Latent Guard: A Safety Framework for Text-to-Image Generation
With the ability to generate high-quality images, text-toimage (T2I) models can be exploited for creating inappropriate content. To prevent misuse, existing safety measures are either based on text blacklists, easily circumvented, or harmful content classification, using large datasets for training and offering low flexibility. Here, we propose Latent Guard, a framework designed to improve safety measures in text-to-image generation. Inspired by blacklist-based approaches, Latent Guard learns a latent space on top of the T2I model's text encoder, where we check the presence of harmful concepts in the input text embeddings. Our framework is composed of a data generation pipeline specific to the task using large language models, ad-hoc architectural components, and a contrastive learning strategy to benefit from the generated data. Our method is evaluated on three datasets and against four baselines.
Problem:: Text-to-image 모델의 부적절한 콘텐츠 생성 위험 증가 / 기존 안전 방식(텍스트 블랙리스트, 유해 콘텐츠 분류)은 쉽게 우회되거나 유연성 부족 / 테스트 시간에 새 개념 추가 시 재학습 필요
Solution:: T2I 모델의 텍스트 인코더 위에 잠재 공간 학습 / 대조 학습으로 개념과 프롬프트 간 공동 임베딩 학습 / 재학습 없이 테스트 시간에 블랙리스트 조정 가능
Novelty:: 텍스트 프롬프트에서 유해성을 차단하는 문제에서 텍스트 임베딩을 적용한 최초의 연구 / 테스트 시간 적응 가능한 블랙리스트 시스템 구현 / 적대적 공격과 동의어에 강건한 안전 프레임워크
Note:: 문장인 프롬프트를 관련 단어에 집중하도록 임베딩 하고, 이 임베딩에 Contrastive Learning을 사용한 방식이 직관적임 → Contrastive의 영향이 특히 커보임 / OOD 성능 평가에 사용된 unseen이 완전히 새로운 유해 컨셉인 경우가 아님 → 완전히 새로운 유해 컨셉에 대해서는 학습이 필요할 수 있음
