Ablating Concepts in Text-to-Image Diffusion Models
Large-scale text-to-image diffusion models can generate high-fidelity images with powerful compositional ability. However, these models are typically trained on an enormous amount of Internet data, often containing copyrighted material, licensed images, and personal photos. Furthermore, they have been found to replicate the style of various living artists or memorize exact training samples. How can we remove such copyrighted concepts or images without retraining the model from scratch? To achieve this goal, we propose an efficient method of ablating concepts in the pretrained model, i.e., preventing the generation of a target concept. Our algorithm learns to match the image distribution for a target style, instance, or text prompt we wish to ablate to the distribution corresponding to an anchor concept. This prevents the model from generating target concepts given its text condition. Extensive experiments show that our method can successfully prevent the generation of the ablated concept while preserving closely related concepts in the model.
Problem:: 대규모 텍스트-이미지 모델이 저작권 있는 작품 생성 문제 / 특정 예술가 스타일 모방 및 개인 사진 재생성 문제 / 모델 재학습은 계산 비용이 매우 높음 / 추론 시간 필터링은 쉽게 우회 가능
Solution:: 목표 개념의 이미지 분포를 기준 개념 분포와 KL divergence 최소화 통해 일치시키는 방법 제안 / Model-based와 Noise-based 두 가지 접근법 개발
Novelty:: 주변 개념 보존하며 목표 개념만 선택적 제거 / Cross-Attention, Embedding, Full Weights 등 다양한 파라미터 업데이트 방식 비교
Note:: 개념당 약 5분 소요 / Cross-Attention 학습시 오타에 강건한 점
Summary
Motivation
- 대규모 텍스트-이미지 확산 모델들은 인터넷에서 수집된 방대한 데이터로 학습되어 컴포지션 능력과 고품질 이미지 생성 능력을 갖추게 됨
- 그러나 이런 모델들이 저작권이 있는 Material, 특정 예술가의 스타일, 개인 사진 등을 그대로 생성하는 문제 발생
- 모든 창작자는 자신이 만든 이미지가 대규모 모델에 사용되는 것을 언제든 거부할 권리가 있어야 함
- 기존 방법의 한계:
- 처음부터 모델 재학습: 계산 비용이 매우 높음(SD 2.0 경우 150,000 GPU-시간 소요)
- 추론 시간 필터링: 사용자가 모델 가중치에 접근 가능한 환경에서 쉽게 우회 가능
- 이러한 문제를 해결하기 위해 사전 학습된 모델에서 특정 개념을 효율적으로 제거하는 방법이 필요함
Method
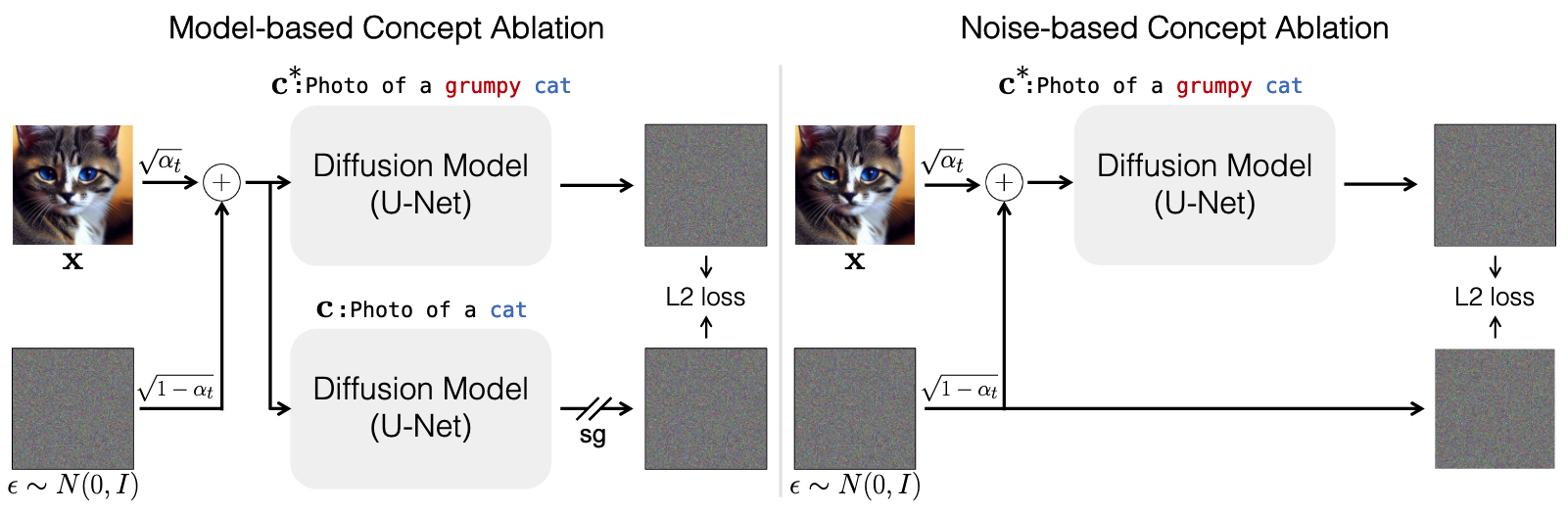
- 제안 방법: 목표 개념의 이미지 분포를 기준 개념의 분포와 일치시키는 효율적인 Fine-tuning 접근법
- 예: "Van Gogh painting" → "paintings", "Grumpy Cat" → "Cat" 등으로 매핑
- 목표 개념에 대한 텍스트 프롬프트가 주어졌을 때 모델이 기준 개념의 이미지를 생성하도록 학습
- 수학적 정의:
- 목표 개념
에 대한 모델의 조건부 분포 를 기준 개념 의 분포 와 일치시킴 - Kullback-Leibler divergence 최소화:
- 목표 개념
- 두 가지 핵심 방법론:
- Model-based concept ablation:
- 목표 분포를 사전 훈련된 모델의 기준 개념 분포로 정의
- 학습 목표:
- Noise-based concept ablation:
- <목표 개념 텍스트, 기준 개념 이미지> 쌍으로 데이터 재정의
- 학습 목표:
- Model-based concept ablation:
- 파라미터 업데이트 방식:
- Cross-Attention: 키와 값 투영 행렬만 Fine-tuning
- Embedding: 텍스트 트랜스포머의 임베딩만 Fine-tuning
- Full Weights: U-Net의 모든 파라미터 Fine-tuning
Method 검증
- 베이스라인(손실 최대화 방법)
- 수학적 정의:
- 목표 개념에 대한 확산 모델 학습 손실(
)을 최대화하여 의도적으로 성능 저하
- 수학적 정의:
객체 인스턴스 제거
- 실험 내용: Grumpy Cat → Cat, Snoopy → Dog, Nemo → Fish, R2D2 → Robot 등 특정 캐릭터 제거
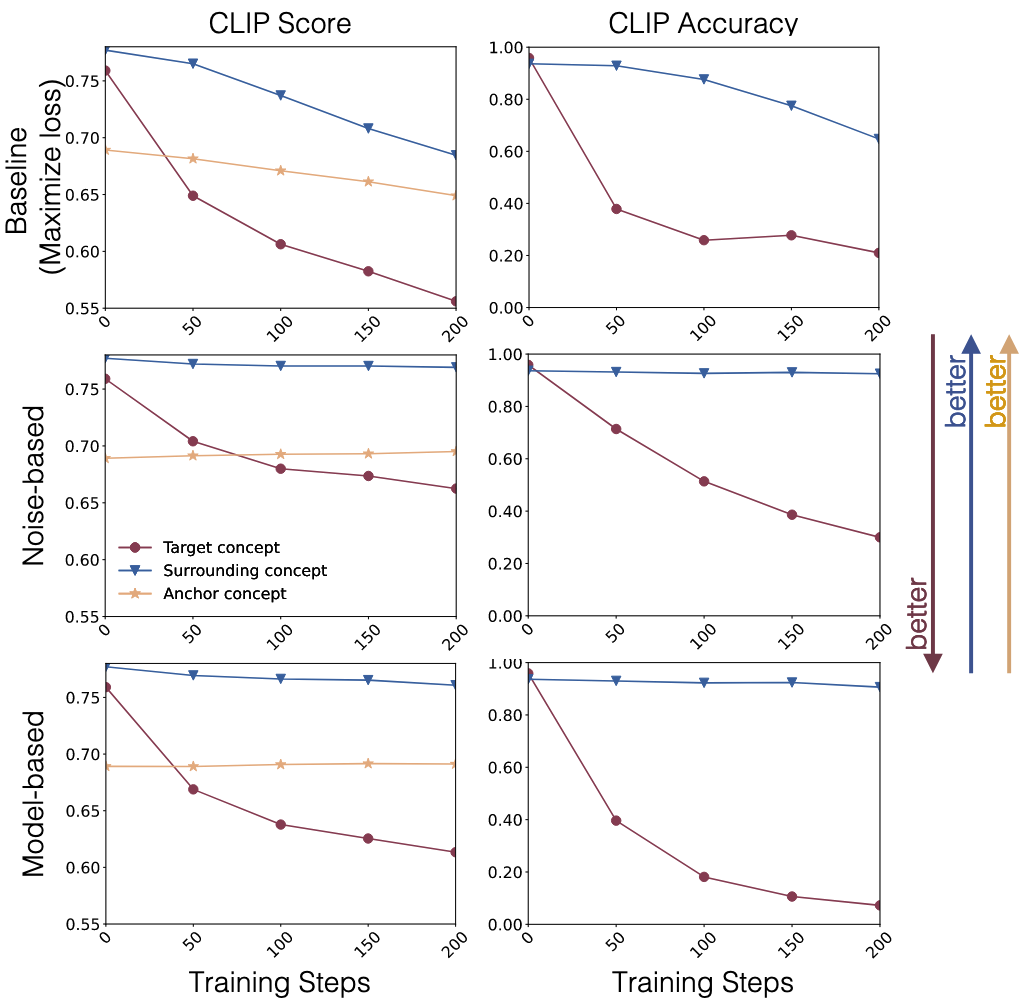
- Model-based 방법이 Noise-based 방법보다 더 빠르게 수렴하고 주변 개념 보존 성능 우수 (Figure 3)
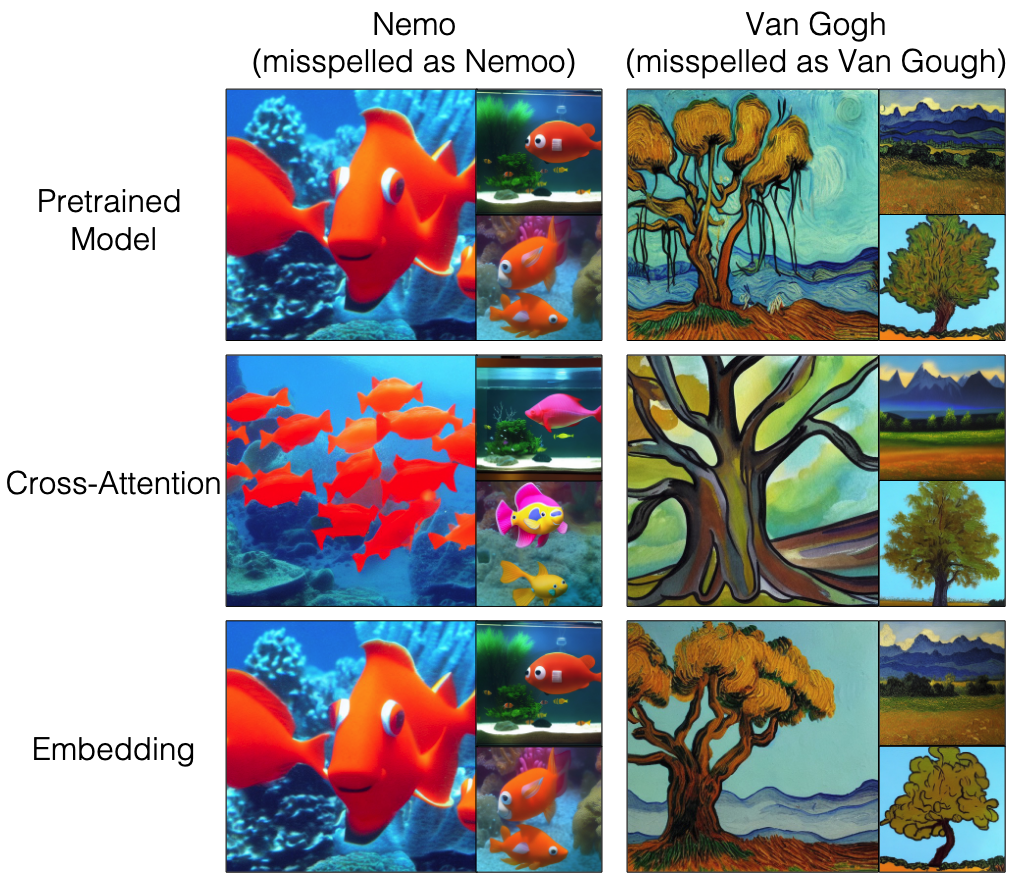
- Cross-Attention 파라미터만 Fine-tuning할 경우 철자 오류에 더 강건함을 확인
- 다양한 파라미터 업데이트 방식(Cross-Attention, Embedding, Full Weights) 모두 목표 개념 제거에 효과적
- 베이스라인(손실 최대화 방법)과 비교했을 때 주변 개념(BB8 등)을 더 잘 보존 (Figure 7)
- Model-based 방법이 Noise-based 방법보다 더 빠르게 수렴하고 주변 개념 보존 성능 우수 (Figure 3)
예술 스타일 제거
- 실험 내용: Van Gogh, Monet, Salvador Dali, Greg Rutkowski 스타일 제거
