Measuring the Intrinsic Dimension of Objective Landscapes
Many recently trained neural networks employ large numbers of parameters to achieve good performance. One may intuitively use the number of parameters required as a rough gauge of the difficulty of a problem. But how accurate are such notions? How many parameters are really needed? In this paper we attempt to answer this question by training networks not in their native parameter space, but instead in a smaller, randomly oriented subspace. We slowly increase the dimension of this subspace, note at which dimension solutions first appear, and define this to be the intrinsic dimension of the objective landscape. The approach is simple to implement, computationally tractable, and produces several suggestive conclusions. Many problems have smaller intrinsic dimensions than one might suspect, and the intrinsic dimension for a given dataset varies little across a family of models with vastly different sizes. This latter result has the profound implication that once a parameter space is large enough to solve a problem, extra parameters serve directly to increase the dimensionality of the solution manifold. Intrinsic dimension allows some quantitative comparison of problem difficulty across supervised, reinforcement, and other types of learning where we conclude, for example, that solving the inverted pendulum problem is 100 times easier than classifying digits from MNIST, and playing Atari Pong from pixels is about as hard as classifying CIFAR-10. In addition to providing new cartography of the objective landscapes wandered by parameterized models, the method is a simple technique for constructively obtaining an upper bound on the minimum description length of a solution. A byproduct of this construction is a simple approach for compressing networks, in some cases by more than 100 times.
Problem:: 신경망이 많은 파라미터를 사용하지만 실제 필요한 파라미터 수 불명확 / 목적 함수 공간의 본질적 복잡성 측정 방법 부재 / 파라미터 효율성과 문제 난이도 비교를 위한 정량적 지표 필요
Solution:: 원본 파라미터 공간(
Novelty:: 다양한 문제와 모델의 본질적 복잡성을 정량적으로 측정하는 간단한 방법 제시 / 모델 크기가 증가해도 Intrinsic Dimension이 거의 일정하게 유지되는 현상 발견 / 다른 학습 유형(지도학습, 강화학습) 간 문제 난이도 비교 가능 / 신경망 압축을 위한 효율적 접근법 제공
Note:: Intrinsic Dimension 개념을 처음으로 도입 / CNN은 Random MNIST 학습시 Intrinsic Dimension이 커지지만 FC는 그렇지 않음 → 문제 난이도를 이걸로 정의할 수 있음
