PnP-GA+: Plug-and-Play Domain Adaptation for Gaze Estimation Using Model Variants
Appearance-based gaze estimation has garnered increasing attention in recent years. However, deep learning-based gaze estimation models still suffer from suboptimal performance when deployed in new domains, e.g., unseen environments or individuals. In our previous work, we took this challenge for the first time by introducing a plug-and-play method (PnP-GA) to adapt the gaze estimation model to new domains. The core concept of PnP-GA is to leverage the diversity brought by a group of model variants to enhance the adaptability to diverse environments. In this article, we propose the PnP-GA+ by extending our approach to explore the impact of assembling model variants using three additional perspectives: color space, data augmentation, and model structure. Moreover, we propose an intra-group attention module that dynamically optimizes pseudo-labeling during adaptation. Experimental results demonstrate that by directly plugging several existing gaze estimation networks into the PnP-GA+ framework, it outperforms state-of-the-art domain adaptation approaches on four standard gaze domain adaptation tasks on public datasets. Our method consistently enhances cross-domain performance, and its versatility is improved through various ways of assembling the model group.
Problem:: Deep Learning 기반 Gaze Estimation Model이 새로운 Domain(환경, 사람 등)에 적용될 때 발생하는 성능 저하 문제 / 기존 Domain Adaptation 방법들의 Label 의존성 및 UDA의 어려움
Solution:: 다양한 Model Variants Group의 예측 다양성을 활용하는 Plug-and-Play 방식의 UDA Framework (PnP-GA+) 제안 / Collaborative Learning, Outlier-Guided Adaptation, Intra-Group Attention Module을 통해 Adaptation 수행
Novelty:: Model Variants Group을 활용한 UDA 접근 방식 확장 (Color Space, Data Augmentation, Model Structure 관점 추가) / Adaptation 중 Pseudo-Label을 동적으로 최적화하는 Intra-Group Attention Module 제안 / Outlier-Guided Loss를 통한 효과적인 Adaptation
