Causality Inspired Representation Learning for Domain Generalization
Domain generalization (DG) is essentially an out-ofdistribution problem, aiming to generalize the knowledge learned from multiple source domains to an unseen target domain. The mainstream is to leverage statistical models to model the dependence between data and labels, intending to learn representations independent of domain. Nevertheless, the statistical models are superficial descriptions of reality since they are only required to model dependence instead of the intrinsic causal mechanism. When the dependence changes with the target distribution, the statistic models may fail to generalize. In this regard, we introduce a general structural causal model to formalize the DG problem. Specifically, we assume that each input is constructed from a mix of causal factors (whose relationship with the label is invariant across domains) and non-causal factors (categoryindependent), and only the former cause the classification judgments. Our goal is to extract the causal factors from inputs and then reconstruct the invariant causal mechanisms. However, the theoretical idea is far from practical of DG since the required causal/non-causal factors are unobserved. We highlight that ideal causal factors should meet three basic properties: separated from the non-causal ones, jointly independent, and causally sufficient for the classification. Based on that, we propose a Causality Inspired Representation Learning (CIRL) algorithm that enforces the representations to satisfy the above properties and then uses them to simulate the causal factors, which yields improved generalization ability. Extensive experimental results on several widely used datasets verify the effectiveness of our approach.
Problem:: 기존 Domain Generalization 방법들이 통계적 의존성만 모델링하여 표면적 설명에 그침 / Target Distribution 변화 시 일반화 실패 / 인과 메커니즘이 아닌 상관관계 학습 (예: 기린-풀밭)
Solution:: Structural Causal Model 도입하여 DG 문제 정형화 / Causal Intervention Module (Fourier Transform으로 Non-Causal 개입) + Factorization Module (독립성 강제) + Adversarial Mask Module (모든 차원 활용)
Novelty:: Domain Generalization에 명시적 인과관계 관점 최초 도입 / 3개 모듈의 상호보완적 설계로 이론을 실제 구현 / MatchDG와 달리 명시적 Causal Factorization
Note:: Mechanistic Interpretability와 연계 가능 할 듯
Summary
Motivation
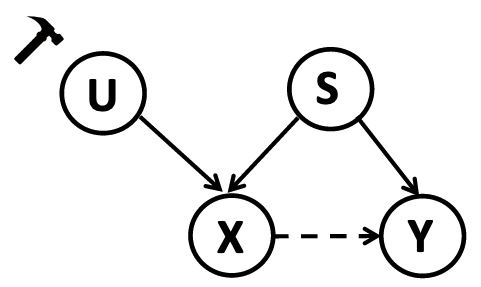
기존 학습 방식은 X와 Y의 통계적 의존성(점선)만을 모델링 → Causal Factor
와 Non-Causal Factor 를 모두 고려해보자
- Domain Generalization (DG)는 본질적으로 Out-of-Distribution (OOD) 문제로, Multiple Source Domains에서 학습한 지식을 Unseen Target Domain으로 일반화하는 것이 목표
- 기존 방법들은 데이터와 레이블 간의 통계적 의존성만을 모델링하여 표면적인 설명(Superficial Description)에 그침
- 통계적 모델은 내재적 인과 메커니즘(Intrinsic Causal Mechanism)을 설명하지 못함
- Target Distribution이 변할 때 일반화 실패 가능성
- 예시: 모든 기린이 풀밭에 있는 이미지로 학습 시, 배경이 바뀌면 잘못된 예측 가능
- 진짜 기린을 만드는 것은 머리, 목 등의 특징이지 배경이 아님
- Structural Causal Model (SCM)을 도입하여 DG 문제를 정형화
: 입력은 Causal Factors 와 Non-Causal Factors 의 혼합으로 구성 : 레이블은 Causal Factors에 의해서만 결정
Method
Causal Factors의 3가지 속성
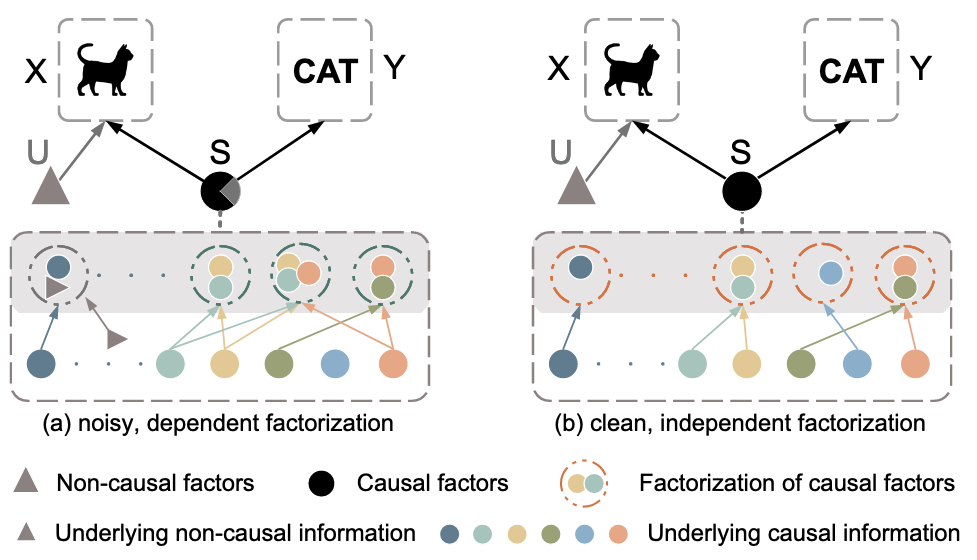
(a) 이상적이지 않은 Causal Factors, (b) 이상적인 Causal Factors
