DAC-DETR: Divide the Attention Layers and Conquer
This paper reveals a characteristic of DEtection Transformer (DETR) that negatively impacts its training efficacy, i.e., the cross-attention and self-attention layers in DETR decoder have opposing impacts on the object queries (though both impacts are important). Specifically, we observe the cross-attention tends to gather multiple queries around the same object, while the self-attention disperses these queries far away. To improve the training efficacy, we propose a Divide-And-Conquer DETR (DAC-DETR) that separates out the cross-attention to avoid these competing objectives. During training, DAC-DETR employs an auxiliary decoder that focuses on learning the cross-attention layers. The auxiliary decoder, while sharing all the other parameters, has NO self-attention layers and employs one-to-many label assignment to improve the gathering effect. Experiments show that DAC-DETR brings remarkable improvement over popular DETRs. For example, under the 12 epochs training scheme on MS-COCO, DAC-DETR improves Deformable DETR (ResNet50) by +3.4AP and achieves 50.9 (ResNet-50) / 58.1 AP (Swin-Large) based on some popular methods (i.e., DINO and an IoU-related loss). Our code will be made available at https://github.com/huzhengdongcs/DAC-DETR.
Problem:: DETR의 학습 효율성이 너무 느림
Solution:: Self/Cross Attention간의 상충되는 역할로 인한 악영향을 최소화
Novelty:: Self/Cross Attention의 역할을 관찰하고 실험적으로 증명
Note::
Summary
Motivation
-
DETR의 학습 효율성이 낮은 문제를 해결하기 위한 많은 방법들이 연구되어 왔으며, 특히 One-to-One Matching이 비일관적 최적화를 유도한다고 지적함
- 방향1: 초반 비일관적인 매칭으로 인한 불안정성을 해소하기위해 GT를 변형한 Denoising Query를 추가
- 방향2: One-to-Many Matching 도입으로 Positive Query의 개수를 증가시킴
- 방향3: Matching시 Classification과 Detection간의 Misalignment 해소
-
이 논문의 저자들은 디코더의 Self-Attention과 Cross-Attention이 서로 반대되는 역할을 수행하며, 이 상충 작용이 학습 효율성을 낮춤을 발견함
- Self-Attention은 GT를 기준으로 하나의 Object Query만 가깝게 만들고 나머지는 서로 멀어지게 만듦 → gather라 표현 → 중복 객체를 제거하는데 효과적임
- Cross-Attention은 GT를 기준으로 Object Query들을 가까워지게 만듦 → disperse라 표현 → 객체 근처의 특징들에 집중하도록 함
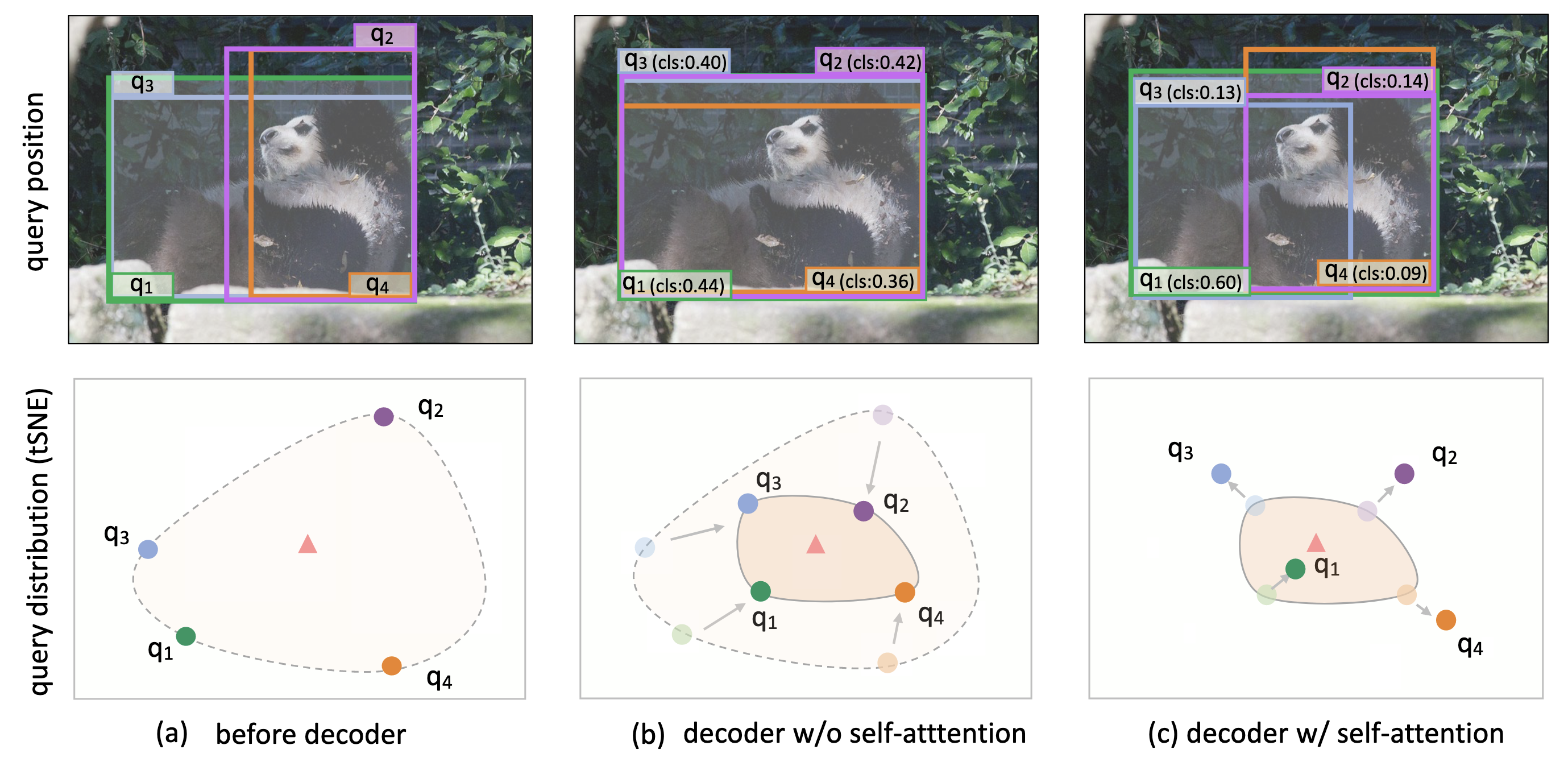
(b)와 (c)는 서로 다른 모델로 연속된 과정이 아님. 삼각형은 객체 중심점
-
각 레이어의 두 작용이 모두 중요함. 따라서, 저자들은 두 과정이 학습 중 상충되는 부분을 최소화하여 이를 개선하고자함.
Method
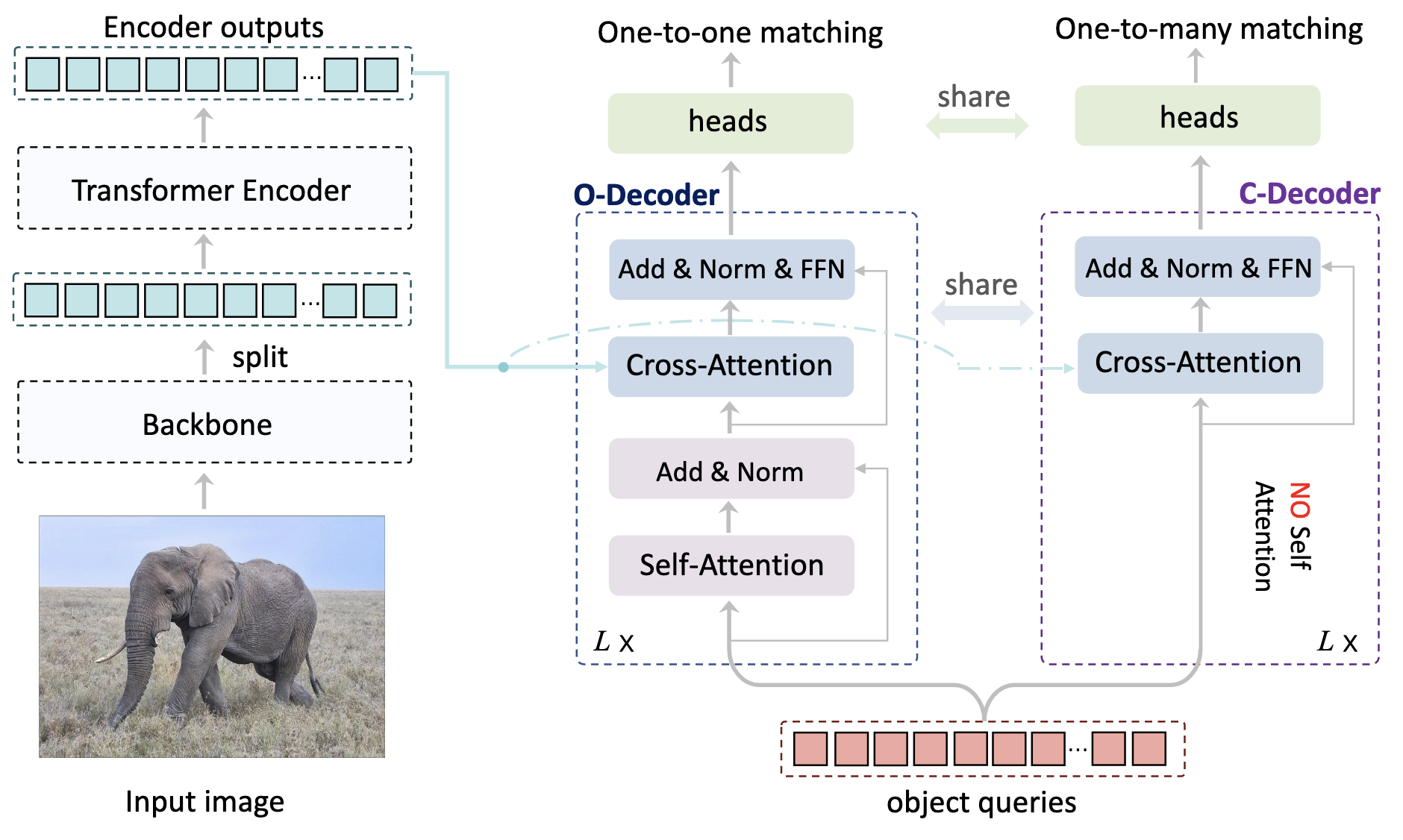
- disperse만 수행하는 C-Decoder를 이용해 gather 과정이 없는 학습을 가능하게 함
- gather는 중복 방지의 역할을 수행하므로, One-to-One Matching을 그대로 사용
- disperse는 중복을 고려하지 않고 Object Query들이 GT와 관련되도록 One-to-Many Matching을 사용
- 추론시에 C-Decoder는 제거하여 추론시 추가 자원 소모는 제거함
One-to-Many Matching
- 하나의 GT가 여러개의 Object Query에 할당되로록 매칭하는 방식으로, Hungarian Matching의 반복적인 적용으로도 구현할 수 있음
- 아래 표의 one-to-many Hungarin이 이 방식
- 저자들은 각 GT마다 Object Query에 대한 Matching Score
을 정의하고, 두 가지 기준으로 이를 수행함 - 특정 Query와의 매칭 스코어가 임계값
보다 커야함 - 특정 Query와의 매칭 스코어가
의 top-k 스코어에 속해야함
- Hungarian Matching처럼 Set-to-Set(GTs-to-Queries)가 아닌 임계값 기반 매칭임 ← C-Decoder는 Self-Attention이 없어 Global 최적화가 필요치 않아 해당 방식이 더 적절함
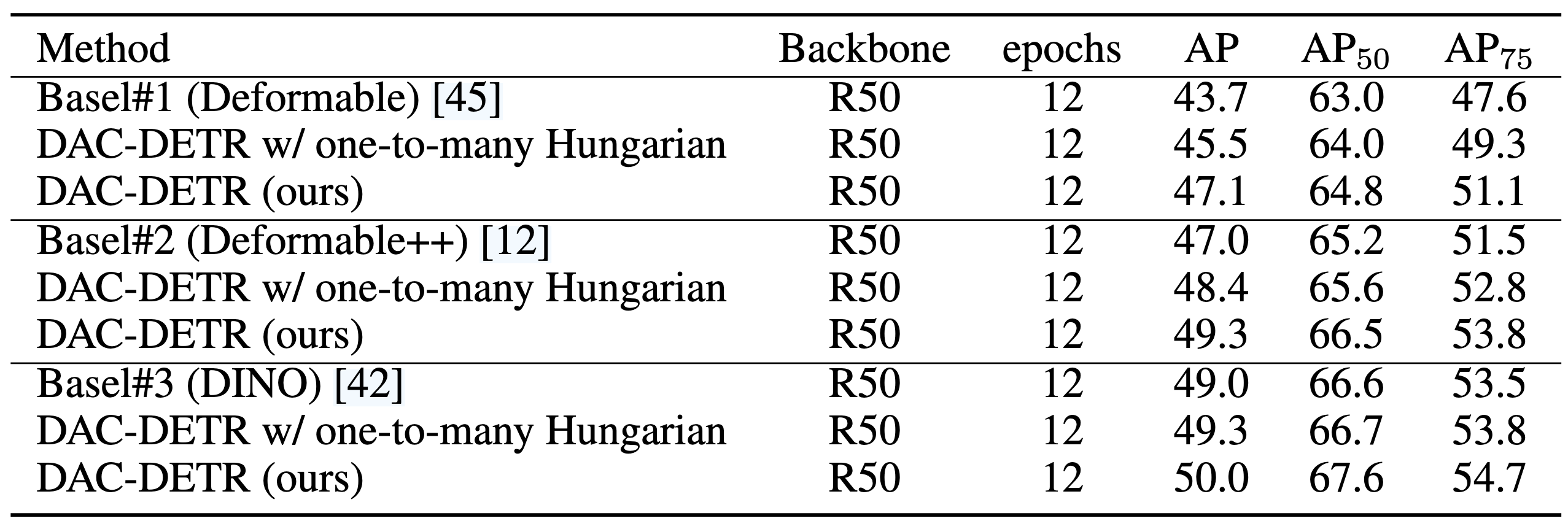
- 특정 Query와의 매칭 스코어가 임계값
Analysis
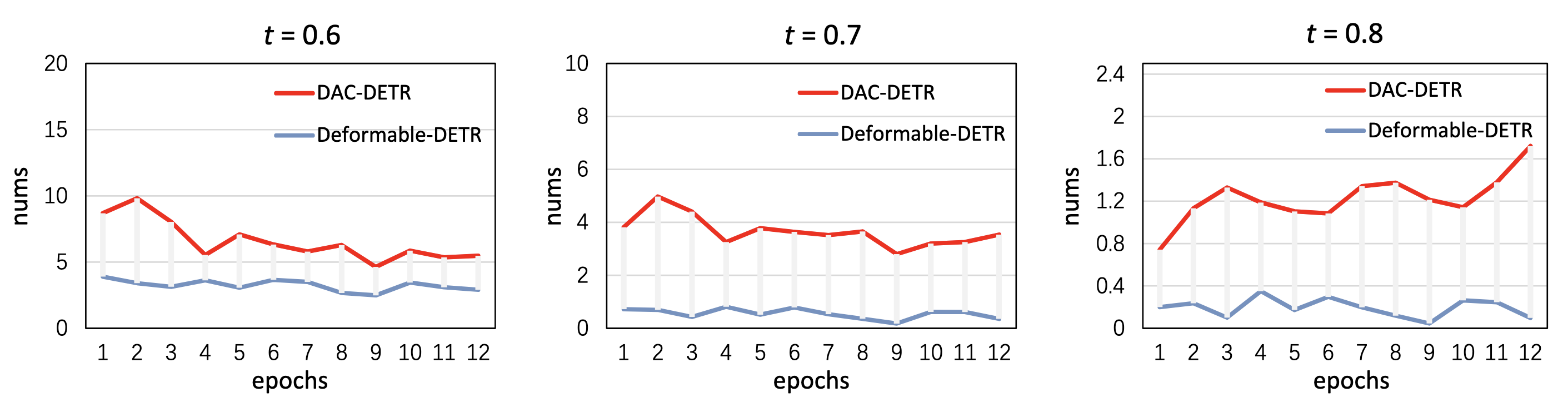
- 오브젝트당 할당되는 임게값 이상의 스코어를 가지는 쿼리의 개수가
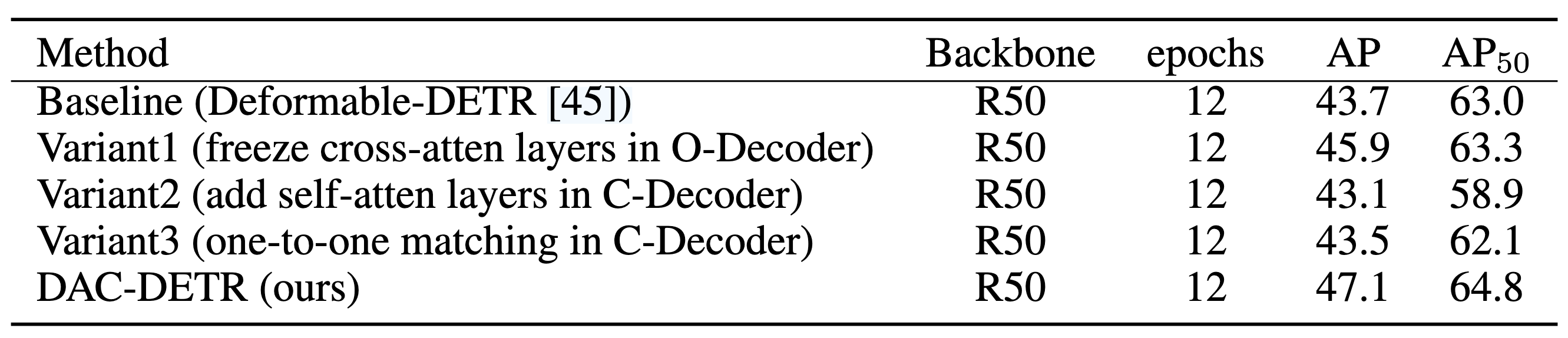
- Variant1: C-Deocoder를 이용해 과정을 분리하는 것 만으로 성능 향상이 있음
- variant2&3: One-to-Many 사용하고 Self-Attn 추가하기 vs One-to-One 사용하고 Self-Attn 없애기 → 둘 다 성능 하락