LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example -- deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by a factor of 10,000 and the GPU memory requirement by a factor of 3. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptation, which sheds light on the efficacy of LoRA. We release a package that facilitates the integration of LoRA with PyTorch models and provide our implementations and model checkpoints for RoBERTa, DeBERTa, and GPT-2 at https://github.com/microsoft/LoRA.
Problem:: 대규모 언어 모델 파인튜닝의 계산 및 저장 비용 부담 / 기존 적응 기법들의 추론 지연 및 성능 저하 문제
Solution:: 사전 학습 가중치는 고정하고 훈련 가능한 저순위 분해 행렬을 주입 / 작업별 파라미터 수와 GPU 메모리 요구량 대폭 감소
Novelty:: 모델 적응에서 가중치 변화의 낮은 본질적 순위 특성 발견 / 추론 지연 없이 전체 파인튜닝과 동등한 성능 달성 / 적은 순위(r≤4)만으로도 높은 차원에서 효과적 기능 / 다양한 작업 간 빠른 전환 가능 / 기존 방법들과 직교하여 결합 가능
Note:: Motivation과 방법이 잘 연결되어 있고, 실험 성능이 이를 잘 뒷받침함. 실용성도 높음
Summary
Motivation
- 자연어 처리 모델의 일반적인 패러다임은 일반 도메인 데이터로 대규모 사전 학습 후 특정 작업/도메인에 적응시키는 것
- 모델 크기가 커질수록 모든 파라미터를 재학습하는 전체 파인튜닝(Full Fine-Tuning)이 비실용적
- GPT-3 175B 기준 독립적인 파인튜닝 모델 인스턴스를 각각 배포하면 엄청난 비용 발생
- 각 다운스트림 작업마다 175B 파라미터가 필요
- 기존 접근법의 한계:
- Adapter 기반 방법: 새로운 층을 추가하여 모델 깊이가 늘어나 추론 지연 시간 발생
- Prefix-Tuning 기반 방법: 시퀀스 길이를 소비하여 활용 가능한 입력 길이 감소
- 대부분의 방법이 파인튜닝 대비 성능 저하 발생, 효율성과 모델 품질 사이 트레이드오프 존재
- 저자들은 이전 연구에서 과잉 매개변수화된 모델이 본질적으로 낮은 차원에 위치한다는 사실에 영감을 받음
- 모델 적응 과정에서 가중치 변화 역시 낮은 "본질적 순위(Intrinsic Rank)"를 가진다는 가설 수립
Method
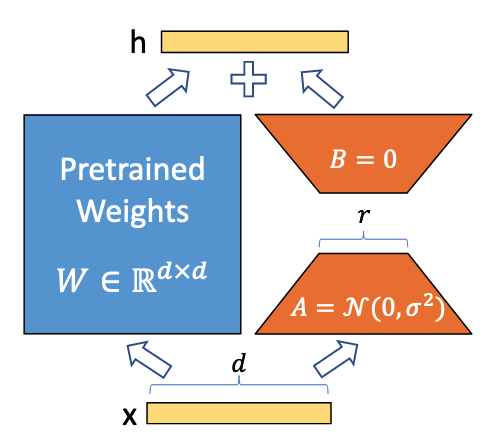
Low-Rank-Parametrized Update Matrices
- 신경망의 밀집층(Dense Layer)에서 가중치 행렬 업데이트를 저순위 분해로 제한
- 사전 학습된 가중치 행렬
에 대해: - 기존:
(전체 파라미터 업데이트) - LoRA:
(저순위 분해 표현) , - 순위
- 기존:
- 학습 중
는 고정되고 와 만 학습 파라미터 포함 - 순방향 전달 시:
는 가우시안 무작위 초기화, 는 0으로 초기화하여 학습 초기에 - 스케일링 인자
을 사용하여 초기화와 순위 변경 시 하이퍼파라미터 재조정 필요성 감소
Transformer에 LoRA 적용
- Transformer 아키텍처의 여러 가중치 행렬 중 일부에 선택적으로 적용 가능
- Self-Attention 모듈의 가중치 행렬
, , , 와 MLP 모듈의 두 가중치에 적용 가능 - 실험에서는 단순화와 파라미터 효율성을 위해 주의 가중치만 적응시키고 MLP 모듈은 고정