Note:: 한번의 Adaptation을 하기 위한 Group Pretraining이 너무 많음 / ICCV 2021년도 논문을 개선한 저널 논문이라 지금 시점에서는 약간 뒤쳐짐
Summary
Motivation
- Deep Learning 기반 Gaze Estimation Model은 학습 환경과 다른 새로운 Domain(예: 처음 보는 환경이나 사람)에 적용될 때 성능이 저하되는 문제를 겪음
- 이러한 Domain Gap은 학습 데이터와 테스트 데이터 간의 피사체, 배경, 조명 등의 차이로 인해 발생하며, 데이터 분포의 불일치로 인해 성능 저하를 야기
- 기존의 Fine-Tuning이나 Few-Shot Learning 방식은 Ground-Truth Label에 크게 의존하는데, 정확한 Head Pose 및 Gaze Point를 얻기 어려워 Label 확보가 쉽지 않음
- 따라서 Gaze Estimation 분야에서는 Unsupervised Domain Adaptation (UDA) 접근 방식이 중요해짐. UDA는 새로운 Domain에서 Label이 없는 데이터를 활용해야 하므로 더욱 어려운 과제임
- 이전 연구인 PnP-GA에서는 Pre-Training 중 서로 다른 Epoch에서 모델을 가져와 Model Group을 구성했지만, 다양성을 만드는 방법에 대한 추가적인 탐구가 필요했음
Method
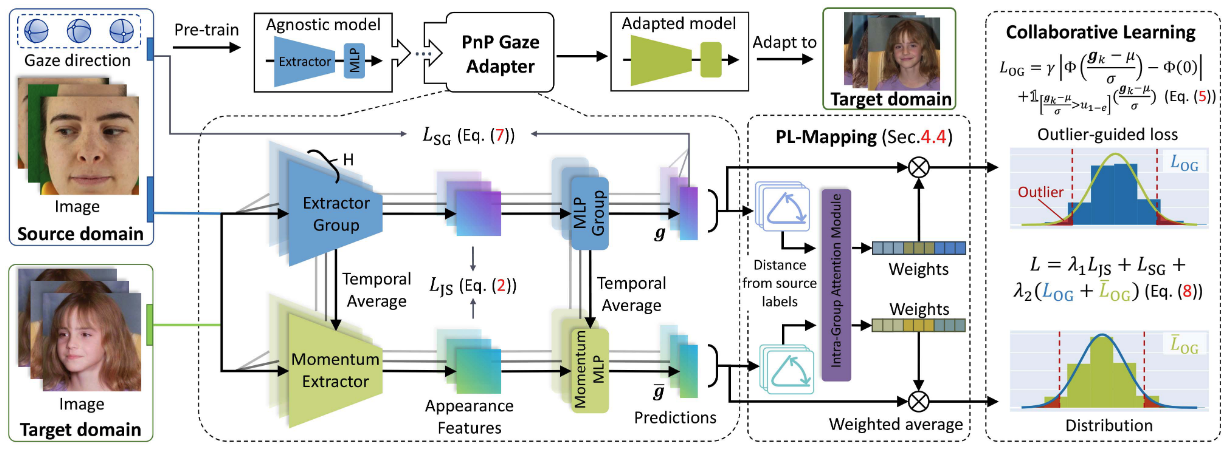
- PnP-GA+는 여러 변형 모델(Model Variants) 그룹의 예측 다양성을 활용하여 새로운 Domain에 Gaze Estimation Model을 적응시키는 Framework
- 준비: Model Variants로 구성된 Group
와, 이의 지수 이동 평균(EMA) 버전인 Momentum Group 를 초기화 - 학습 반복:
- Source 데이터 학습: Source 데이터 (
)로 Group 를 직접 학습 ( ) - Target 데이터 (
) 적응: - Pseudo-Label 생성: Momentum Group
의 Target 예측과 Source 데이터 기반 가중치( )를 사용하여 Target에 대한 Pseudo-Label( )을 생성 - 일관성 및 Outlier 제어:
- Group
와 Momentum Group 간 Feature 일관성 유지 ( ). - Group
의 예측이 Pseudo-Label( )에서 크게 벗어나지 않도록 함 ( ). - Momentum Group
의 예측도 Group 의 예측 경향에서 크게 벗어나지 않도록 함 ( ).
- Group
- Pseudo-Label 생성: Momentum Group
- 업데이트:
- 계산된 Loss들로 Group
의 파라미터( )를 업데이트 - Momentum Group
의 파라미터( )는 Group 의 파라미터를 EMA 방식으로 반영하여 업데이트
- 계산된 Loss들로 Group
- Source 데이터 학습: Source 데이터 (
- 완료: 학습 후, Group
의 모델 중 하나를 최종 적응된 모델로 선택
- 준비: Model Variants로 구성된 Group
세부 설명
- Collaborative Learning → Target이 들어왔을 때 Moving Average랑 원래 그룹이랑 Feature 분포 맞춤
- 두 개의 모델 그룹(기본 그룹 G, 시간적 평균을 내는 Momentum Group
)이 서로 학습을 도움 - 두 그룹 간 Feature 분포의 유사성을 유지 (
)
- 두 개의 모델 그룹(기본 그룹 G, 시간적 평균을 내는 Momentum Group