Summary
Motivation
- Text-to-image(T2I) 생성 모델이 고품질 이미지를 생성할 수 있게 되면서 부적절한 콘텐츠 생성에 악용될 가능성이 증가
- 기존 안전 장치들은 두 가지 주요 접근법으로 구분
- 텍스트 블랙리스트: 특정 금지어를 포함한 프롬프트 차단 방식으로, 수동 또는 최적화 절차로 쉽게 우회 가능
- 유해 콘텐츠 분류: 대규모 데이터셋으로 학습된 분류기를 사용하지만 낮은 유연성과 높은 계산 비용 발생
- 기존 방식은 텍스트 인코더를 대상으로 한 최적화 기법에 취약하며, 효율적인 T2I 입력 프롬프트 안전 검사 솔루션이 부재
- 새로운 개념을 차단하려면 기존 시스템에서는 재학습이 필요하여 유연성이 떨어짐
Method
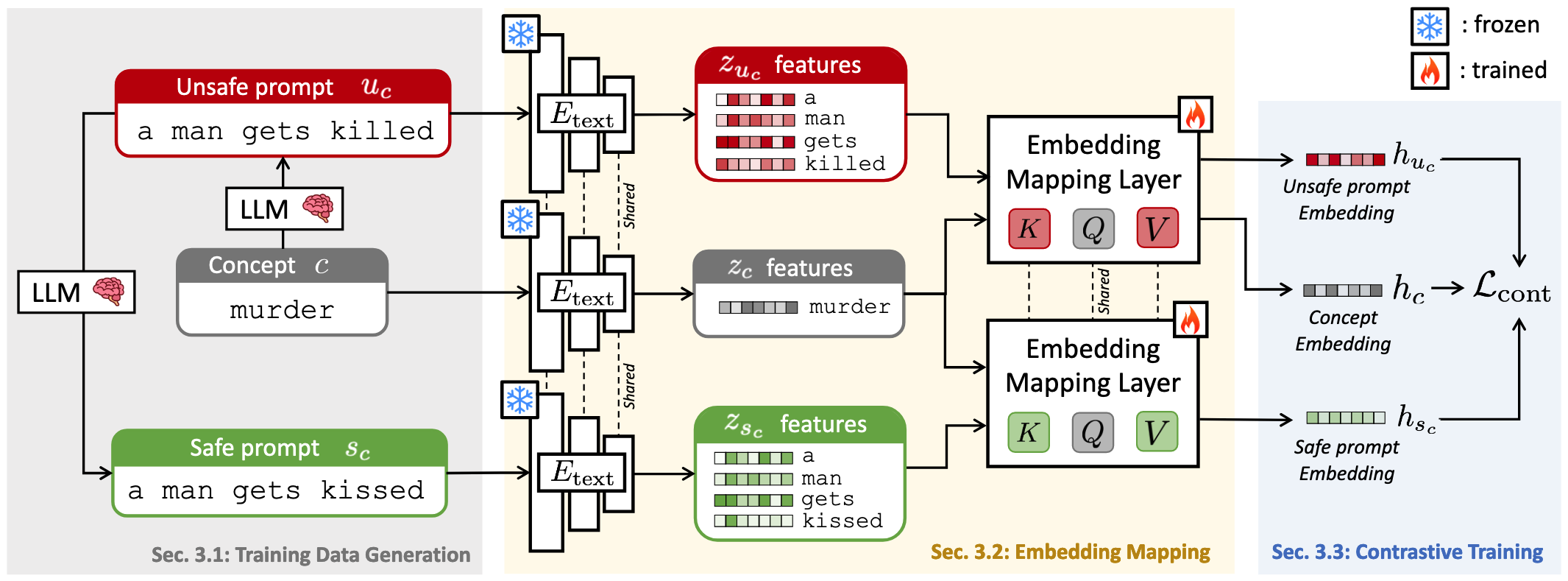
- Latent Guard는 T2I 모델의 텍스트 인코더 위에 잠재 공간을 학습하여 입력 텍스트 임베딩에서 유해 개념의 존재를 확인하는 프레임워크
- 블랙리스트 기반 접근법에서 영감을 받았지만 정확한 단어 매칭 대신 잠재 공간의 표현을 활용해 우회 공격에 대한 견고성 확보
- 프레임워크는 세 가지 주요 구성 요소로 이루어짐
Training Data Generation

CoPro를 만드는 방식
- 대규모 언어 모델(LLM)을 활용한 데이터 생성 파이프라인 구축
- 블랙리스트 유해 개념
정의 - 각 개념
에 대해 LLM으로 유해 프롬프트 및 해당 개념을 제거한 안전 프롬프트 생성 - 예: 개념 "murder"에 대해 "a man gets murdered"(유해)와 "a man gets kissed"(안전) 생성
- 유해 프롬프트 집합
와 안전 프롬프트 집합 구성 - 실험을 위해, 유해 프롬프트에 대해서 동의어로 교체/Adv Attack으로 생성한 프롬프트도 만듦 → CoPro
- CoPro 데이터셋 생성: 723개 유해 개념과 226,104개 안전/유해 프롬프트 포함
- In-distribution(ID): 578개 개념으로 훈련 및 평가(Explicit, Synonym, Adversarial 테스트 세트)
- Out-of-distribution(OOD): 145개 미등록 개념으로 평가만 수행
Embedding Mapping
- 입력 프롬프트와 블랙리스트 개념을 처리하기 위한 표현 추출기 설계 → 문장 프롬프트에 컨셉과 직접적으로 매치되는 단어가 있으면 그걸 중심으로 임베딩
- 사전 훈련된 텍스트 인코더
로 개념 와 T2I 프롬프트 를 처리하여 임베딩 와 추출 - 임베딩 매핑 계층은 멀티헤드 크로스 어텐션을 사용하여 프롬프트 내 관련 토큰의 중요도 강화
- 크로스 어텐션:
, , - 어텐션 계산:
, - 최종 임베딩:
,
- 크로스 어텐션:
- 이 구조는 프롬프트 내에서 유해 개념과 관련된 토큰에 집중할 수 있게 해줌
Contrastive Training
