Conflict-Averse Gradient Descent for Multi-task learning
The goal of multi-task learning is to enable more efficient learning than single task learning by sharing model structures for a diverse set of tasks. A standard multi-task learning objective is to minimize the average loss across all tasks. While straightforward, using this objective often results in much worse final performance for each task than learning them independently. A major challenge in optimizing a multi-task model is the conflicting gradients, where gradients of different task objectives are not well aligned so that following the average gradient direction can be detrimental to specific tasks' performance. Previous work has proposed several heuristics to manipulate the task gradients for mitigating this problem. But most of them lack convergence guarantee and/or could converge to any Pareto-stationary point.In this paper, we introduce Conflict-Averse Gradient descent (CAGrad) which minimizes the average loss function, while leveraging the worst local improvement of individual tasks to regularize the algorithm trajectory. CAGrad balances the objectives automatically and still provably converges to a minimum over the average loss. It includes the regular gradient descent (GD) and the multiple gradient descent algorithm (MGDA) in the multi-objective optimization (MOO) literature as special cases. On a series of challenging multi-task supervised learning and reinforcement learning tasks, CAGrad achieves improved performance over prior state-of-the-art multi-objective gradient manipulation methods.
Problem:: 다중 작업 학습에서 그래디언트 충돌 문제로 개별 작업 성능 저하 / 기존 방법들은 파레토-정지점에서 학습 중단되는 한계 존재 / 초기 파라미터에 따라 수렴점이 달라지는 예측 불가능성
Solution:: 파레토-정지점의 특성을 고려해 평균 손실 최소화하면서 개별 작업의 최악 방향으로 가지 않는 방식 제안 / 제안한 CAGrad가 파레토-정지점의 최적점 수렴에 대한 이론적 근거 제시 / 여러 태스크의 손실 함수 계산 연산량을 줄이기 위해 특정 Task만 이용하는 방식 제안
Novelty:: 기존 방식들의 파레토-정지점 문제 제기 / 이전 방식이 제안 방법의 특수 경우임을 보임 / 하이퍼파라미터 c로 알고리즘 동작 제어 가능
Note:: 전체 이익 최우선, 가장 반대하는 의견도 일정 수준 고려하는 접근법
Summary
Motivation
- 다중 작업 학습은 모델 구조를 공유하여 단일 작업 학습보다 효율적인 학습 가능성 제공
- 그러나 평균 손실을 직접 최적화하는 방식은 개별 작업의 성능을 크게 저하시키는 문제 발생
- 이러한 문제의 주요 원인은 충돌하는 그래디언트
- 서로 다른 작업의 그래디언트가 잘 정렬되지 않아 평균 그래디언트 방향을 따르는 것이 특정 작업에 해롭게 작용
- 그래디언트 크기의 불균형으로 일부 작업이 최적화를 지배하는 현상 발생
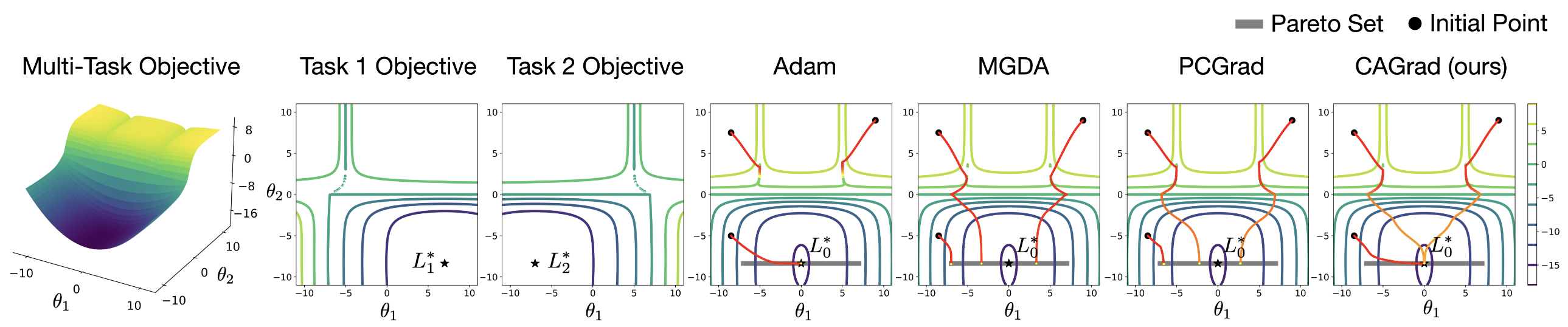
기존 방식들은 Pareto Set에서 더이상 학습되지 않음
- 기존 연구들(MGDA, PCGrad)의 근본적 한계
- Pareto Optimal(모든 작업이 동시에 개선되는 방향이 없는 지점)에 도달하면 학습이 중단됨
- 어떤 Pareto Optimal에 도달할지 초기 파라미터에 크게 의존하여 예측 불가능성 존재
- 일부 작업은 좋은 성능, 다른 작업은 나쁜 성능을 보이는 불균형 상태로 수렴 가능
- Pareto Set 내에서도 계속 학습하여 평균 손실 함수의 최소점에 도달할 수 있는 새로운 접근법 필요
Method
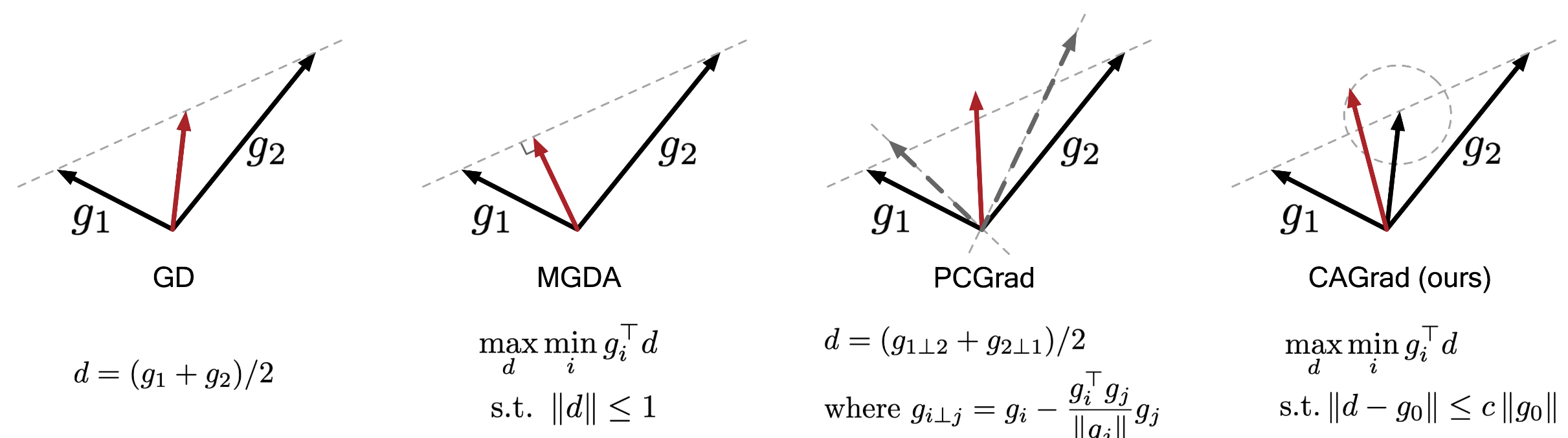
CAGrad (Conflict-Averse Gradient Descent)
- 핵심 아이디어: 현재 파라미터 업데이트로 인해 특정 태스크의 손실함수가 크게 높아지는 충돌 상황을 방지하기 위한 업데이트 벡터 탐색
- 파레토-정지점은 파라미터 변화가 특정 태스크의 손실 함수를 크게 높여 어느 방향으로 가도 평균 손실 함수 값이 유사함 → 특정 태스크의 손실 함수가 크게 되는 방향으로는 가지 않도록 규제
- 이 지표는 업데이트 후 작업들 중 가장 큰 손실 증가(또는 가장 작은 손실 감소)를 측정
이면 모든 작업의 손실이 감소하고, 이면 충돌이 발생하여 일부 작업의 손실이 증가 : Taylor 근사
- 최적화 문제:
s.t. - 모든 작업에 대해 가장 나쁜 상황(최소 개선 또는 최대 악화)을 최대한 좋게 만드는 방향 탐색
- 평균 그래디언트
주변의 제한된 영역 내에서 탐색하여 전체 목표에서 크게 벗어나지 않도록 함
- 수학적 직관
- MGDA: "모든 사람이 동의하는 방향으로만 가겠다"는 접근법으로, 의견 차이가 생기면 더 이상 나아갈 수 없음
