Why Warmup the Learning Rate? Underlying Mechanisms and Improvements
It is common in deep learning to warm up the learning rate
Problem:: Standard Warmup 방식(
Solution:: Warmup 메커니즘을 (Pre-Conditioned) Sharpness와 Catapult 관점에서 상세히 분석 / 초기 Instability Threshold(
Novelty:: Warmup의 주된 이점이 (Pre-Conditioned) Sharpness 감소를 통해 더 높은
Note:: 학습에서 모호했던 Warmup의 역할을 어느정도 이해하는데 도움이 된 논문
Summary
Motivation
- Warmup의 필요성 제기: 딥러닝 학습 시 Learning Rate(
) Warmup은 흔히 사용되며, 초기 Learning Rate를 0에서 목표치( )까지 점진적으로 증가시키는 방식이 일반적임 - Warmup의 핵심 관찰: Warmup을 사용하면 모델이 더 큰
에서 안정적으로 학습할 수 있게 되며, 이는 종종 최종 모델 성능 향상 및 Hyperparameter Tuning의 안정성 증가로 이어짐
1행: Large Initialization, 2행: Small Initialization, 2열의 점선은
의 경계 선 → 일반적으로 의 역수
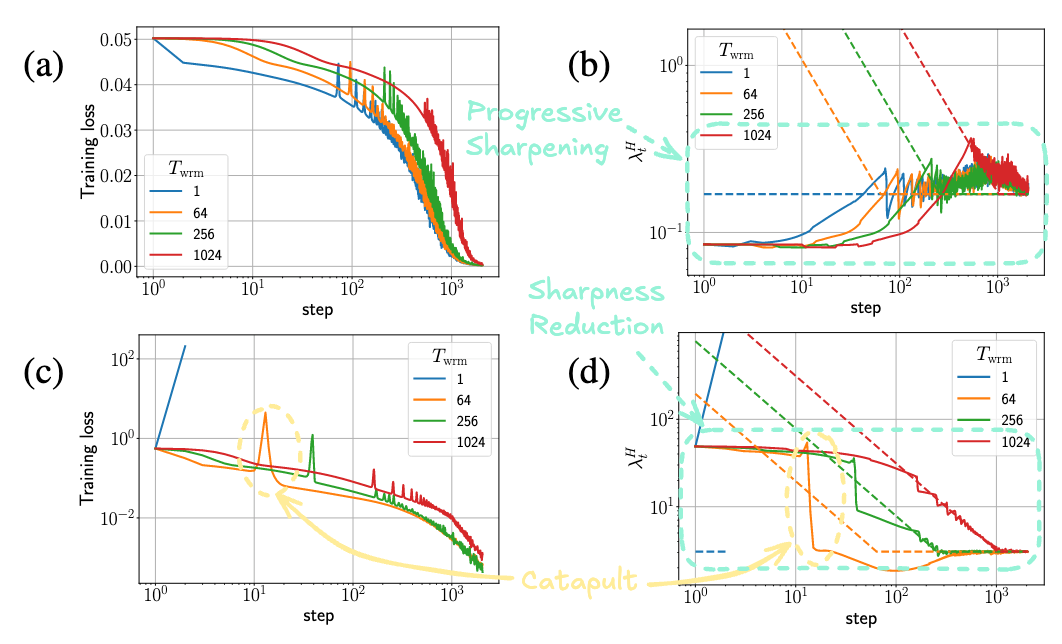
- 핵심 메커니즘: Sharpness 조절과 Catapult: Warmup으로 Loss가 커지는건 Large LR을 견디는 Flat Region으로의 이동
- 이 현상의 근원은 Learning Rate가 특정 임계값(
)을 초과할 때 발생하는 학습 불안정성(Instability), 즉 "Catapult" 와 관련이 깊음 가 되면 Loss가 일시적으로 증가하고, 이는 Loss Landscape의 Sharpness( )를 급격히 감소시키는 효과를 가져옴 - Sharpness가 감소하면
가 다시 높아져( ) 안정적인 학습 상태( )로 복귀하며, 결과적으로 모델은 더 낮은 Sharpness를 갖는, 즉 더 Flat한 영역으로 이동하게 됨 - Warmup은 이 Catapult 현상을 점진적이고 통제된 방식으로 유도하여, 모델이 급격한 발산 없이 더 높은
를 견딜 수 있도록 Sharpness를 점진적으로 낮추는 역할을 함
- 이 현상의 근원은 Learning Rate가 특정 임계값(
- Optimizer 및 Initialization 별 Warmup Dynamics
- SGD: Initialization에 따라 Sharpness가 자연적으로 증가하는 경우(Progressive Sharpening)와 감소하는 경우(Sharpness Reduction)가 있음
- Small Initialization: Progressive Sharpening 때문에 알아서 Sharpness가 올라가므로 Warmup 효과가 적음
- 초기 네트워크 출력이 작으며, Maximal Update Parameterization (
) 또는 적절한 Normalization Layer (e.g., 표준 Transformer)를 사용하는 경우 해당됨 - 일반적으로 Flat한 영역에서 시작하며(
낮음), Progressive Sharpening 경향을 보임 - 이미 Flat하게 시작하므로 Warmup의 효과가 상대적으로 적을 수 있음
- 초기 네트워크 출력이 작으며, Maximal Update Parameterization (
- Large Initialization: Sharpness Reduction 때문에 Warmup이 있어야 학습 효과가 좋음
- Standard Parameterization (SP) 를 사용하는 FCN, CNN, ResNet 등 또는 특정 Layer (e.g., 마지막 LayerNorm)가 제거된 Transformer 등에서 나타남
- 일반적으로 Sharp한 영역에서 시작하며(
높음), 초기 단계에서 Sharpness Reduction 경향을 보임 - 높은 초기 Sharpness를 낮추기 위해 Warmup의 효과가 더 크게 나타남
- Warmup은 이러한 자연스러운 경향과 상호작용하며 Catapult를 유발함.
이 길수록 Catapult의 강도가 약해짐 → Warmup 기간을 길게 해봐야 Catapult 발생 시점만 늦춰지므로 효과적이지 않을 수 있음
- Small Initialization: Progressive Sharpening 때문에 알아서 Sharpness가 올라가므로 Warmup 효과가 적음
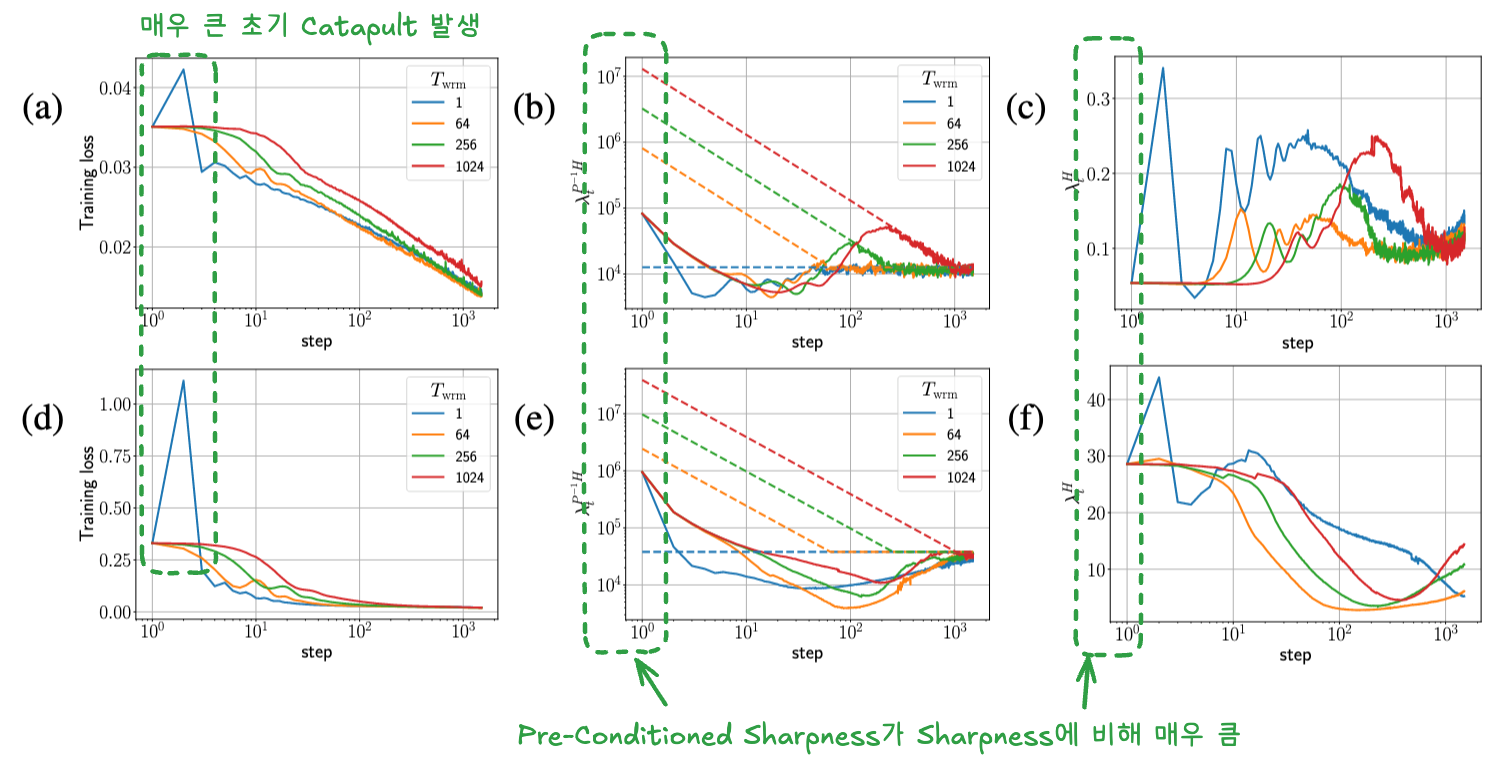
- Adam: Adam의 안정성은 Sharpness가 아닌 Pre-Conditioned Sharpness (
) 에 의해 결정됨 → Initialization이랑 무관하게 Pre-Conditioned Sharpness가 너무 높아서 Warmup으로 완화해야 함 - Pre-Conditioned Sharpness는 Adaptive Optimizer가 학습 과정에서 사용하는 Gradient의 통계량인
를 이용해 변형된 Loss Landscape의 Sharpness 는 초기값( )이 매우 높은 경향이 있어, Warmup 없이 높은 를 사용하면 매우 큰 초기 Catapult가 발생하여 Training Failure로 이어질 수 있음 - Warmup은
가 자연스럽게 감소할 시간을 벌어주어 이러한 초기 불안정성을 완화함
- Pre-Conditioned Sharpness는 Adaptive Optimizer가 학습 과정에서 사용하는 Gradient의 통계량인
- SGD: Initialization에 따라 Sharpness가 자연적으로 증가하는 경우(Progressive Sharpening)와 감소하는 경우(Sharpness Reduction)가 있음
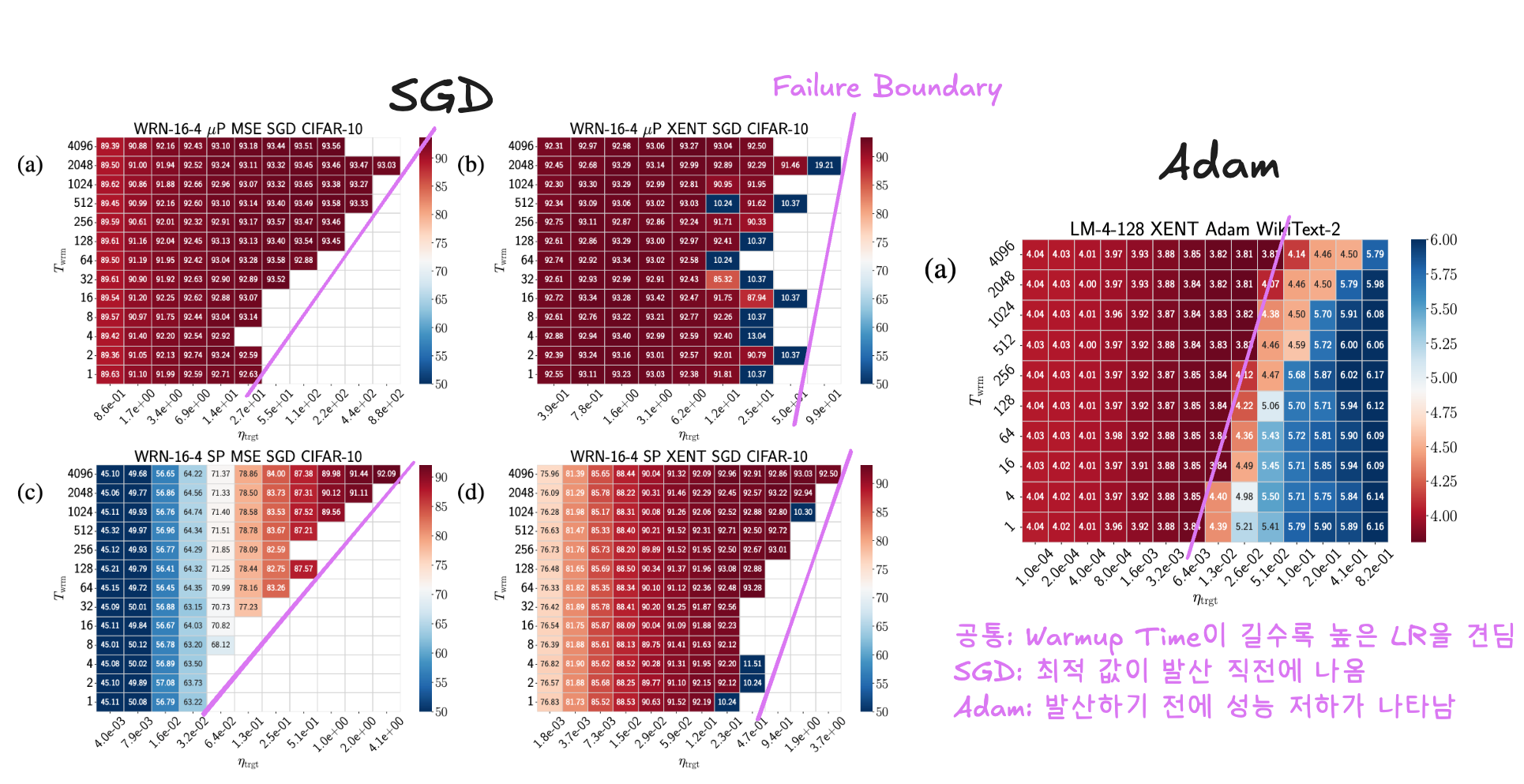
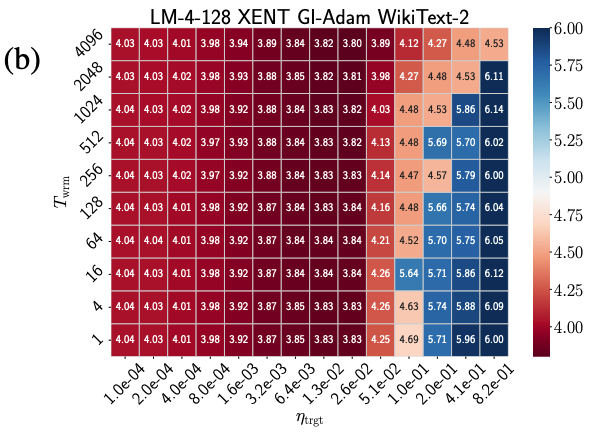
- 평면에서 Test 성능을 보여줌
- Warmup 효과 시각화 (Phase Diagrams):
이 길수록 학습 가능한 의 상한선(Divergence/Failure Boundary)이 높아짐을 명확히 보여줌 - 최적 성능은 주로 높은
값에서 달성되며, Warmup은 이러한 높은 값에서의 학습을 가능하게 하거나 안정화하는 핵심 역할을 함 - 특히 Adam은 큰 Catapult로 인한 성능 저하가 Failure Boundary 이전에 나타나므로, 안정적인 학습을 위해 Warmup의 중요성이 더 큼
Method
- Initial Learning Rate (
) 선택 개선 → 쓸모없는 단게 없이 바로 Failure Boundary로 이동해서 더 빠르게 Flat Region으로 이동 - Method: 초기 Instability Threshold (
)를 추정하여 로 설정함. 이는 으로 시작하여 에 도달하기까지의 비효율적인 구간을 줄이기 위함임 추정 과정: 근처가 Failure Boundary이므로 손실 함수 비교로 찾음 - 1단계 (Exponential Search): 작은 초기 추측값
에서 시작하여, 를 배씩 증가시키면서 각 값으로 딱 한 스텝만 진행했을 때의 Loss 을 초기 Loss 와 비교 → 가 되는 첫 를 찾으면, 이 값을 로, 이전 값을 로 하여 를 포함하는 초기 구간 를 설정 - 2단계 (Binary Search): Exponential Search로 찾은 구간
내에서 를 더 정밀하게 찾음. 구간의 중간값 로 한 스텝 진행 후 Loss 을 평가함. 이면 로, 이면 로 구간을 좁혀나감. 이 과정을 이 보다 약간 큰 정도( )가 될 때까지 반복하여 최종 (실제로는 )를 결정
- 1단계 (Exponential Search): 작은 초기 추측값
- Method: 초기 Instability Threshold (
- GI-Adam (Gradient Initialized Adam) → 높은 Pre-Condition Sharpness 완화 및 자동 Warmup 효과 주입
- Standard Adam의 Second Moment Update:
. 일반적으로 으로 초기화되며, 초기 단계의 Bias를 보정하기 위해 를 사용함 - 문제점:
초기화와 Bias Correction으로 인해 초기 단계에서 가 실제 Gradient 제곱의 기댓값보다 작아지고, 결과적으로 Adam의 Pre-Conditioner( )가 불안정해져 초기 Pre-Conditioned Sharpness ( )가 비정상적으로 높아지는 문제 발생 가능 - GI-Adam의 제안: Second Moment를
(첫 번째 스텝의 Gradient 제곱)으로 초기화함 - 효과:
으로 초기화하면, 의 기댓값 는 초기부터 Gradient 제곱의 실제 분산( )에 가깝게 유지되어 Bias Correction( )이 이론적으로 불필요해짐. 그럼에도 Standard Adam처럼 Bias Correction을 적용하면, 가 되어 실제 분산보다 작아지는 효과가 발생함. 이는 Adam 업데이트 식 에서 항을 키우는 대신, Learning Rate 에 를 곱하는 것과 유사하게 작용하여, 자동으로 점진적인 Warmup ( )을 수행하는 효과를 줌. 결과적으로 초기 Pre-Conditioned Sharpness가 낮아져 안정성이 향상됨
- Standard Adam의 Second Moment Update:
- Persistent Catapult Warmup (Parameter-Free 전략 제안) → Warmup Step 같은 귀찮은 파라미터 없는 Warmup 제안
- Method: 반복적으로 Catapult를 유도하여 점진적으로 Sharpness(또는 Pre-Conditioned Sharpness)를 줄여나가는 방식임
- 현재 상태에서
를 추정하고( 계산), 로 Learning Rate를 설정하여 Catapult를 유도함 - Loss가 Catapult 이전 수준(
) 이하로 떨어지면( ), 다시 추정 및 Catapult 유도 과정을 도달 시까지 반복함
Method 검증
- Initial Learning Rate 선택 개선 효과:
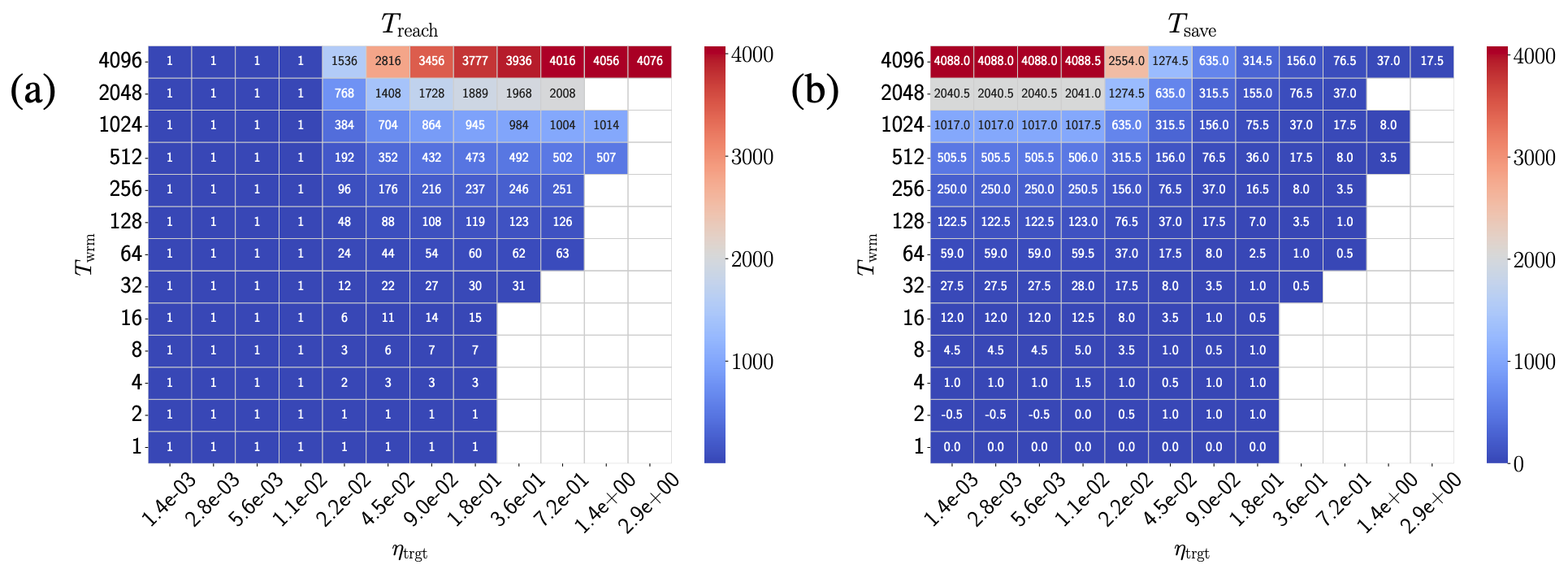
로 설정 시, Target Learning Rate( )에 도달하는 데 필요한 Step 수( )가 크게 감소함 (1열) - 결과적으로 Warmup에 소요되는 유효 Step 수(
)를 크게 절약할 수 있음 (2열)
- GI-Adam 효과
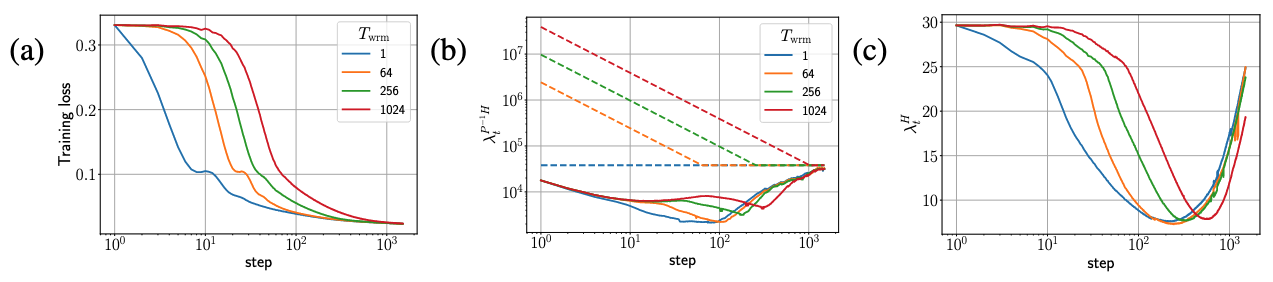
- GI-Adam은 Standard Adam 대비 초기 Pre-Conditioned Sharpness (
)를 약 배 감소시켜 초기 불안정성을 현저히 줄임 → 거의
- Standard Adam과 비교하여 일관적으로 성능이 향상되었으며, Training Failure Boundary가 더 높은
값으로 이동하여 학습 안정성이 개선됨
- GI-Adam은 Standard Adam 대비 초기 Pre-Conditioned Sharpness (
- Persistent Catapult Warmup 효과:
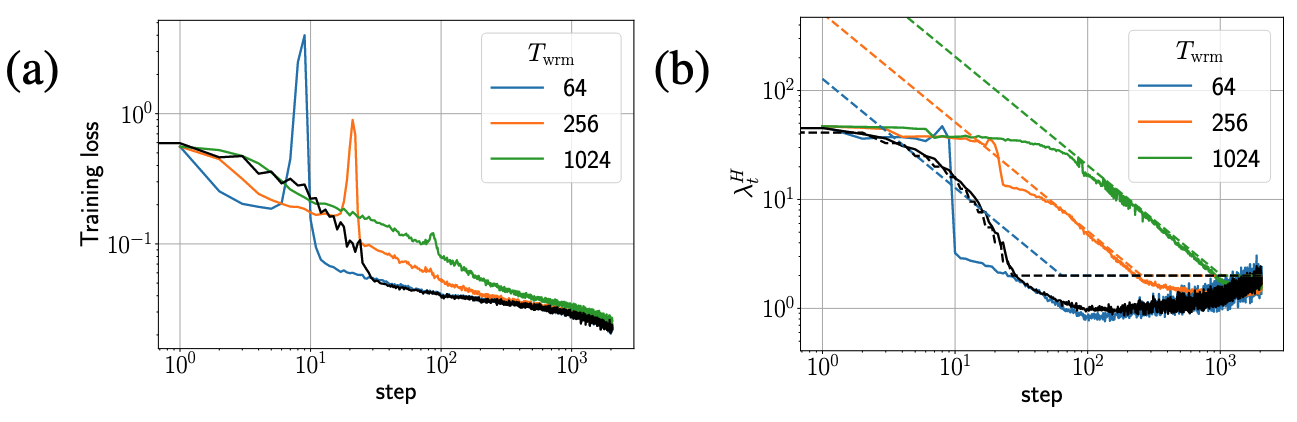
- 제안된 전략은 Warmup Duration(
)을 미리 지정할 필요 없이, 정보를 활용하여 동적으로 Learning Rate를 조절하며 안정적으로 높은 에 도달함
- 제안된 전략은 Warmup Duration(