Steering CLIP's vision transformer with sparse autoencoders
While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.
Problem:: Vision Transformer의 내부 작동 방식에 대한 이해 부족 / Language Model에서 사용된 해석 가능성 기법(SAE)이 Vision 분야에서는 아직 초기 단계
Solution:: CLIP-ViT의 Activation에 Sparse Autoencoders (SAEs)를 훈련하여 해석 가능한 Feature로 분해 / Feature 조작의 영향력을 정량화하는 'Steerability' 지표 도입 / 식별된 Spurious Feature를 억제하여 Disentanglement Task 성능 향상
Novelty:: CLIP-ViT Feature에 대한 최초의 체계적, 정량적 Steerability 분석 / Vision과 Language 모델의 근본적인 Sparsity 패턴 차이 규명 / SAE Feature Steering을 통해 Typographic Attack 방어에서 SOTA 성능 달성
Note:: 후반부 Layer의 Feature 중 약 10-15%만이 Steerable함 / Spurious Feature의 종류에 따라 최적의 Disentanglement Layer가 다름 (배경은 초기 Layer, 머리색 등은 후기 Layer)
Summary
Motivation
- 현재 Vision Transformer의 한계: 뛰어난 성능에도 불구하고 내부 메커니즘에 대한 이해 부족
- Language 모델과의 차이: SAE가 Language 모델의 해석가능성 향상에 기여했으나, Vision 분야에서는 탐구가 제한적
- Multimodal System의 중요성: Vision Transformer가 대규모 Multimodal System의 구성 요소로 사용되면서 내부 표현 이해의 중요성 증대
- 안전성과 신뢰성: 모델의 행동을 체계적으로 이해하고 제어할 수 있는 도구의 필요성
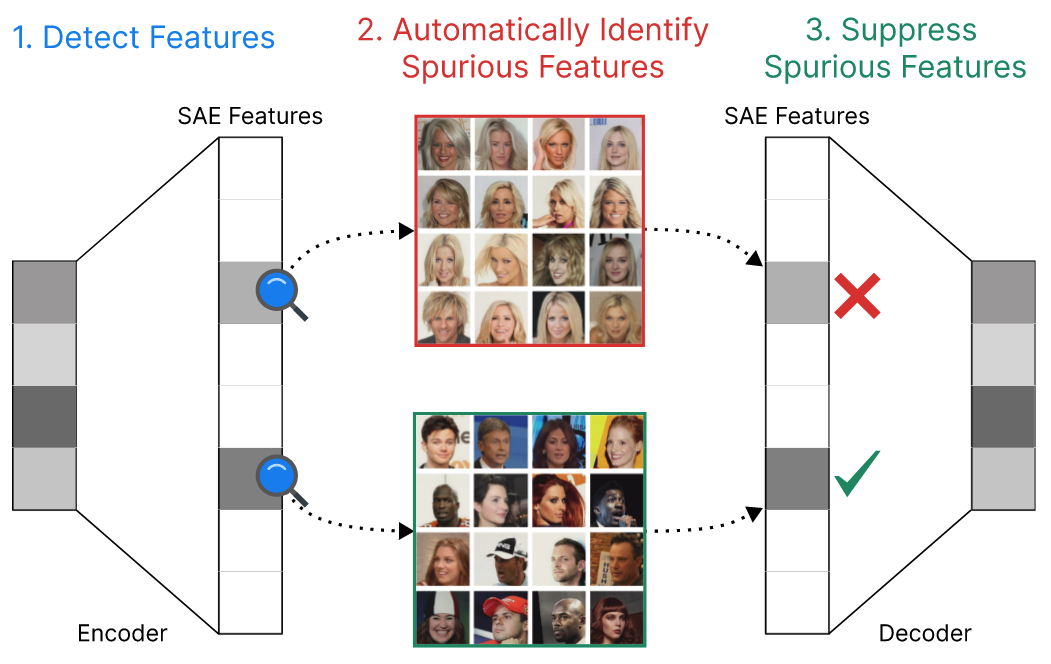
CelebA 데이터셋에서 Blondeness Feature 억제를 통한 Gender Classification 개선 방법의 전체적인 개요 제시
Method
- Training CLIP Vision SAEs
- SAE Decomposition 수식
: 재구성된 입력, : j번째 Feature의 Sparse Activation, : 정규화된 Feature Vector, : Bias Term, : Reconstruction Error
- CLIP-ViT-B-32 모델의 각 Layer의 Residual Stream Activation으로부터 두 종류의 SAEs를 훈련 → 각 Layer의 Residual Path마다 SAE를 학습
- Vanilla SAEs: ReLU Activation Function과 L1 Regularization을 사용하여 Sparsity를 유도
- Top-K SAEs: Top-K Activation Function을 사용하여 Sparsity를 고정된 하이퍼파라미터 k로 정의
- SAEs는 General-Purpose (ImageNet-1K) 설정과 Task-Specific (CelebA, Waterbirds) 설정 모두에서 훈련됨
- SAE Decomposition 수식
- CLIP SAE Feature Steering
- Steerability Metrics 도입
- SAE Feature 조작이 모델 출력에 미치는 영향을 측정하기 위해 Steerability (
)라는 지표를 제안 - Feature-level Steerability:
: SAE Feature에 조작을 가했을 때 출력 분포에 미치는 영향에 대한 지표 : 이미지 개수 : 이 이미지가 어휘 목록 속 특정 단어(개념)일 확률이 얼마인가 - 주어진 이미지
를 CLIP의 Vision Encoder에 통과시켜 이미지 임베딩 ( )을 추출 - 미리 정의된 어휘(
) 목록을 CLIP의 Text Encoder로 인코딩하여 텍스트 임베딩 라이브러리( )를 생성 과 텍스트 내 모든 임베딩 간의 내적(Dot Product) 계산으로 유사도 점수 벡터 생성 - 계산된 유사도 점수 벡터에 소프트맥스(Softmax) 적용하여 최종 확률 분포
획득
- 주어진 이미지
: Steering (특정 Feature의 Activation 값을 조작) 후 확률 - 특정 Feature를 고정된 값으로 바꾼 뒤의 분포
- 연산량의 제한 때문에 Layer 11의 49152의 25%만 조작하여 수치 측정
- Layer-level Metrics: Layer 단위의 Steerability를 평가하기 위한 추가적인 지표
- 평균 Steerability:
- Threshold 기반 분류
- Steerable Features 비율: Steerable한 Feature의 비율
- Concept Coverage: 특정 Concept에 대해 의미 있는 확률 증가를 유도하는 Feature의 수
: Threshold
- Steerable Features 비율: Steerable한 Feature의 비율
- 평균 Steerability:
- SAE Feature 조작이 모델 출력에 미치는 영향을 측정하기 위해 Steerability (
- Steerability Metrics 도입
- Suppressing Spurious Correlations
- Spurious Correlation을 억제하기 위해 특정 Feature들을 식별하고, 해당 Feature들의 Activation을 0으로 만드는 Zero-Ablation 기법을 적용
- Spurious Correlation이 존재하는 데이터셋 (
)에서 없는 데이터셋 ( )보다 평균적으로 더 높게 활성화되는 SAE Feature들을 식별하여 Target Feature Set 을 구성 - 추론(Inference) 과정에서 식별된
에 속하는 Feature들의 Activation을 0으로 만들어 Spurious Correlation의 영향을 억제
Method 검증
- Sparsity Pattern 분석
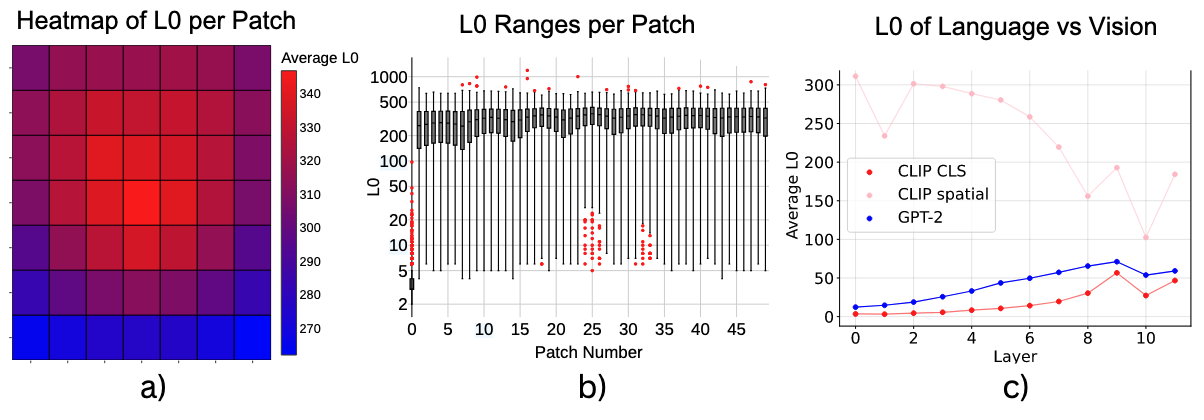
- (a) Spatial Token에서 얻은 SAE의 활성화된 Feature 수(L0)를 시각화 → 중앙에 위치한 Patch에서 L0 값이 더 높게 측정 → 정보 밀도가 이미지 중앙에 집중되어 있음을 의미
- (c) CLIP의 Spatial Token에 대한 L0 값(300-700)이 GPT-2 Token에 대한 L0 값(20-50)보다 3-14배 높게 나타남 → Vision과 Language 모델이 정보를 처리하는 방식에 근본적인 차이가 있음
- (c) CLS Token의 패턴은 언어 모델 (GPT-2)와 더 유사 → Spatial: Local, CLS: 압축을 담당
- Steerability 분석
- SAE Feature-Level Steering과 Base Model의 Neuron-Level Steering을 비교한 결과, Deeper Layer에서 약 10-15%의 Feature가 Steerable 하다는 것을 정량적으로 확인
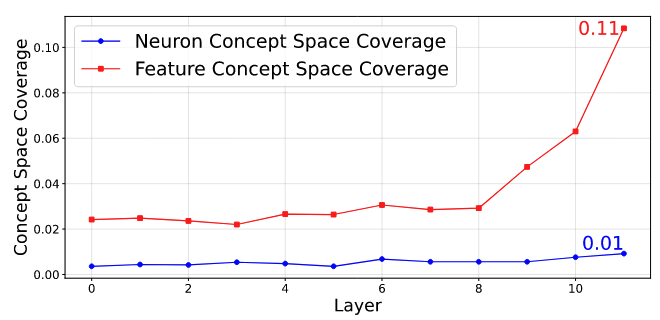
- Feature Steering이 Neuron Steering보다 Concept에 접근할 수 있는 범위가 훨씬 넓다는 것을 보여줌. 특히 Layer 11에서는 10배 이상 우수한 Concept Space Coverage를 달성하여, SAE가 훨씬 더 정밀하고 광범위한 제어를 가능하게 함을 보여줌
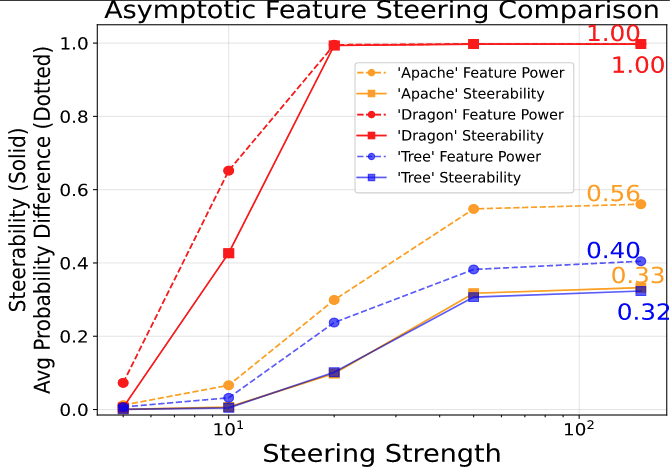
- 'Dragon' Feature처럼 특정 개념으로 완벽하게 Steering 되는 Feature가 존재함을 시각적으로 증명함
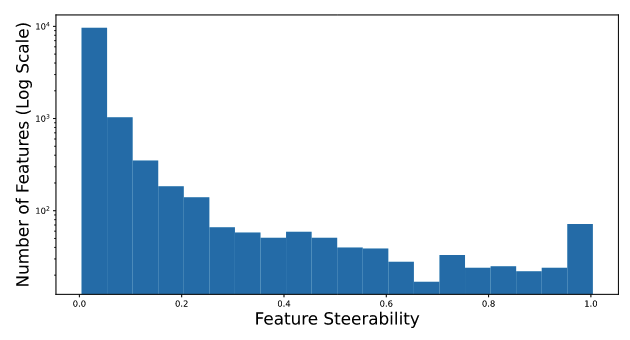
- Layer 11의 Feature 중 약 11%가 유의미한 Steerability를 가지며, 이 중 약 100개는 거의 완벽하게 제어 가능함을 보여줌
- SAE Feature-Level Steering과 Base Model의 Neuron-Level Steering을 비교한 결과, Deeper Layer에서 약 10-15%의 Feature가 Steerable 하다는 것을 정량적으로 확인
- Disentanglement Task: Suppressing Spurious Correlations
- 실험: CelebA 및 Waterbirds 데이터셋에서 Spurious Correlation을 갖는 Feature 억제
- 비교군: Original Model Neuron Ablation, Random SAE Feature Ablation
- 정량적 성능
- CelebA (성별 분류 시 '금발'이라는 Spurious Correlation 억제): Layer 7과 8에서 Worst-Group Accuracy가 77.78%에서 81.11% 로 3.33% 증가
- Waterbirds (새 종류 분류 시 '배경'이라는 Spurious Correlation 억제): Layer 2에서 Worst-Group Accuracy가 22.43%에서 24.61% 로 2.18% 증가
- 통찰

- 위 그림은 특정 선택된 뉴런 및 SAE Feature의 활성화 정도가 가장 높은 이미지들을 나타냄
- Base Model의 Neuron은 다양한 종류의 이미지(Polysemantic)에 반응하는 반면, SAE Feature는 특정 속성(CelebA의 금발, Waterbirds의 배경 등)에만 일관되게 반응(Monosemantic)함. 이로 인해 더 정밀한 제어가 가능했던 것임
- Task에 따라 최적의 Disentanglement Layer가 다름 (넓게 퍼진 배경 Feature는 초기 Layer, 국소적인 머리카락 Feature는 후기 Layer에서 분리하는 것이 효과적)
- 실험: CelebA 및 Waterbirds 데이터셋에서 Spurious Correlation을 갖는 Feature 억제
- Disentanglement Task: Suppressing Typographic Attacks

- 위 그림은 Typographic Attack의 예시로, 이미지에 'Tiger'라는 텍스트를 삽입하는 것만으로 모델의 예측을 오도할 수 있음을 보여줌
- 실험 제목: Typographic Attack에 대한 모델의 Robustness 향상
- 비교군: No Defense, Defense-Prefix (DP, 기존 SOTA), DP + Ours
- 정량적 성능
- 제안된 SAE 기반 방법과 기존 SOTA인 DP를 결합했을 때, 모든 벤치마크에서 최고의 성능을 달성 (예: Disentangling visual and written concepts in clip 논문의 데이터셋에서 SOTA인 DP의 0.83을 0.88로 향상)
- 제안된 방법 단독으로도 PAINT 데이터셋에서 SOTA를 능가 (0.66 → 0.67)
- 통찰
- SAE를 통해 Typographic Attack과 관련된 Feature를 효과적으로 식별하고 억제할 수 있음
- 원본 데이터셋(ImageNet)에 대한 Top-1 Accuracy는 단 0.7%p 하락하면서 방어 성능을 크게 높여, 제안된 방식의 효율성을 입증