Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Modern large language models (LLMs) like ChatGPT have shown remarkable performance on general language tasks but still struggle on complex reasoning tasks, which drives the research on cognitive behaviors of LLMs to explore human-like problem-solving strategies. Along this direction, one representative strategy is self-reflection, which asks an LLM to refine the solution with the feedback generated by itself iteratively. However, our study shows that such reflection-style methods suffer from the Degeneration-of-Thought (DoT) problem: once the LLM has established confidence in its solutions, it is unable to generate novel thoughts later through reflection even if its initial stance is incorrect. To address the DoT problem, we propose a Multi-Agent Debate (MAD) framework, in which multiple agents express their arguments in the state of "tit for tat" and a judge manages the debate process to obtain a final solution. Clearly, our MAD framework encourages divergent thinking in LLMs which would be helpful for tasks that require deep levels of contemplation. Experiment results on two challenging datasets, commonsense machine translation and counter-intuitive arithmetic reasoning, demonstrate the effectiveness of our MAD framework. Extensive analyses suggest that the adaptive break of debate and the modest level of "tit for tat" state are required for MAD to obtain good performance. Moreover, we find that LLMs might not be a fair judge if different LLMs are used for agents. Code is available at https://github.com/Skytliang/Multi-Agents-Debate.
Problem:: LLM의 Self-Reflection에서 발생하는 Degeneration-of-Thought (DoT) 문제 / LLM이 초기 답변에 확신을 가지면 틀린 답이어도 새로운 사고를 생성하지 못함 / 편향된 인식, 변화 저항성, 제한된 외부 피드백으로 인한 자기 교정 실패
Solution:: Multi-Agent Debate (MAD) 프레임워크 제안 / 여러 에이전트가 "tit for tat" 상태로 토론하며 발산적 사고 유도 / Judge가 Adaptive Break로 최적 시점에 토론 종료 및 답변 추출 / Meta Prompts로 건설적 대립 수준 조절
Novelty:: DoT 문제를 최초로 정의하고 실증적으로 입증 / 인간의 토론 메커니즘을 LLM에 적용한 창의적 접근 / GPT-3.5-Turbo + MAD가 GPT-4 성능을 능가함을 보임 / 동일 LLM 사용 시 최적 성능, Judge의 편향 문제 발견
Note:: Multi Agent 사용에 실용적인 부분이 꽤 많이 담겨 있음 (모델 종류 및 성능에 따른 역할 분배, 토론의 방향성에 따른 차이, 토론 길이에 따른 차이 등)
Summary
Motivation
현재 LLM의 한계와 Self-Reflection의 문제점
- 최신 LLM (ChatGPT 등)이 일반적인 언어 과제에서는 뛰어나지만, 복잡한 추론 과제에서는 여전히 실패
- 이를 해결하기 위해 인간의 문제 해결 전략인 Self-Reflection을 모방
- Self-Reflection: LLM이 자신의 답변을 생성 → 스스로 피드백 생성 → 피드백 기반으로 답변 개선을 반복
- 문제점: 자기 평가 능력이 보장되지 않음
Degeneration-of-Thought (DoT) 문제 - 본 논문에서 처음으로 정의
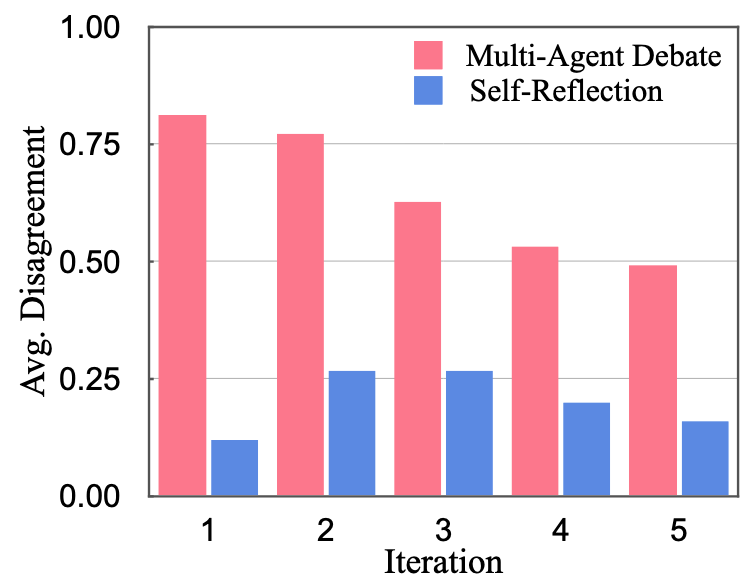
- DoT의 정의: "LLM 기반 에이전트가 한번 자신의 답변에 확신을 갖게 되면, 초기 입장이 틀렸더라도 Self-Reflection을 통해 새로운 생각을 생성하지 못하는 현상"
- 실증적 증거:
- Self-Reflection에서 평균 Disagreement가 5회 반복 동안 0.25 이하로 매우 낮음
- 즉, LLM이 초기의 틀린 답변을 고수하며 의미 있는 Self-Reflection을 하지 못함
- 반면 Multi-Agent Debate는 0.5 이상의 Disagreement 유지 → 다양한 사고 가능
DoT 발생의 3가지 주요 원인
- 편향과 왜곡된 인식 (Bias and Distorted Perception)
- 사전학습 중 대량의 데이터에서 학습된 편향과 선입견
- 이러한 편향에 의해 흐려진 Self-Reflection은 부정확한 결론 도출
- 경직성과 변화 저항 (Rigidity and Resistance to Change)
- Self-Reflection은 자신의 신념과 가정에 도전해야 하지만
- LLM이 경직된 신념을 가지면 더 나은 답변으로 이어지는 의미 있는 성찰이 어려움
- 제한된 외부 피드백 (Limited External Feedback)
- Self-Reflection은 본질적으로 내부 프로세스
- 외부 피드백 없이는 중요한 맹점이나 대안적 관점을 놓침
Method
Multi-Agent Debate (MAD) Framework의 핵심 아이디어
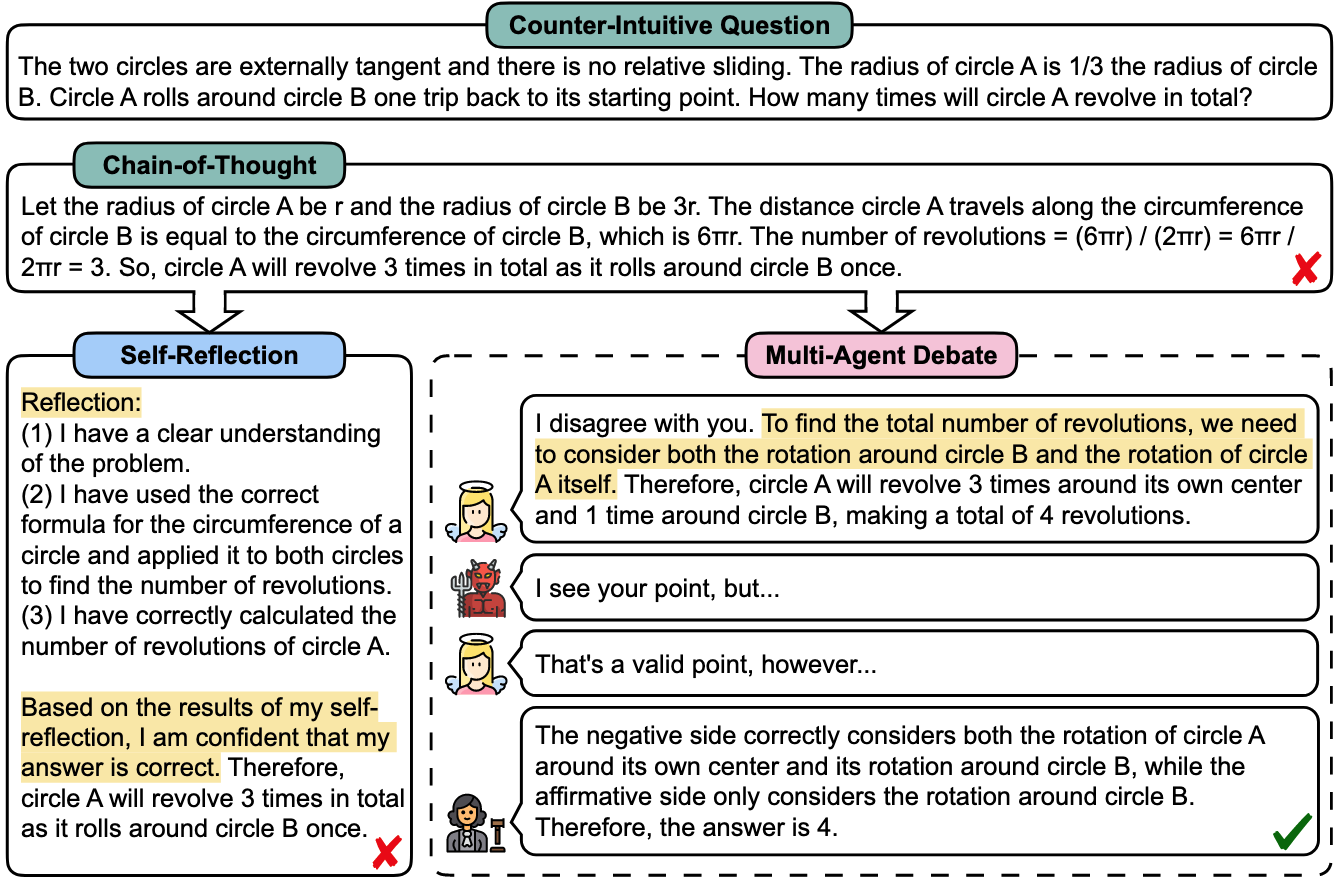
문제: Circle A (반지름 r)가 Circle B (반지름 3r) 주위를 한 바퀴 돌 때 총 회전 수는?
- Chain-of-Thought 오답: 둘레 비율만 계산하여 3회전
- Self-Reflection 실패: "I am confident that my answer is correct"라며 3회전 고수
- MAD 성공 과정:
- Affirmative: "둘레 비율로 계산하면 3회전"
- Negative: "Circle B 주위 회전 + Circle A 자체 회전 고려해야 함"
- Judge: "Negative side가 맞음. 답은 4회전"
- 인간의 토론(Debate) 특성을 활용: 여러 에이전트가 서로 논쟁하며 발산적 사고 촉진
- DoT 문제 해결 원리:
- 한 에이전트의 왜곡된 사고를 다른 에이전트가 교정
- 한 에이전트의 변화 저항을 다른 에이전트가 보완
- 각 에이전트가 다른 에이전트로부터 외부 피드백 획득
MAD의 3가지 구성 요소
- Meta Prompts - 토론 환경 설정
- 토론 주제, 참가자 수, 반복 제한 등을 명시
- 핵심: "tit for tat" (맞대응) 분위기 조성
- 예시: "You are a debater. It's not necessary to fully agree with each other's perspectives, as our objective is to find the correct answer"
- Debaters - 토론 참가자들
- N명의 토론자
가 고정된 순서로 발언 - 이전 토론 이력 H를 바탕으로 주장 전개:
- Affirmative Side (긍정측): 초기 입장 제시
- Negative Side (부정측): "I disagree with you"로 시작하며 반박과 대안 제시
- 핵심: 서로 다른 관점을 적극적으로 표현
- N명의 토론자
- Judge - 토론 관리자
- Discriminative Mode: 매 라운드 후 올바른 해답 도출 여부 판단
- Extractive Mode: 반복 제한에 도달하면 전체 토론 이력에서 최종 해답 추출
- Adaptive Break: 최적 시점에 토론을 종료하는 핵심 메커니즘
- Discriminative Mode: 매 라운드 후 올바른 해답 도출 여부 판단
Method 검증
Common MT (Commonsense Machine Translation) - 상식적 기계번역의 도전과제
- 데이터셋의 3가지 모호성 유형과 구체적 예시
- Lexical Ambiguity (어휘적 모호성) - 같은 단어, 다른 의미
- 핵심 도전: 하나의 단어가 문맥에 따라 완전히 다른 의미를 가짐
- 대표 예시: "吃掉敌人一个师"
- 직역: "적 하나의 사단을 먹어버리다"
- 문제점: 중국어 "吃掉"는 일상에서 "먹다"지만, 군사 용어로는 "섬멸하다"
- 기존 방법들의 실패: "Eat up an enemy division" ❌
- MAD의 성공: "Eliminate an enemy division" ✓
- 토론 핵심: "군사적 맥락에서 '吃掉'는 적의 완전한 파괴를 의미"
- Contextless Syntactic Ambiguity (문맥 없는 구문적 모호성) - 누가 주어인가?
- 핵심 도전: 중국어는 주어/목적어 표시가 불명확해 상식으로 판단 필요
- 대조적 예시:
- "正在手术的是健康的医生" → 의사가 수술을 하는 중 (상식상 당연)
- "正在手术的是生命垂危的病人" → 환자가 수술을 받는 중 (위독한 환자는 수술 못 함)
- MAD의 해결: 토론을 통해 "건강한 의사"와 "위독한 환자"의 역할을 상식적으로 구분
- Contextual Syntactic Ambiguity (문맥적 구문 모호성) - 누가 도움을 주고받나?
- 핵심 도전: 같은 구조, 다른 상황에 따라 의미가 반대로
- 상황별 해석:
- "当地震袭击中国时,援助的是中国"
- 상식: 자국 재난 → 중국이 원조를 받음 ✓
- "当地震袭击日本时,援助的是中国"
- 상식: 타국 재난 → 중국이 원조를 제공 ✓
- "当地震袭击中国时,援助的是中国"
- MAD의 강점: 재난 상황의 국제 관계 상식을 토론을 통해 반영
- Lexical Ambiguity (어휘적 모호성) - 같은 단어, 다른 의미
- 실험 결과
- 정량적 성능:
- Lexical: GPT-3.5 + MAD (HUMAN 3.78) > GPT-4 (3.41)
- Contextless: GPT-3.5 + MAD (3.67) > GPT-4 (3.63)
- Contextual: GPT-3.5 + MAD (3.67) > GPT-4 (3.65)
- 핵심 발견: 모든 모호성 유형에서 MAD가 Self-Reflect보다 우수
- Self-Reflect는 초기 편향 ("吃=eat")을 극복하지 못함
- MAD는 토론을 통해 문맥과 상식을 적극 활용
- 정량적 성능:
Counter-Intuitive AR - 반직관적 산술 추론의 함정
- 데이터셋 설계 철학
- 기반 이론: 인간의 이중 사고 시스템 (Kahneman, Thinking, fast and slow, 2017)
- System 1: 빠르고 직관적 → 틀리기 쉬운 답
- System 2: 느리고 논리적 → 정확하지만 노력 필요
- 200개 문제 구성:
- Elicitation Questions (인지 편향 유도 문제)
- 웹 수집 퍼즐
- 수동으로 만든 변형 문제들
- 기반 이론: 인간의 이중 사고 시스템 (Kahneman, Thinking, fast and slow, 2017)
- 데이터 셋 핵심 특징
- Resistance to Intuition (직관에 대한 저항): 매력적이지만 틀린 답변을 유도하는 숨겨진 함정
- 예시: Alice의 평균 속도 문제
- 오르막 1m/s, 내리막 3m/s → 평균은?
- 직관적 오답: (1+3)/2 = 2m/s ❌
- 올바른 답: 조화평균 사용 → 1.5m/s ✓
- 설명: 거리가 같을 때 시간이 다르므로 단순 평균 불가
- 예시: Alice의 평균 속도 문제
- Multi-Step Reasoning (다단계 추론 요구)
- 원 굴리기 문제 (Main Figure):
- Circle A (반지름 r)가 Circle B (반지름 3r) 주위를 한 바퀴
- 직관: 둘레 비율 = 6πr/2πr = 3회전 ❌
- 정답: Circle B 주위 회전(3) + 자체 회전(1) = 4회전 ✓
- MAD의 토론: "자체 회전도 고려해야 한다"는 통찰 도출
- 원 굴리기 문제 (Main Figure):
- Resistance to Intuition (직관에 대한 저항): 매력적이지만 틀린 답변을 유도하는 숨겨진 함정
- 실험 결과
- 정략적 성능:
- Baseline GPT-3.5: 26.0% - 전략 없이 직접 답변
- Self-Reflect: 27.5% - 자기 검토 반복하지만 DoT로 실패
- CoT: 28.0% - "step by step" 추론해도 직관적 함정에 빠짐
- Self-Consistency: 29.5% - 한 모델이 질문에 여러번 답변 후 가장 많이 나온 것 선택
- MAD: 37.0% - 토론으로 직관적 오답을 논리적으로 교정 ✓
- MAD 성공 요인:
- 한 에이전트의 직관적 오류를 다른 에이전트가 논리적으로 반박
- 토론 과정에서 숨겨진 조건들이 명시적으로 드러남
- 정략적 성능:
추가 분석
- DoT 완화 효과의 정량적 측정
- Bias 감소:
- 상식에 맞지 않는 번역 비율: 29.0% → 24.8%
- 의미: 편향된 사고가 토론을 통해 교정됨
- Diversity 증가:
- 답변 다양성: 19.3% → 49.7% (2.5배 증가)
- 측정법: 100 - Self-BLEU(초기답변, 현재답변)
- 의미: 고정관념에서 벗어나 창의적 사고 가능
- Bias 감소:
- 토론 전략의 최적화
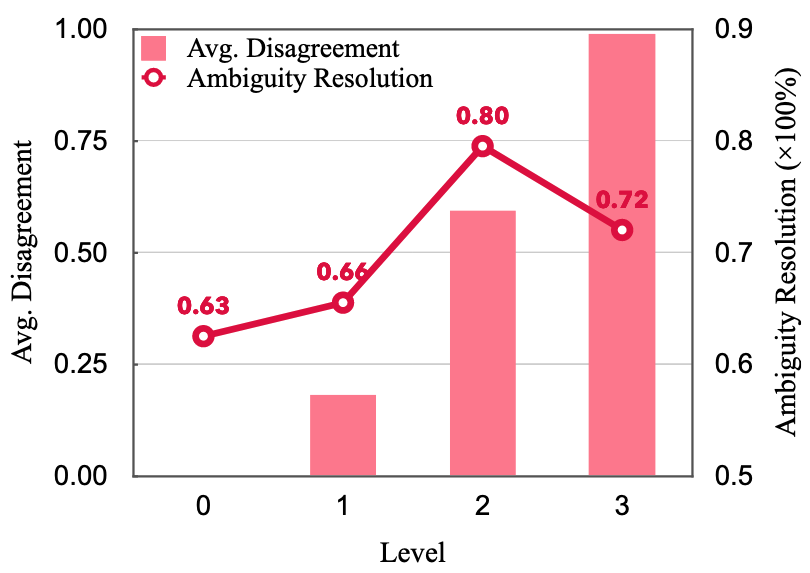
- "Tit for Tat" 수준별 성능: Meta Prompt에서 논의 수준 지시 정도
- Level 0 (완전 합의 요구): 최저 성능 → 양쪽 다 동의하는 결론에 도달해야 함
- Level 1 (부분적 합의 요구): 낮은 성능
- Level 2 (적절한 불일치): 최고 성능
- Level 3 (완전 불일치 강요): 오히려 성능 저하 → 양쪽 다 무조건 반박해야 함
- 통찰: 건설적 비판은 도움이 되지만, 무조건적 반대는 역효과
- "Tit for Tat" 수준별 성능: Meta Prompt에서 논의 수준 지시 정도
- 토론자 수에 따른 성능 결과
- 실험 결과: 2명(기본) → 3명 → 4명으로 증가할수록 성능 지속적 하락
- 원인: 토론 내용이 길어지면서 LLM이 이전 발언을 망각하고 Judge가 정보 종합에 실패
- 핵심 통찰: 현재 LLM의 긴 텍스트 처리 한계로 인해 "많을수록 좋다"는 직관과 반대 결과
- Adaptive Break (적정 라운드에서 토론을 종료시키는 것)의 중요성:
- 토론 라운드 분포: 낮은 Human Score (어려운 문제) 일 수록 더 많은 라운드를 요구함
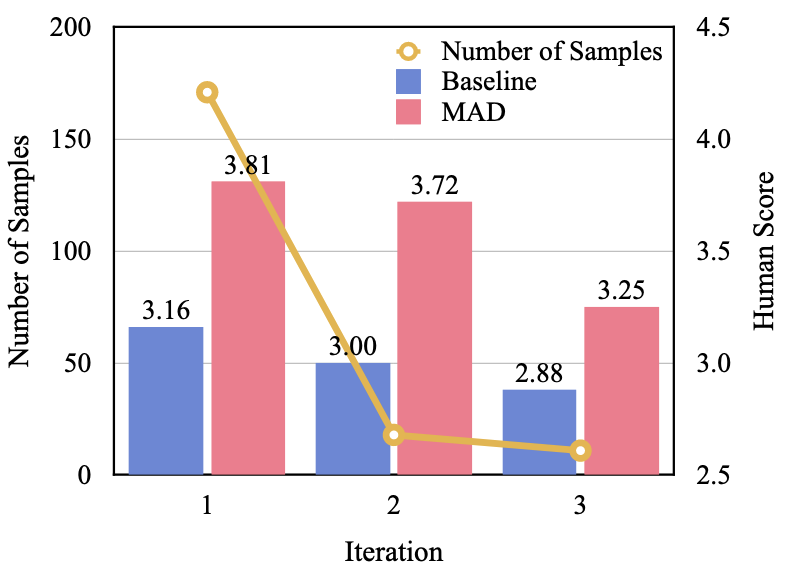
- 간단한 문제: 1라운드에서 해결 (효율성)
- 복잡한 문제: 추가 라운드 필요 (적응성)
- 성능 영향: Judge가 적절히 종료하지 않고 라운드가 진행되면 오히려 성능이 떨어짐
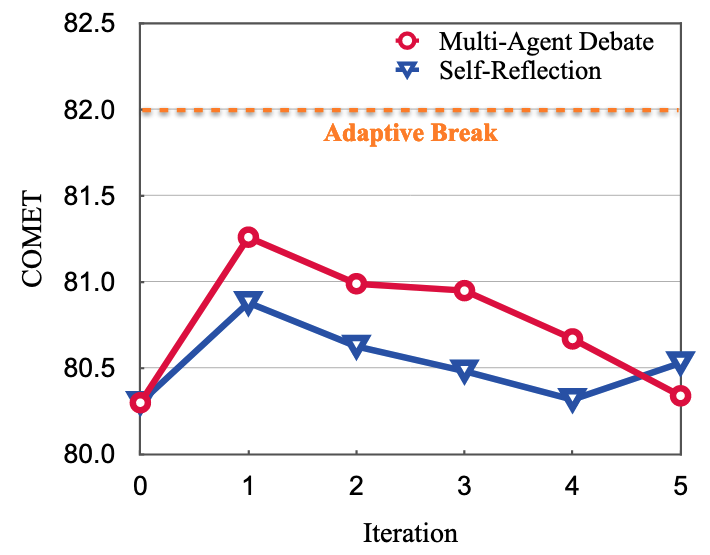
- 고정 라운드 방식 (매 라운드 답변 생성)보다 적절한 라운드에 토론을 끝내고 답변 생성하는 방식이 COMET 점수 15% 향상 → 과도한 토론은 오히려 좋은 답변을 망칠 수 있음
- 토론 라운드 분포: 낮은 Human Score (어려운 문제) 일 수록 더 많은 라운드를 요구함
- Judge의 LLM 종류에 따른 성능 차이: 각 Agent의 모델 종류에 따른 분석
- 발견 1: 토론자의 품질 > 심판의 품질 → Judge보다 토론자한테 더 좋은 API를 써라
- GPT-3.5 토론자 + Vicuna 심판: HUMAN 3.47
- Vicuna 토론자 + GPT-3.5 심판: HUMAN 3.25
- 발견 2: LLM의 자기 편향 문제 → 모든 Agent는 동일한 모델을 써라
- 서로 다른 LLM 사용 시 심판이 같은 모델 선호
- 발견 1: 토론자의 품질 > 심판의 품질 → Judge보다 토론자한테 더 좋은 API를 써라