- Non-Causal Factors
와 분리되어야 함 ( ) 에 대한 Intervention이 를 변화시키지 않아야 함 - (a)는
와 가 섞여있음
- Factorization
이 Jointly Independent해야 함 - Independent Causal Mechanisms (ICM) Principle에 기반
- 각 차원이 다른 차원의 정보를 포함하지 않아야 함
- (a)는 각 Causal Factor
가 섞여서 Factorization 되어 있음
- Classification Task
에 대해 Causally Sufficient해야 함 - 모든 통계적 의존성을 설명할 수 있는 정보를 포함
- (a)는 모든
가 사용되지 않아 통계적 의존성을 설명하기에 충분하지 않음
CIRL (Causality Inspired Representation Learning) 알고리즘
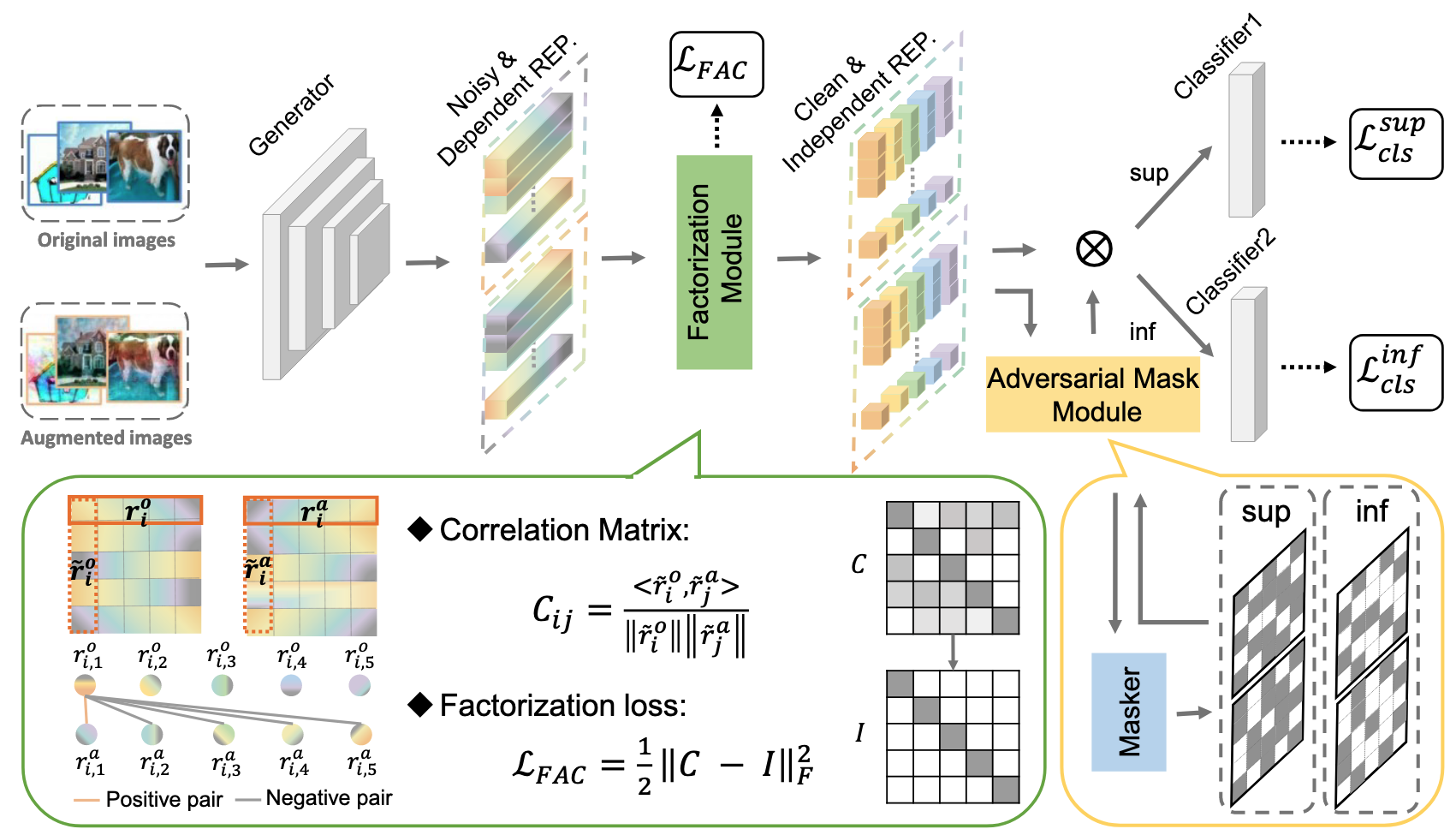
1. Causal Intervention Module
- 문제점: Raw Input
는 Causal Factors 와 Non-Causal Factors 가 섞여있어 직접적인 분리가 불가능 - 해결책: Fourier Transformation을 이용해 도메인 관련 정보(Non-Causal)에만 개입하여
의 불변성을 학습 - Amplitude Component (Low-Level Statistics)를 Perturb: 도메인별 스타일 정보를 변경 →
에 개입 - Phase Component (High-Level Semantics)는 유지: 카테고리 결정에 중요한 구조적 정보 보존 →
는 보존
- Amplitude Component (Low-Level Statistics)를 Perturb: 도메인별 스타일 정보를 변경 →
- 수식:
- 효과: Augmented Image
와 Original Image 의 Representations이 동일하도록 학습함으로써 Non-Causal Factors에 불변한 표현 획득
2. Causal Factorization Module
- 문제점: Causal Factors의 각 차원이 서로 의존적이면 중복된 정보를 포함하거나 일부 Causal Information을 놓칠 수 있음
- 해결책: Correlation Matrix를 이용해 차원 간 독립성을 명시적으로 강제
- Factorization Loss:
- Diagonal Elements → 1: 같은 차원은 Intervention 전후 일관성 유지 (Causal Factor 보존)
- Non-Diagonal Elements → 0: 다른 차원들은 서로 독립적 (각 차원이 고유한 Causal Information 포함)
- 효과: 각 차원이 독립적이고 고유한 Causal Information을 담도록 하여 정보 손실 없이 완전한 Causal Factorization 달성
3. Adversarial Mask Module
- 문제점: 단순히 Supervision Loss만 사용하면 일부 차원만 활용되고 나머지는 무의미한 정보를 담을 수 있음
