Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
In this paper we present Mask DINO, a unified object detection and segmentation framework. Mask DINO extends DINO (DETR with Improved Denoising Anchor Boxes) by adding a mask prediction branch which supports all image segmentation tasks (instance, panoptic, and semantic). It makes use of the query embeddings from DINO to dot-product a high-resolution pixel embedding map to predict a set of binary masks. Some key components in DINO are extended for segmentation through a shared architecture and training process. Mask DINO is simple, efficient, and scalable, and it can benefit from joint large-scale detection and segmentation datasets. Our experiments show that Mask DINO significantly outperforms all existing specialized segmentation methods, both on a ResNet-50 backbone and a pre-trained model with SwinL backbone. Notably, Mask DINO establishes the best results to date on instance segmentation (54.5 AP on COCO), panoptic segmentation (59.4 PQ on COCO), and semantic segmentation (60.8 mIoU on ADE20K) among models under one billion parameters. Code is available at \url{https://github.com/IDEACVR/MaskDINO}.
Problem:: Segmentation과 Detection을 통합한 모델이 개별 특화 모델보다 성능이 낮음
Solution:: DINO의 Detection 특화 부분을 Segmentation에 적용되도록 개선
Novelty:: 통합 모델 제안/Task 학습 속도 차이를 이용한 Anchor Query 초기화
Note:: Unified 모델 제안을 주요 Novelty로 제안하였으나, Unified의 장점이 부각되지 않음
Summary
Motivation
- 기존의 접근법들은 대부분 Detection과 Segmentation을 별도의 모델로 분리하여 개별적으로 발전
- Faster RCNN은 물체 검출, Mask RCNN은 인스턴스 분할, FCN은 시맨틱 분할과 같은 특정 작업에만 특화된 구조로 설계 → 작업 간 상호 협력이 제한적
- 최근에는 DETR 계열의 Transformer 기반 모델들이 등장하여 물체 검출 및 분할 분야에서 두각을 나타냄 → Detection과 Segmentation을 통합한 단일 모델의 성능은 개별 특화된 모델에 미치지 못함
Unified .vs Specific + Other Task

- 둘 다 합쳐 놓으면 개별 모델보다 성능이 저하됨
DETR 계열 모델에서 통합된 모델이 특화 모델을 대체하지 못하는 이유