Summary
Motivation
- 신경망 학습은 목적 함수 공간(Objective Landscape)에서 경로를 탐색하는 과정
- 많은 최근 모델들이 수백만 개의 파라미터를 사용하지만, 실제로 필요한 파라미터 수는 얼마인지에 대한 의문 제기
- 기존 연구들이 고차원 목적 함수 공간의 구조에 대한 통찰을 제공했으나, 파라미터 공간의 본질적 자유도는 명확히 측정되지 않음
- 고차원 공간에서의 직관과 실제 특성 간의 불일치 존재
- 지역 최적점(Local Optima)보다 안장점(Saddle Points)이 더 일반적
- 최적화 경로가 예상보다 단순한 형태를 가짐
Method
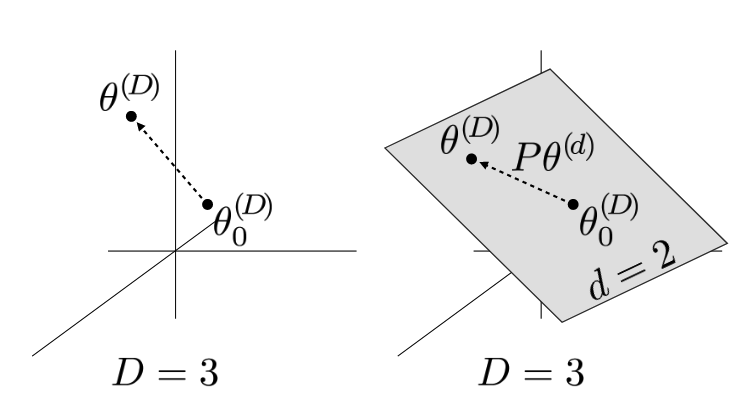
파라미터 전체의 차원이 3인 경우 (좌), Intrinsic Dimension이 2인 경우 최적화 경로 (우)
- 기본 아이디어: 모델의 전체 파라미터 공간
대신 더 작은 차원의 무작위 부분공간 에서 훈련 (일반적으로 ) - 수학적 표현:
: 원래 모델의 차원 파라미터 : 랜덤 초기화된 고정 파라미터 : 크기의 랜덤 투영 행렬 : 최적화되는 차원 파라미터
- 훈련 과정:
와 는 랜덤하게 생성 후 고정 에 대한 그래디언트를 계산하고 이를 최적화 를 점진적으로 증가시키며 성능 변화 관찰
- Intrinsic Dimension 정의:
: 기준선 성능의 90% 이상을 달성하는 최소 부분공간 차원 : 기준선 성능과 통계적으로 구분할 수 없는 성능을 달성하는 최소 차원 는 학습 과정에서 규제 사용 등에 따라 너무 다양하게 변화해 를 기준으로 실험
효율적인 투영 방법
- 대규모 문제에서 Random Subspace Training의 계산 효율성을 위한 세 가지 방법 제시:
- 밀집(Dense) 행렬: 간단하지만
시간 및 공간 복잡도 - 희소(Sparse) 행렬:
시간 및 공간 복잡도 - Fastfood 변환:
시간 및 공간 복잡도로 가장 효율적
- 밀집(Dense) 행렬: 간단하지만
Method 검증
MNIST 실험 결과
- FC 네트워크 실험: 784-200-200-10 구조(총 199,210개 파라미터)에서 훈련
측정 (전체 파라미터의 0.4%) → 네트워크가 매우 압축 가능함을 입증 - 260배 압축(793kB → 3.2kB) 가능 → 한정된 저장 공간/대역폭 환경에 유용
- LeNet 실험: 합성곱 네트워크(총 44,426개 파라미터)에서 훈련
측정 → FC 네트워크보다 더 효율적인 파라미터 활용 확인 - 약 150배 압축 가능 → 합성곱 구조의 우수성 입증
- 네트워크 크기 실험: 다양한 깊이(1~5층)와 너비(50~400 노드)의 FC 네트워크
- 파라미터 수(
) 24.1배 증가 시 은 단 1.33배만 증가 → 추가 파라미터는 주로 중복성만 증가시킴 - 동일 데이터셋에 대해 Intrinsic Dimension이 모델 구조와 거의 무관 → 문제 자체의 복잡성을 반영
- 파라미터 수(
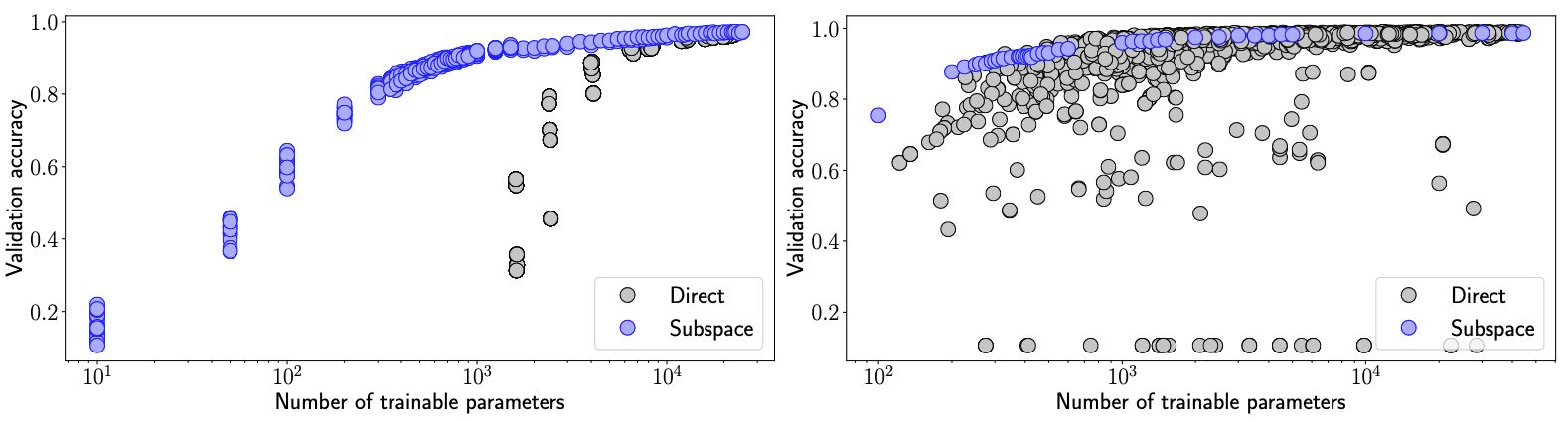
- 파라미터 효율성 비교: Random Subspace vs 직접 훈련된 작은 네트워크
- 대부분의 성능 수준에서 Subspace 방식이 더 우수 → Random Subspace 훈련의 파라미터 효율성 입증
- FC 네트워크에서 격차가 더 뚜렷 → 네트워크 구조의 비효율성 정량화 가능
- 이미지 셔플링 실험: 픽셀 순서를 무작위로 섞은 MNIST
- FC:
유지(750) → 입력 순서에 불변한 특성 확인 - LeNet:
증가(290 → 1,400) → 합성곱의 지역 구조 가정이 깨질 때 효율성 저하 - 합성곱 네트워크의 효율성이 지역적 구조 활용에서 기인함을 증명
- FC:
- 레이블 셔플링 실험: 무작위 레이블을 가진 MNIST
(약 3.8 파라미터/레이블) → 메모리제이션에 매우 높은 차원 필요 - 데이터 크기 감소 시 필요한 파라미터/레이블 증가 → 대규모 데이터셋에서 메모리제이션 효율성 증가
CIFAR-10 실험 결과
- FC 네트워크 vs LeNet vs ResNet 비교
- FC:
/ LeNet: / ResNet: - MNIST보다 높은 차원 필요 → 문제의 복잡성 증가 반영
- 구조가 발전할수록(FC→LeNet→ResNet)
감소 → 효율적인 구조의 정량적 비교 가능
- FC:
강화학습(RL) 실험 결과
- 다양한 난이도의 환경 비교
- Inverted Pendulum:
→ 매우 단순한 문제임을 정량적으로 확인 - Humanoid:
→ MNIST FC와 비슷한 난이도 - Atari Pong:
→ CIFAR-10과 비슷한 난이도 - 서로 다른 유형의 학습 문제 간 난이도를 객관적으로 비교 가능
- Inverted Pendulum: