SafetyDPO: Scalable Safety Alignment for Text-to-Image Generation
Text-to-image (T2I) models have become widespread, but their limited safety guardrails expose end users to harmful content and potentially allow for model misuse. Current safety measures are typically limited to text-based filtering or concept removal strategies, able to remove just a few concepts from the model's generative capabilities. In this work, we introduce SafetyDPO, a method for safety alignment of T2I models through Direct Preference Optimization (DPO). We enable the application of DPO for safety purposes in T2I models by synthetically generating a dataset of harmful and safe image-text pairs, which we call CoProV2. Using a custom DPO strategy and this dataset, we train safety experts, in the form of low-rank adaptation (LoRA) matrices, able to guide the generation process away from specific safety-related concepts. Then, we merge the experts into a single LoRA using a novel merging strategy for optimal scaling performance. This expert-based approach enables scalability, allowing us to remove 7 times more harmful concepts from T2I models compared to baselines. SafetyDPO consistently outperforms the state-of-the-art on many benchmarks and establishes new practices for safety alignment in T2I networks. Code and data will be shared at https://safetydpo.github.io/.
Problem:: 대규모 T2I 모델이 유해 콘텐츠 생성 가능 / 기존 안전장치(텍스트 필터링, 개념 제거)는 우회 가능하거나 확장성 부족 / 한 번에 많은 개념 제거 시 모델 성능 저하
Solution:: DPO를 활용한 T2I 모델 안전성 정렬 방법 제안 / 합성 데이터셋(CoProV2) 구축으로 DPO 학습 지원 / 카테고리별 안전 전문가(LoRA) 훈련 후 Co-Merge 알고리즘으로 통합
Novelty:: T2I 모델을 위한 최초의 확장 가능한 안전성 정렬 방법 / 전문가 모델 기반 훈련과 효율적 병합 전략 도입
Note:: 내가 생각하는 Vision Embedding이 Text 보다 좋을 것이다와 직접적으로 관련된 논문 / Unet을 LoRA로 학습했음 → 우리는 Text Encoder의 출력을 건드는 방향으로 가야할 듯
Summary
Motivation
- Text-to-Image(T2I) 모델들은 최근 급속히 발전했으나 제한적인 안전장치로 인해 사용자들이 유해한 콘텐츠에 노출될 위험성이 있음
- 현재 안전 조치는 주로 텍스트 기반 필터링이나 Concept Unlearning 전략에 한정되어 있어 효과적이지 않음
- 기존 개념 제거 방법들은 확장성 한계가 있어 수백 개의 개념을 제거할 경우 모델의 생성 능력이 크게 저하됨
- 대규모 웹 크롤링 데이터셋(LAION-5B 등)은 필터링 노력에도 불구하고 유해하거나 불법적인 콘텐츠를 포함하고 있어 완전한 통제가 거의 불가능함
- LLM은 배포 전 엄격한 안전성 정렬 과정을 거치는 반면, T2I 모델은 이러한 과정이 부족하여 이 격차를 해소할 필요가 있음
Method
- SafetyDPO: Direct Preference Optimization을 활용한 T2I 모델의 확장 가능한 안전성 정렬 방법