- GPT-3 175B에서
와 Query/Value 투사 행렬만 적응시킬 경우: - 체크포인트 크기를 약 10,000배 축소(350GB에서 35MB로) → 배포 자원 효율성 극대화
- 훈련 중 VRAM 사용량을 1.2TB에서 350GB로 감소 → 더 적은 하드웨어로 학습 가능
- 파라미터 대부분의 그래디언트를 계산할 필요가 없어 학습 속도 25% 향상 → 더 효율적인 학습
실용적 이점과 한계
- 감소된 메모리 및 저장 공간 사용으로 더 적은 GPU로 학습 가능
- 배포 시 하나의 사전 학습 모델에 여러 작업별 LoRA 모듈을 저비용으로 교체 가능
- 학습된 가중치를 배포 시 기존 가중치와 병합하여 추론 지연 시간 없음
- 한계점: 서로 다른 작업의 입력을 단일 순방향 전달에서 일괄 처리하기 어려움
Method 검증
실험 환경
- 다양한 모델과 태스크에 걸쳐 LoRA 성능 평가:
- RoBERTa와 DeBERTa: GLUE 벤치마크 (자연어 이해)
- GPT-2: E2E NLG Challenge (자연어 생성)
- GPT-3 175B: WikiSQL(NL to SQL), MultiNLI-matched, SAMSum(대화 요약)
- 기존 방법들과 비교:
- 전체 파인튜닝(FT)
- FTTop2(상위 2개 레이어만 미세 조정)
- 편향 벡터만 학습(BitFit)
- 어댑터 방식(AdapterH, AdapterL, AdapterP)
- 프롬프트 기반 방식(PreEmbed, PreLayer)
RoBERTa 및 DeBERTa 실험 결과
- RoBERTabase와 LoRA(0.3M 파라미터): GLUE 테스트에서 전체 파인튜닝(125M 파라미터)보다 평균 0.8점 우수 → 적은 파라미터로도 더 나은 성능 달성 가능함을 입증
- RoBERTalarge와 LoRA(0.8M 파라미터): 전체 파인튜닝(355M 파라미터)보다 약간 우수한 성능, 다른 어댑터 방법보다도 우수 → 다양한 모델에서의 일관된 효과성 확인
- DeBERTaXXL과 LoRA(4.7M 파라미터): 전체 파인튜닝(1500M 파라미터)과 대등하거나 약간 우수한 성능 → 초대형 모델에서도 효과적임을 확인
GPT-2 실험 결과
- GPT-2 medium 및 large에서 LoRA: E2E NLG Challenge에서 다른 기준선보다 우수한 성능
- LoRA(0.35M 파라미터)는 전체 파인튜닝(354.92M 파라미터) 대비 BLEU 점수 2.2점 상승(68.2 → 70.4) → 생성 태스크에서도 우수한 성능 발휘
- Adapter 계열보다 적은 파라미터로 더 좋은 성능 달성 → 효율성과 성능 모두에서 기존 방법 능가
GPT-3 175B 실험 결과
- LoRA(4.7M 파라미터): WikiSQL 논리 형식 정확도 73.4%, MultiNLI-m 정확도 91.7%, SAMSum에서 R1/R2/RL 53.8/29.8/45.9 달성 → 대규모 모델에서도 효과적임을 입증
- 전체 파인튜닝보다 적은 파라미터로 우수한 성능 기록 → 파라미터 효율성과 성능 간의 균형 달성
- 훈련 가능 파라미터 수와 성능 간의 관계 분석:
- LoRA는 파라미터 수 증가에 따른 성능 향상 패턴이 안정적 → 안정적인 학습 특성 확인
- Prefix 방식은 특정 토큰 수 이상에서 성능 하락 → 기존 방법 대비 확장성 우위
추론 지연 시간 분석
- GPT-2 medium에서 단일 순방향 패스 지연 시간 측정:
- 전체 파인튜닝/LoRA: 19.8±2.7ms(배치 크기 1, 시퀀스 길이 128)
- AdapterL: 23.9±2.1ms(+20.7%)
- AdapterH: 25.8±2.2ms(+30.3%)
- LoRA는 추가 추론 지연 없이 전체 파인튜닝과 동일한 성능 발휘 → 실시간 시스템에 적합