- 해결책: Adversarial Learning을 통해 모든 차원이 분류에 기여하도록 강제
- Gumbel-Softmax를 이용해 Inferior Dimensions 탐지: 분류에 덜 기여하는 차원을 동적으로 발견
- Adversarial Process:
- Masker: Superior/Inferior Dimensions를 구분하려 함
- Generator: Inferior Dimensions도 분류에 중요한 정보를 담도록 학습
- 효과: 모든 차원이 균등하게 Causal Information을 포함하여 Causally Sufficient한 표현 학습
Method 검증
실험 설정
- 데이터셋: Digits-DG, PACS, Office-Home
- Leave-One-Domain-Out Protocol 사용
- Baseline: DeepAll, FACT, MatchDG 등
주요 실험 결과
- Digits-DG: 82.5% (FACT 대비 +1.0%)
- Domain-Invariant 방법들(CCSA, MMD-AAE) 대비 +8.0%, +7.9%
- PACS (ResNet-18): 86.32%
- MatchDG 대비 +1.76% → 명시적 Causal Representation 학습의 효과
- PACS (ResNet-50): 90.12%
- MatchDG 대비 +4.01% → 더 큰 성능 향상
- Office-Home: 67.12% (FACT 대비 +0.56%)
Ablation Study
- 3개 모듈 중 하나라도 제거 시 성능 하락 → 모든 모듈이 필수적
- CInt. + CFac.: 85.43% / CInt. + CFac. + AdvM.: 86.32%
추가 분석
- Visualization:

- Baseline: 기린을 Horse로, 코끼리를 Dog로 잘못 분류 → Non-Causal Factors (텍스처, 배경)에 집중
- CIRL: 모든 카테고리 정확히 분류 → 기린의 긴 목, 코끼리의 코 등 실제 Causal Factors를 포착
- Attention Map 비교: CIRL은 각 동물의 고유한 형태적 특징에 집중
- Independence Degree:
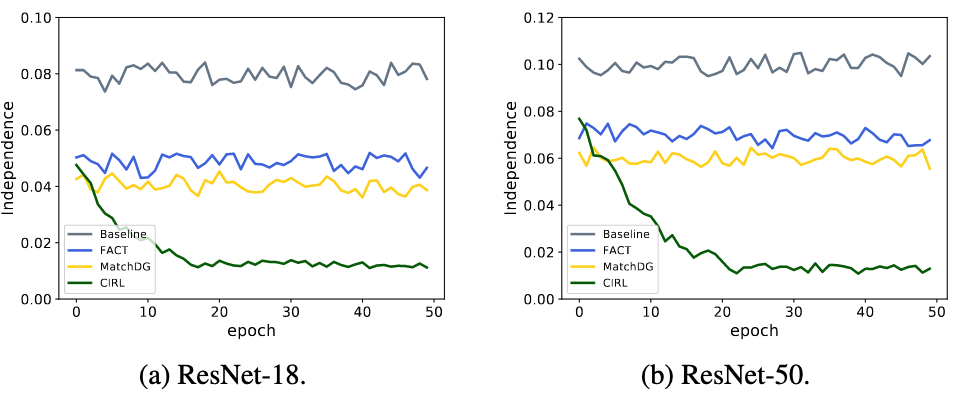
- Baseline 방법들 (DeepAll, FACT, MatchDG): Independence 값이 0.08-0.10으로 높게 유지 → 차원들이 서로 의존적
- CIRL: 학습 진행에 따라 Independence가 0.02까지 감소 → 각 차원이 독립적으로 고유한 Causal Information 포함
- Causal Factorization Module의 효과성 입증
- Representation Importance:
- DeepAll: Mean 3.10, Std 0.25
- FACT: Mean 3.12, Std 0.28
- MatchDG: Mean 3.17, Std 0.19
- CIRL: Mean 3.22, Std 0.09 → 가장 높은 평균값과 가장 낮은 표준편차
- 모든 차원이 균등하게 Causal Information을 포함하여 Causally Sufficient한 표현 학습