error)
- Completeness (오른쪽 그래프):
- 50-100개의 Feature만 제거해도 모델 성능이 0에 가까워짐
- Neuron의 경우 수백~수천 개를 제거해야 동일한 효과
Case Study: Relative Clause를 넘어선 Subject-Verb Agreement
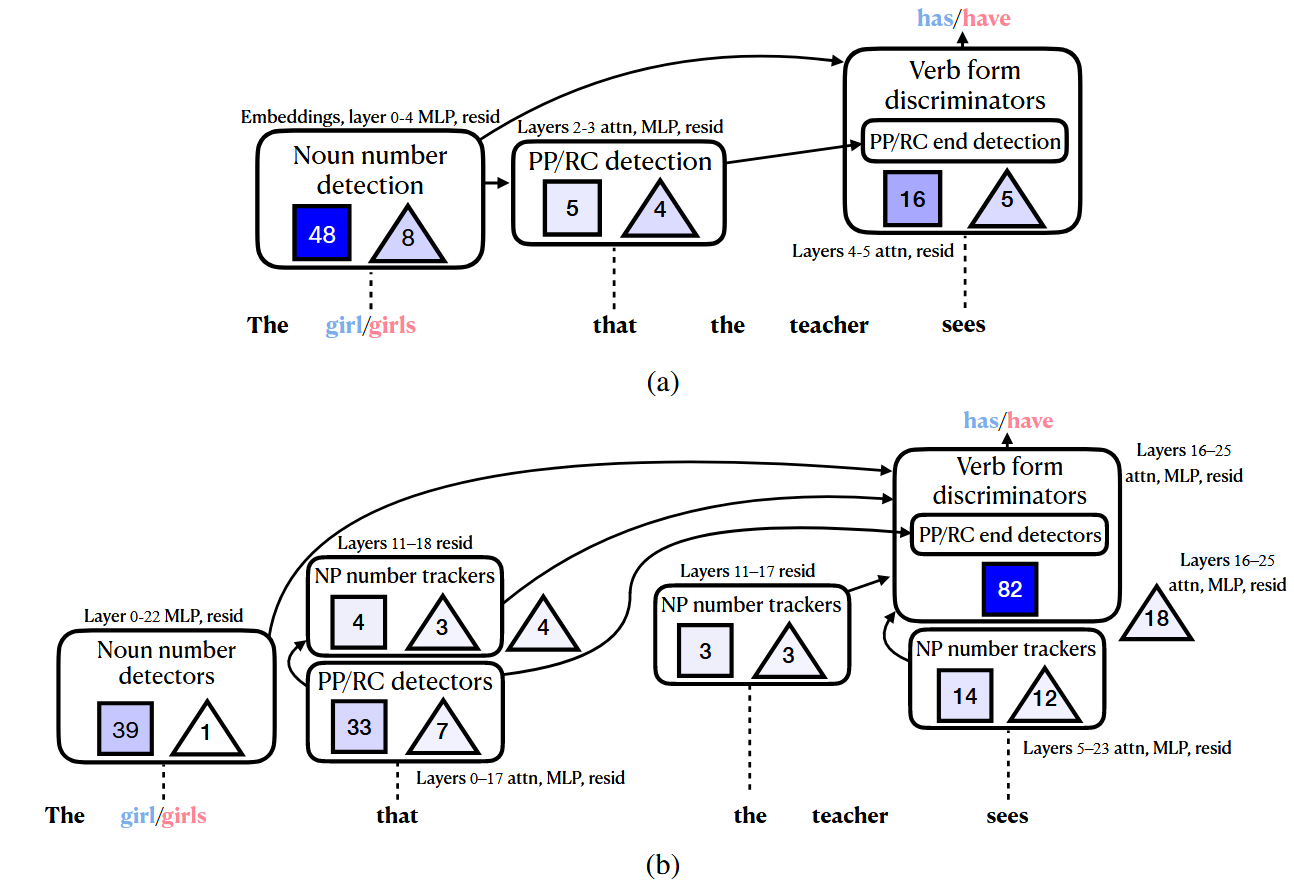
Pythia (a)와 Gemma-2 (b)의 Circuit 구조
- 실험 목적: Feature Circuit이 인간이 이해할 수 있는 알고리즘을 드러내는지 정성적으로 분석
Pythia-70M Circuit (86 nodes):
- Noun Number Detection: "girl/girls" 같은 주어의 수를 감지
- PP/RC Detection: Prepositional Phrase나 Relative Clause의 시작 감지
- PP/RC End Detection: 구문의 끝 감지
- Verb Form Discriminators: "has/have" 같은 적절한 동사 형태 선택
Gemma-2-2B Circuit (223 nodes):
- Pythia와 유사한 구조에 추가로 NP Number Trackers 포함
- NP Number Tracker는 명사구의 수를 추적하여 NP가 끝날 때까지 활성 상태 유지
- 더 복잡하지만 더 명시적인 수 추적 메커니즘
대규모 비지도 Circuit Discovery

자동 발견된 Cluster와 Feature 예시:
- 실험 목적: 인간의 사전 지식 없이도 의미 있는 모델 행동과 그에 대한 Circuit을 자동으로 발견할 수 있는지 검증
- 방법
- Behavior Discovery via Clustering
- The Pile 데이터셋에서
쌍 추출 ( : context, : next token) - 각 샘플을 벡터
로 변환하여 클러스터링 - 벡터화 방법들:
- Training Gradient:
(Michaud et al., 2023) - SAE Activation 또는 Gradient 활용
- Training Gradient:
- 결과적으로 유사한 모델 행동을 보이는 샘플들이 같은 클러스터로 그룹화
- The Pile 데이터셋에서
- Circuit Discovery per Cluster
- 각 클러스터
에 대해 자동으로 Circuit 발견 - Metric:
(Next Token Prediction Loss) - Zero-Ablation Variant 사용하여 중요 Feature 식별
- 완전 자동화: 인간 개입 없이 수천 개 클러스터에 대해 병렬 처리
- 각 클러스터
- Behavior Discovery via Clustering
Cluster 382: Incrementing Sequences
- Succession Feature: "Chapter 1, Chapter 2, Chapter 3" 패턴 인식
- Narrow Induction Feature: "A3 ... A → 4" 같은 특정 패턴 복사
- 여러 Feature가 조합되어 시퀀스 예측 구현
Cluster 475: "to" as Infinitive Object
- 한 Feature: "allowed to", "asked to" 같은 부정사를 취하는 동사 뒤에 "to" 촉진
- 다른 Feature: 동사나 전치사의 목적어 위치에서 "to" 촉진
- 두 가지 독립적인 메커니즘이 하나의 Cluster에서 발견됨
Bias in Bios Dataset에서 SHIFT 적용
- 실험 목적: Feature Circuit을 실제 응용에 활용하여 Disambiguating Data 없이도 의도하지 않은 신호(Gender Bias)를 제거할 수 있는지 검증
- SHIFT만 적용:
- Profession 정확도: 61.9% → 88.5% (Pythia), 67.7% → 76.0% (Gemma)
- Gender 정확도: 87.4% → 54.0% (Pythia), 81.9% → 51.5% (Gemma)
- 성별 정보에 대한 의존성을 크게 감소시키면서 직업 예측 성능 향상
- SHIFT + Retrain:
- Profession 정확도: 93.1% (Pythia), 95.0% (Gemma) - Oracle에 근접
- Gender Bias는 여전히 낮게 유지
- Worst Group Accuracy도 크게 개선: 24.4% → 89.0% (Pythia)