- CAGrad: "전체적인 이익을 최우선으로 하되, 가장 반대하는 사람의 의견도 일정 수준 고려하겠다"는 균형 접근법으로, 특정 지점에서 멈추지 않고 계속 진행 가능
- 계산 효율성을 위한 실용적 가속화
- 작업의 부분집합
만 샘플링하여 그래디언트 계산 - 시간 복잡도:
( : 역전파 시간, : 최적화 시간)
- 작업의 부분집합
Dual Problem
- 최적화 문제는 모델 파라미터와 같은 차원의
를 구해야 하므로 직접 계산이 어려움 - Dual problem으로 변환하여 작업 수
차원의 결정 변수 로 문제 해결: , 여기서 는 확률 단체(probability simplex)로, 이고 을 만족
- 계산 효율성:
는 수백만 차원일 수 있지만 는 작업 수( ) 차원으로 대폭 축소 - 표준 최적화 라이브러리를 사용하여 효율적으로 계산 가능
- 수렴 보장
: CAGrad의 모든 고정점은 파레토-정지 점 : 평균 손실 의 정지점으로 수렴 보장 - 이론적 증명:
- 이 불등식은 알고리즘이 평균 손실 함수의 최소점으로 수렴함을 수학적으로 보장
Method 검증
Toy Project
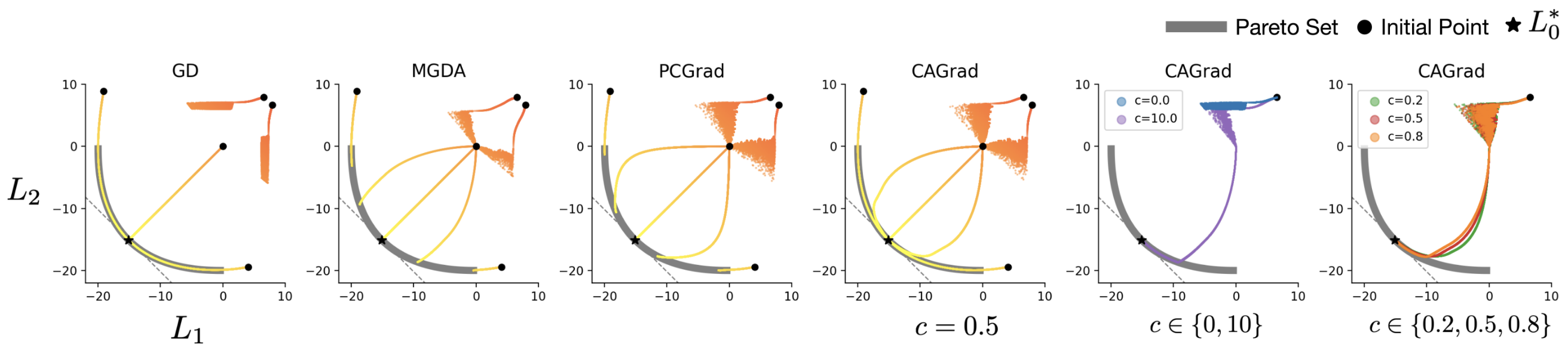
- 2D 최적화 문제에서 GD, MGDA, PCGrad, CAGrad 비교
- GD: 5번 중 2번 진행이 멈춤
- MGDA, PCGrad: 초기 파라미터에 따라 다른 파레토-정지점 수렴
- CAGrad:
값에 따라 GD와 MGDA 사이의 행동 보임
- 비교 결과: CAGrad가 가장 안정적이고 예측 가능한 수렴 패턴 보임
실험 결과
- Multi-Task Supervised Learning
- NYU-v2 데이터셋 (3가지 작업)
- CAGrad: 다른 방법들이 간과하는 Surface Normal 작업에서 더 나은 성능
- 평균 작업 성능 하락률(Δm%) 0.20% (기존 방법들 1.38~6.96%)
- CityScapes 데이터셋 (2가지 작업)
- CAGrad: Depth 작업에서 성능 향상
- 평균 작업 성능 하락률(Δm%) 11.64% (기존 방법들 18.29~90.02%)
- NYU-v2 데이터셋 (3가지 작업)
- Multi-Task Reinforcement Learning
- Meta-World MT10 (10개 작업) 및 MT50 (50개 작업) 벤치마크
- CAGrad: 성공률 MT10 0.83, MT50 0.52 달성 (기존 방법들 0.49~0.73, 0.36~0.50)
- CAGrad-Fast: MT10 0.82, MT50 0.50의 성공률 달성하면서 각각 2배, 5배 속도 향상
- 비교 결과: CAGrad가 언어 메타데이터를 활용하는 CARE(0.84, 0.54)를 제외한 모든 방법 중 최고 성능 달성
- Meta-World MT10 (10개 작업) 및 MT50 (50개 작업) 벤치마크
- Semi-supervised Learning with Auxiliary Tasks
- CIFAR10 데이터셋에서 500, 1000, 2000개 레이블 실험
- CAGrad: 모든 설정에서 가장 높은 평균 테스트 정확도 달성
- MGDA: 주요 분류 작업을 간과하여 기준선보다 크게 낮은 성능
- 비교 결과: CAGrad가 주 작업과 보조 작업 간의 균형을 효과적으로 유지
- CIFAR10 데이터셋에서 500, 1000, 2000개 레이블 실험