- Transformer 기반 모델들이 Detection (DINO)과 Segmentation (Mask2Former)에서 각각 뛰어난 성능을 보였음에도 불구하고, 한 모델로 두 가지 작업을 동시에 처리하려고 하면 성능이 저하되는 현상이 발생
- Segmentation은 Pixel-Level Classification, Detection은 Region-Level Regression
- Mask2Former의 쿼리는 픽셀 유사도를 비교하여 마스크 생성 → 영역 위치 정보:LiArrowDown:
- DINO의 쿼리는 높은 수준의 위치 정보와 의미론적 정보를 가짐 → Pixel-Level 정보 처리 최적화 X
Mask2Former가 검출을 잘 못하는 이유
- Mask2Former는 Conditional DETR, Anchor DETR, DAB-DETR과 같이 향상된 위치적 사전 지식을 활용 X
- 디코더 내에서 Masked Attention 방식을 사용하여 유연성이 부족 → 박스 예측에 적합하지 않음
- Mask2Former는 Dynamic Box Refinement가 어렵고 멀티 스케일 특징 활용이 제한적 → 단순 Detection Head를 추가하는 방식으로는 DINO 대비 성능 저하
DINO가 분할을 잘 못하는 이유
- DETR의 Segemtation Head: 작은 특성맵에만 쿼리 적용, 고해상도 특징 사용 X → 성능 저하
- DINO의 주요 구성요소들(쿼리 형성, 디노이징 트레이닝 등)이 Region-Level Representation을 강화하기 위해 설계 → Pixel-Level Segmentation 최적화 X
Method
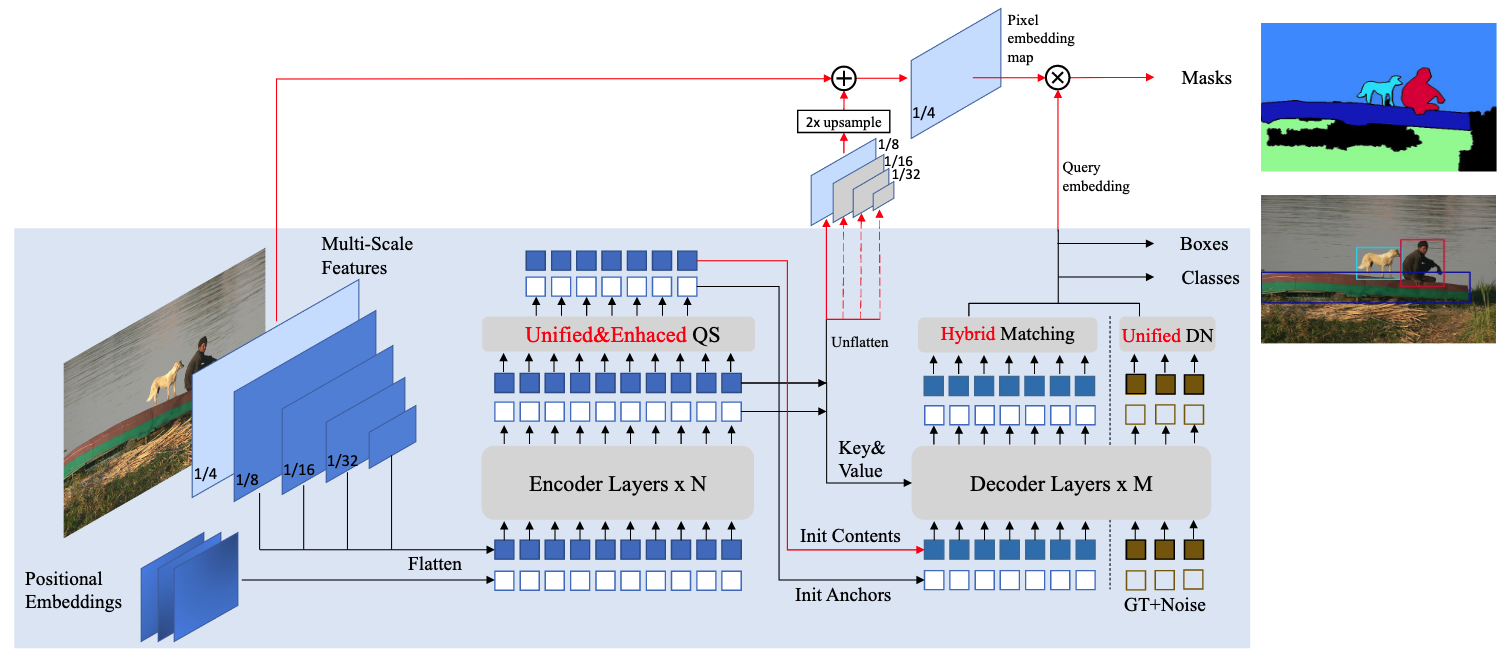
옅은 파란 상자는 기존 DINO의 방식, 변형된 것은 빨간색으로 표현
Segmentation Branch
-
DINO는 Region-Level의 Box Regression에 최적화되어 Pixel-Level Alignment가 부족 → 고해상도의 Pixel Embedding Map을 생성한다.
- Pixel Embedding Map: Backbone에서 생성된 고해상도 특징맵 (1/4 Resolution)과 Transformer Encoder에서 생성된 저해상도 특징맵(1/8 Resolution)을 융합하여 생성
-
Mask는 다음의 식으로 계산 방식:
: Convolution Layer : Interpolation Function : Backbone Feature Map : Transformer Encoder Feature Map : Content Query
Unified & Enhanced QS (Query Selection)
- 인코더에서 높은 분류 점수를 가진 토큰을 선별
- 디코더의 초기 쿼리 (Content Query)로 전달
- 이를 이용해 초기 마스크 및 박스를 예측
- Anchor Query를 마스크에서 도출해 품질 향상
- Segmentation이 초기에 더 빠르게 수렴하기 때문에, 초기 마스크 예측이 박스 예측보다 더 정확함 → 초기 마스크에서 예측된 영역을 활용해 초기 박스를 설정
Hybrid Matching
- Mask DINO는 박스와 마스크를 병렬적으로 예측하며, 이 둘이 서로 일치하지 않는 경우가 발생할 수 있음
- 기존 bipartite matching (클래스 및 박스 예측 기반)에 추가로 마스크 예측 손실(mask prediction loss)을 결합
- 최종적으로 매칭 비용은 클래스, 박스, 마스크 손실의 가중합 형태로 구성된다:
Unified DN (Unified Denoising Training)
- DINO에서 사용한 Query Denoising 훈련을 Segmentation 작업으로 확장
- 박스를 마스크의 Less Fine-Grained 표현으로 간주 → 박스를 마스크의 Noise 버전으로 취급하여 Denoising 수행