- 유해 개념이 포함된 프롬프트와 그 개념의 임베딩을 가깝게, 안전한 프롬프트는 멀리 위치시키는 학습 방식 → 유해 프롬프트는 컨셉과 가깝고, 안전한 프롬프트는 멀리
- 배치
에서 개념 임베딩 를 앵커로, 유해 프롬프트 임베딩 를 양성 샘플로 설정 - 부정 샘플로는 다른 유해 프롬프트 임베딩
, 해당 안전 프롬프트 임베딩 , 다른 안전 프롬프트 임베딩 사용 - 손실 함수:
- 이 학습 과정을 통해 유해 개념 감지에 최적화된 잠재 공간 학습
추론 단계
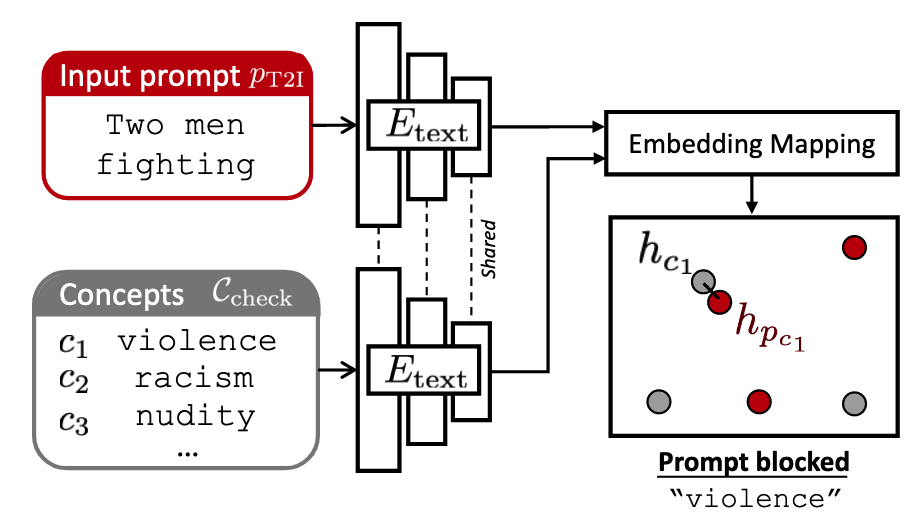
- 사용자가 제공한 T2I 프롬프트
에 대해 블랙리스트 의 모든 개념 확인 - 각 개념
에 대해 개념 임베딩 와 조건부 프롬프트 임베딩 계산 - 코사인 거리로 유사도 측정:
- 모든 거리가 임계값
이상이면 안전, 하나라도 미만이면 유해로 판단 → 임베딩을 앞선 과정으로 수행했으므로 가능 - 계산 효율성: 개념 임베딩은 미리 계산하여 저장 가능하고, 추가 처리는 텍스트 인코딩 위에 임베딩 매핑 계층만 필요
Method 검증
실험 설정
- 베이스라인: 텍스트 블랙리스트, CLIPScore, BERTScore, LLM 기반 분류기
- 평가 지표: 이진 분류 정확도, AUC(임계값 독립적 평가)
성능 비교 결과
- CoPro 데이터셋 결과: Unseen 개념에 대해서도 일반화 성능이 잘 나타남
- Explicit 테스트에서 ID 0.868, OOD 0.867로 높은 정확도 달성
- Synonym 테스트에서 ID 0.828, OOD 0.824로 동의어 공격에 강한 견고성
- Adversarial 테스트에서 ID 0.829, OOD 0.819로 적대적 공격에 대한 방어력 입증
- AUC 측정에서도 모든 테스트 세트에서 0.908~0.985의 우수한 성능 보임
- Unsafe Diffusion 및 I2P++ 외부 데이터셋에서도 일관된 우수성:
- Unsafe Diffusion: 0.794 정확도(베이스라인 0.472~0.752)
- I2P++: 0.701 정확도(베이스라인 0.485~0.671)
- I2P++: Unsafe 프롬프트만 가진 I2P와 COCO의 Safe 캡션을 합쳐서 생성
- NudeNet+Q16 기반 이미지 생성 안전성 평가에서도 최저 부적절성 점수(0.029, 0.066) 달성
추가 분석
- 계산 효율성: 최대 3,000개 블랙리스트 개념 처리 시에도 35ms 이내 처리 시간과 19MB 미만 메모리 사용
- 아키텍처 실험: 어텐션 헤드 수(I=16)와 임베딩 차원(d=128)의 최적 구성 도출
- 모델 구성 요소 영향: 크로스 어텐션과 안전 프롬프트 활용이 성능에 중요한 영향을 미침
- 테스트 시간 블랙리스트 수정: 블랙리스트 개수를 줄이면 성능이 하락 → 새로운 유해 개념을 추가할때 학습할 필요가 없음(?)
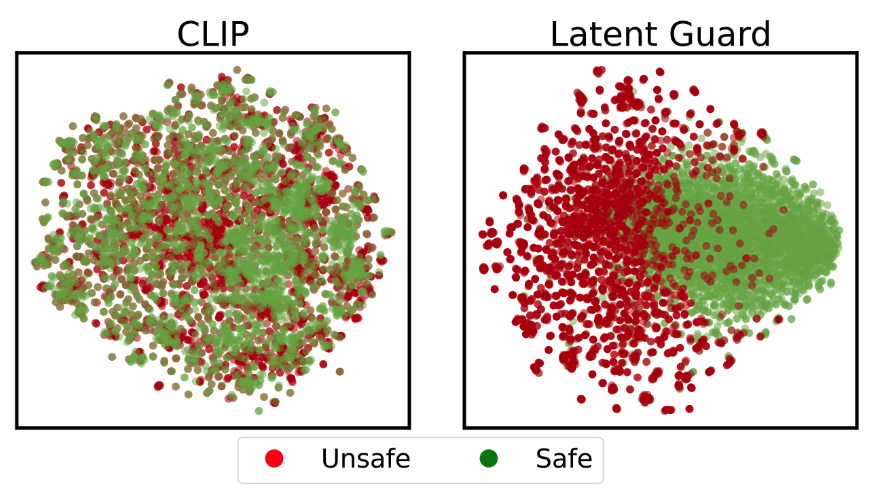
- 잠재 공간 분석: 학습을 통해 안전/유해 프롬프트가 자연스럽게 분리되는 특성 확인 → Contrastive Learning의 결과로 보임