- Outlier-Guided Adaptation → 두 모델이 동일한 입력에 대해 서로의 예측에 너무 벗어나지 않도록 함
- Momentum Group
의 예측을 사용하여 Pseudo-Label (평균 , 분산 )을 생성 (PL-Mapping) - 이 Pseudo-Label을 기준으로 각 모델의 예측(
)이 정해진 범위 밖(Outlier)이면 더 큰 패널티를 부여하는 Loss ( ) 사용 - Source Domain의 실제 Label을 활용한 Loss (
)도 함께 사용 → Source 정보 안 까먹으려고
- Momentum Group
- Intra-Group Attention Module → 그룹 내 모델들의 예측을 그냥 사용하지 않고 더 좋은 모델의 예측에 가중치를 높여서 사용
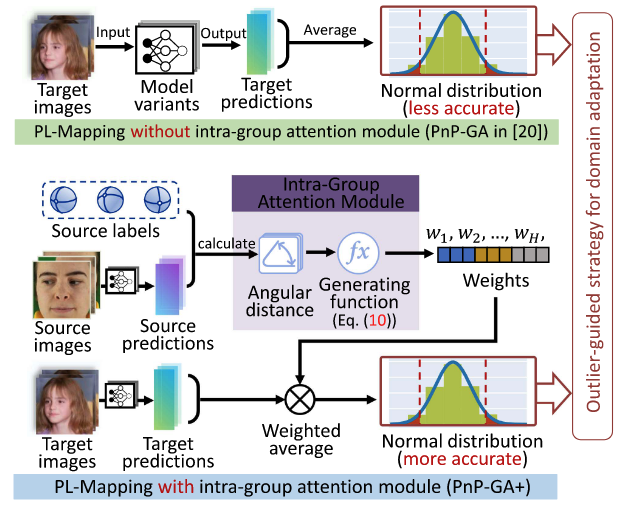
- Pseudo-Label 생성 시, 단순히 모델 예측을 평균 내는 대신, Source Domain 데이터에 대한 각 모델의 정확도에 따라 가중치(
)를 부여 - 더 정확한 모델이 Pseudo-Label 생성에 더 큰 영향을 미치도록 하여 Adaptation 성능 향상
- Pseudo-Label 생성 시, 단순히 모델 예측을 평균 내는 대신, Source Domain 데이터에 대한 각 모델의 정확도에 따라 가중치(
- Group Assembling → 여러 그룹들의 예측으로 더 좋은 Pseudo Label을 만들기 때문에 다양성 확보
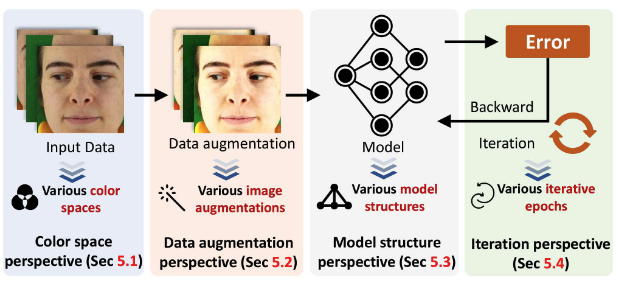
- Model Variants Group은 다음 네 가지 관점에서 다양하게 구성 가능:
- Color Space: 다른 색 공간으로 학습
- Data Augmentation: 다른 데이터 증강 기법 사용
- Model Structure: 다른 신경망 구조 사용
- Iteration: 학습 중 다른 Epoch의 모델 사용
- Model Variants Group은 다음 네 가지 관점에서 다양하게 구성 가능:
- 이러한 구성 요소들을 결합한 전체 Loss 함수 (
)를 최소화하며 Target Domain에 모델을 적응 - PnP-GA+는 기존 Gaze Estimation 모델을 그대로 가져와 적용할 수 있는 Plug-and-Play 방식
Method 검증
Plugging the Existing Gaze Estimation Networks
- 실험 방법: ResNet18, ResNet50, GazeTR, SWCNN (Facial Image Input), CA-Net, Dilated-Net (Face and Eye Image Input) 등 기존 Gaze Estimation Network들을 PnP-GA 및 PnP-GA+ Framework에 연결하여 Domain Adaptation 성능 향상을 평가
- 비교군: 각 Network의 Baseline (Domain Adaptation 없음), PnP-GA 적용, PnP-GA+ 적용
- 정량적 성능:
- 모든 Gaze Estimation Network가 4가지 Domain Adaptation Task (ETH-to-MPII, ETH-to-EyeDiap, Gaze360-to-MPII, Gaze360-to-EyeDiap)에서 PnP-GA/PnP-GA+ Framework를 통해 상당한 성능 향상을 달성
- PnP-GA+ Framework는 Baseline System 대비 ETH-to-MPII에서 39.1%, ETH-to-EyeDiap에서 33.2%, Gaze360-to-MPII에서 20.4%, Gaze360-to-EyeDiap에서 15.1%의 성능 향상을 달성 (ResNet18 기준)