- 제안 방법은 특정 스타일을 효과적으로 제거하면서도 콘텐츠는 유지
- Cross-Attention, Embedding, Full Weights 모두 스타일 제거에 효과적
- Embedding Fine-tuning이 초기에 더 빠르게 수렴하나 스타일 간섭도 더 많이 발생
기억된 이미지 제거
- 실험 내용: 모델이 학습 데이터에서 암기한 특정 이미지 제거

- 기존에는 특정 프롬프트에 항상 동일한 이미지 생성되던 문제 해결
- 기억된 이미지와의 유사도가 60.1%에서 0.3%로 크게 감소
- Full Weights Fine-tuning이 가장 좋은 성능 보임
- 8개의 기억된 이미지 케이스 모두에서 효과적인 제거 확인
추가 분석 실험
- 다중 개념 동시 제거: 여러 인스턴스 또는 스타일을 하나의 모델에서 제거 가능 (Figure 10)
- 정량적 결과: 목표 개념의 CLIP Accuracy는 크게 감소하고 주변 개념은 유지됨
- 학습 단계가 증가함에 따라 제거 효과도 향상됨
- 기준 개념 선택의 영향:
- Grumpy Cat을 "British Shorthair Cat"이나 "Felidae"로 변환하는 다양한 기준 개념으로도 효과적인 제거 가능 (Figure 11)
- 역방향 KL 발산 실험:
- 정방향 KL과 달리 목표 개념 이미지(
)에 대한 기대값으로 손실 계산 → 각 프롬프트를 이용해 추정한 노이즈가 동일하게 한다는 것으로 원 수식과 동일함 - 역방향 KL 발산 목표 수식:
- 스타일 제거에서는 약간 더 나은 성능, 인스턴스 제거에서는 약간 더 낮은 성능 (Figure 12)
- 특히 "Starry Night"와 같은 특정 유명 작품 제거에 더 효과적 (Figure 13)
- 정방향 KL과 달리 목표 개념 이미지(
Limitation
- 일부 복잡한 개념(church, parachute 등)은 완전히 제거되지 않고 핵심 특징(십자가 등)만 제거됨
- 강한 개념 제거 설정은 관련 없는 스타일이나 객체에도 간섭 발생
- 특정 유명 작품("starry night painting" 등)은 스타일 제거해도 생성 가능한 경우 있음
- 모델 가중치에 대한 완전한 접근 권한이 있다면 제거된 개념 다시 추가 가능