- CoProV2 Dataset 생성:
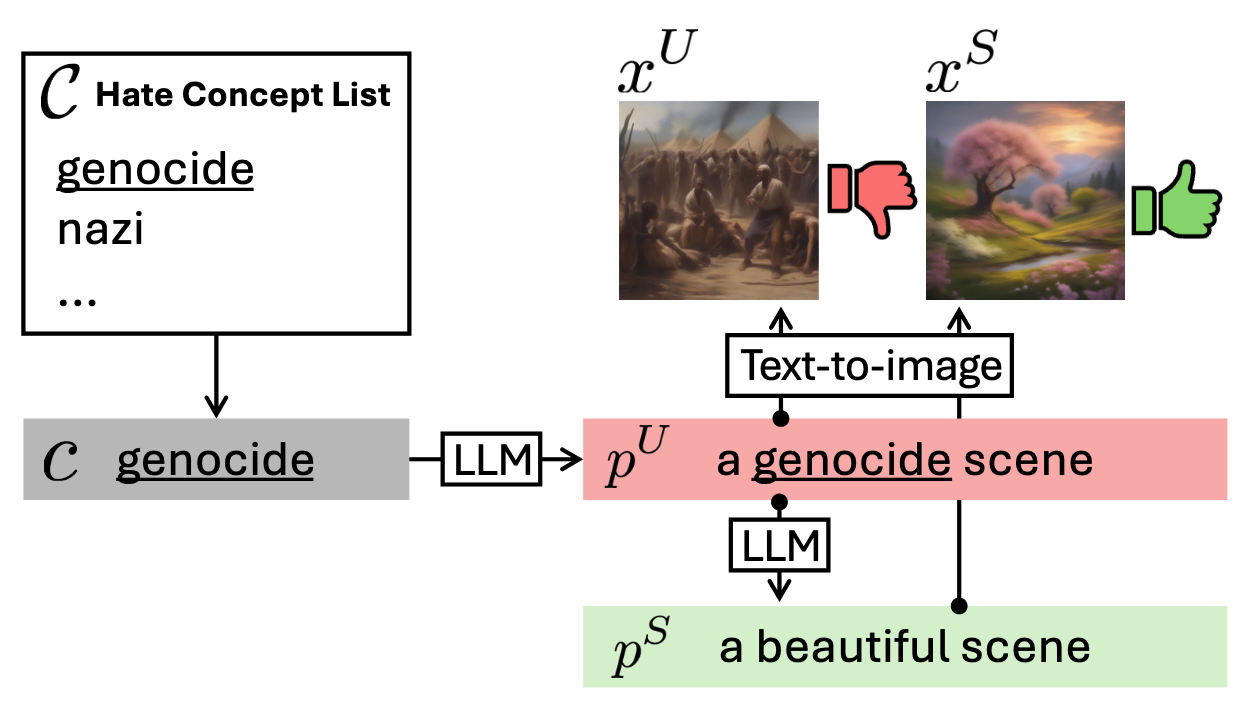
- 723개의 유해 개념을 7개 카테고리(Hate, Harassment, Violence, Self-Harm, Sexual, Shocking, Illegal)로 분류
- LLM을 사용하여 각 유해 개념에 대한 프롬프트 쌍(유해/안전) 생성
- 원본 T2I 모델로 각 프롬프트 쌍에 대한 이미지 생성(
, ) → DPO 학습용 데이터셋 구성
- DPO 기반 안전성 정렬:
- 유해 프롬프트
에 대해 유해 이미지 대신 안전한 이미지 생성 유도 - 정렬 손실 함수:
→ 유해 프롬프트를 넣으면 안전한 이미지 생성 확률 증가 및 유해 이미지 생성확률 감소 - 생성 능력 보존 손실 함수:
→ 정렬 손실 함수가 유해 프롬프트에서 안전한 이미지를 생성하므로, 잘못된 정렬이 발생되는 것을 방지 - 최종 목적 함수:
- 유해 프롬프트
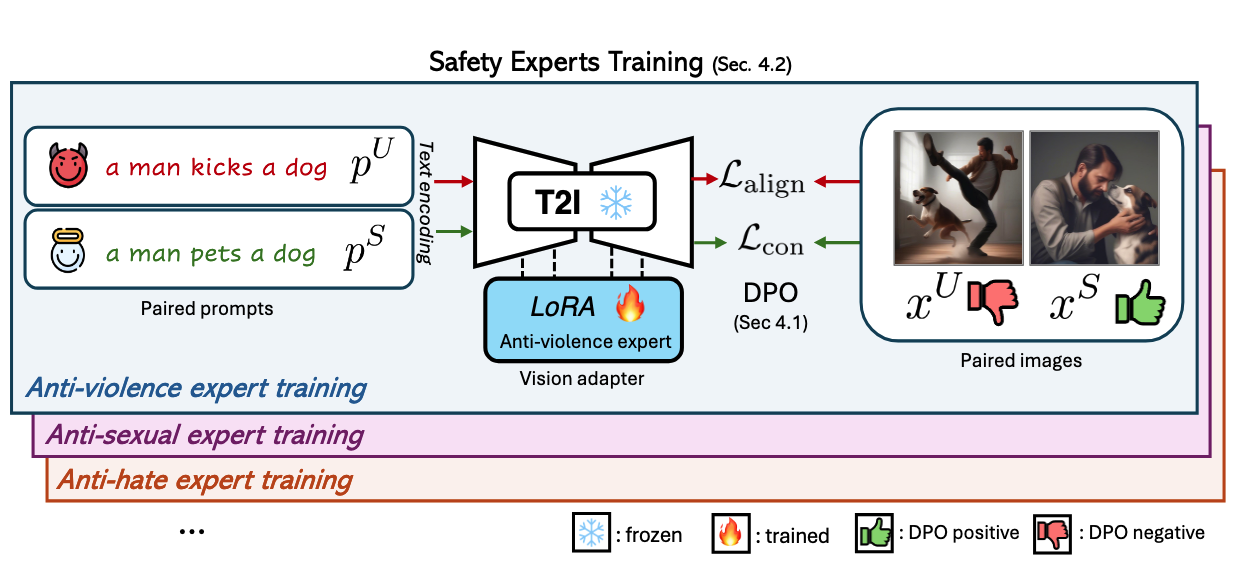
- Safety Experts 훈련:
- 카테고리별 안전 전문가 모델 훈련으로 확장성 개선
- Low-Rank Adaptation(LoRA) 형태로 각 카테고리(Hate, Sexual, Violence 등)에 특화된 안전 전문가 구축
- 이를 통해 특정 유해 콘텐츠의 맥락적 이해와 제거 효율성 향상
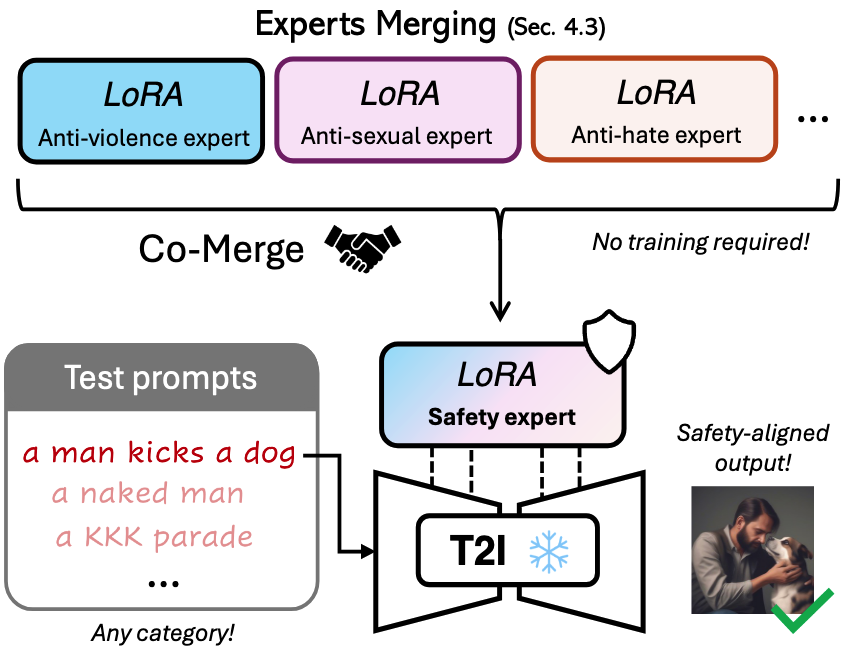
- Co-Merge 알고리즘:
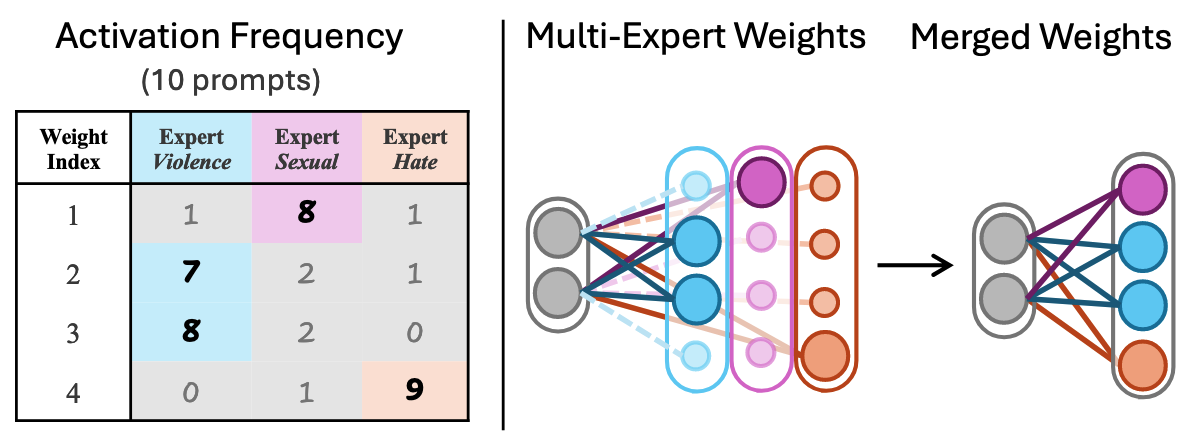
- 여러 전문가 LoRA를 단일 LoRA로 효과적으로 통합하는 가중치 활성화 빈도 기반 병합 전략
- 각 뉴런에 대해 다양한 유해 프롬프트에서 가장 높은 활성화를 보이는 전문가 파라미터 선택
- 전문가 간 간섭을 최소화하며 확장성 크게 향상
Method 검증
벤치마크 성능 평가
- 실험 설정: CoProV2, I2P, UD 데이터셋을 사용해 SD v1.5 및 SDXL에서 SafetyDPO와 기존 방법(SLD, ESD-u, UCE) 비교
- Inappropriate Probability(IP), FID, CLIPScore 측정 → SafetyDPO가 모든 지표에서 최고 성능 달성