- 통찰: 제안하는 PnP-GA+ Framework는 다양한 기존 Gaze Estimation Network의 Cross-Domain 성능을 일관되게 향상시킴
Comparison With State-of-the-Art Domain Adaptation Approaches
- 실험 방법: 제안하는 PnP-GA+ Framework를 UDA 분야의 SOTA 방법들과 Cross-Dataset Gaze Domain Adaptation 성능 비교
- 비교군: Baseline (ResNet18, No Adaptation), Fine-tune (Target Label 사용), Gaze360, GazeAdv, DAGEN, ADDA, GVBGD, UMA, PnP-GA
- 정량적 성능:
- ETH-XGaze
MPIIGaze: PnP-GA+ (Ours) 5.34 vs PnP-GA 6.18 vs DAGEN 6.61 - ETH-XGaze
EyeDiap: PnP-GA+ (Ours) 5.73 vs PnP-GA 5.53 vs GVBGD 7.27 - Gaze360
MPIIGaze: PnP-GA+ (Ours) 6.10 vs PnP-GA 5.87 vs Gaze360 5.97 - Gaze360
EyeDiap: PnP-GA+ (Ours) 7.62 vs PnP-GA 7.92 vs DAGEN 6.16
- ETH-XGaze
- 통찰: PnP-GA+는 대부분의 Task에서 SOTA UDA 방법들보다 우수한 성능을 보이며, Gaze Estimation에 효과적으로 Adaptation 함을 입증
Analysis of Group Assembling From Various Perspectives
- Color Space Perspective:
- 실험 방법: 다양한 Color Space에서 Pre-Trained 된 Model Variants (ResNet18)로 Group을 구성하고 PnP-GA+ 적용
- 정량적 성능: Baseline 대비 모든 Task에서 Gaze Estimation Error 감소 (예:
: 8.77 5.41 0.18) - 통찰: 다른 Color Space에서 얻은 Model Variants를 사용해도 PnP-GA+가 Target Domain 성능을 향상시킴
- Data Augmentation Perspective:
- 실험 방법: 다양한 Augmentation으로 Pre-Trained 된 Model Variants (ResNet18)로 Group을 구성하고 PnP-GA+ 적용
- 정량적 성능: Baseline 대비 모든 Task에서 Gaze Estimation Error 감소 (예:
: 8.77 6.11 0.67) - 통찰: 다른 Image Augmentation에서 얻은 Pre-Model을 사용해도 PnP-GA+가 Target Domain 성능을 향상시킴
- Model Structure Perspective:
- 실험 방법: ResNet18, ResNet50, ViT 구조의 Model Variants로 Group을 구성 (총 10개 모델)하고 PnP-GA+ 적용
- 정량적 성능: 모든 구조 조합에서 Cross-Domain 성능 향상
- 통찰: 다양한 구조의 Model Variants를 조합해도 PnP-GA+가 일관된 성능 향상을 제공
- Combination of Multiple Perspectives:
- 실험 방법: Iteration Perspective를 기본으로 다른 Perspective의 Model Variants를 추가하며 PnP-GA+ 효과 비교
- 정량적 성능: Iteration Perspective가 전반적으로 가장 좋은 성능을 보였으며, 다른 조합에서도 상당한 정확도 향상 달성
- 통찰: PnP-GA+는 다양한 Group 구성 방식에서 일관되게 성능 향상을 보이며, 이는 방법론의 적용 유연성이 높다는 것을 의미