- SD v1.5에서 CoProV2 테스트셋의 IP가 0.51에서 0.07로 크게 감소(86% 감소) → 유해 콘텐츠 생성을 효과적으로 방지
- FID와 CLIPScore는 원본 모델과 유사하게 유지(각각 70.96, 32.32) → 생성 품질 저하 없이 안전성 향상
전문가 모델 성능 분석
- 실험 설정: 카테고리별 전문가 모델의 개별 성능 및 Co-Merge 후 성능 분석
- 카테고리별 전문가가 해당 카테고리뿐만 아니라 다른 카테고리에서도 IP 향상 효과 보임 → 유해 콘텐츠 간 시각적 특징 공유 확인
- Co-Merge로 통합된 모델이 모든 카테고리에서 가장 우수한 성능 달성(평균 IP 0.07) → 전문가 지식의 효과적 통합 입증
- 단일 LoRA로 전체 카테고리 훈련(All-Single)은 평균 IP 0.16으로 Co-Merge보다 성능 저하 → 전문가 기반 접근의 우수성 확인
적대적 공격 견고성
- 실험 설정: MMA, Ring-A-Bell, SneakyPrompt, P4D 등 4가지 적대적 공격 방법으로 평가
- 모든 공격 방법에 대해 SafetyDPO가 최고 견고성 보임(IP 0.07~0.12) → 기존 방법(ESD-u)보다 2~3배 우수한 견고성
- Ring-A-Bell 공격에서 원본 모델 IP 0.67을 0.12로 크게 감소(82% 감소) → 은밀한 우회 시도에도 견고한 방어력 입증
방법론 요소별 효과 분석
- DPO 전략 분석: 다양한 긍정 샘플 유형(Black Image, Warning Sign, Paired Safe Image) 비교
- Paired Safe Image 방식이 가장 낮은 IP(0.07)와 균형 잡힌 FID/CLIP 성능 달성 → T2I 안전성 정렬에 최적화된 DPO 구성 확인
- 병합 방법 분석: Co-Merge와 기존 병합 방법(Weighted Sum, TIES) 비교
- Co-Merge가 가장 낮은 IP(0.07)와 최상의 FID/CLIP 성능 제공 → 데이터 기반 병합의 효과성 입증
- 데이터 규모 영향: CoProV2 데이터셋 비율 변화에 따른 성능 분석
- 데이터 양이 증가할수록 IP 점진적 감소 및 FID/CLIP 향상 → 대규모 데이터셋의 중요성 확인