Salience DETR: Enhancing Detection Transformer with Hierarchical Salience Filtering Refinement
DETR-like methods have significantly increased detection performance in an end-to-end manner. The mainstream two-stage frameworks of them perform dense selfattention and select a fraction of queries for sparse crossattention, which is proven effective for improving performance but also introduces a heavy computational burden and high dependence on stable query selection. This paper demonstrates that suboptimal two-stage selection strategies result in scale bias and redundancy due to the mismatch between selected queries and objects in two-stage initialization. To address these issues, we propose hierarchical salience filtering refinement, which performs transformer encoding only on filtered discriminative queries, for a better trade-off between computational efficiency and precision. The filtering process overcomes scale bias through a novel scale-independent salience supervision. To compensate for the semantic misalignment among queries, we introduce elaborate query refinement modules for stable two-stage initialization. Based on above improvements, the proposed Salience DETR achieves significant improvements of +4.0% AP, +0.2% AP, +4.4% AP on three challenging task-specific detection datasets, as well as 49.2% AP on COCO 2017 with less FLOPs. The code is available at https://github.com/xiuqhou/Salience-DETR.
Problem:: 큰 객체 위주의 쿼리 선택으로 작은 객체 탐지에 어려움(Scale Bias)/또한 객체 수보다 훨씬 많은 쿼리를 처리하여 비효율적임(Redundancy)
Solution:: Salience Supervision으로 Scale Bias 해소/Hierarchical Filtering으로 쿼리개수 줄임&Refinement로 성능은 보존
Novelty:: 기존의 Binary Supervision이 아니라 스케일에 독립적인 Salience Supervision을 도입
Note:: Focus DETR을 안 읽고 읽어서 그럴 수도 있는데, 진짜 논문 개같이 쓴듯. Github에도 내용 묻는 사람이 있음/어차피 Decoder Query 샘플링 할건데, Encoder에서 굳이 다 연산해야되나 + 연산 안하면 성능 박살나니까 추가과정 있어야되네
Summary
Problem
- 기존의 DETR(Detection Transformer)류 모델은 두 단계로 동작:
- Encoder에서 모든 위치의 쿼리에 대해 Self-Attention을 수행함
- 이후 Decoder에서 일부 쿼리만 Cross-Attention 수행함
- 이 과정에서 두 가지 핵심 문제가 발생:
- Scale Bias: 두 번째 단계(Decoder 진입 전)에 선택되는 쿼리가 큰 객체 위주로 편향됨
- Redundancy: 객체 수보다 많은 불필요한 쿼리를 처리하여 연산 효율이 떨어짐
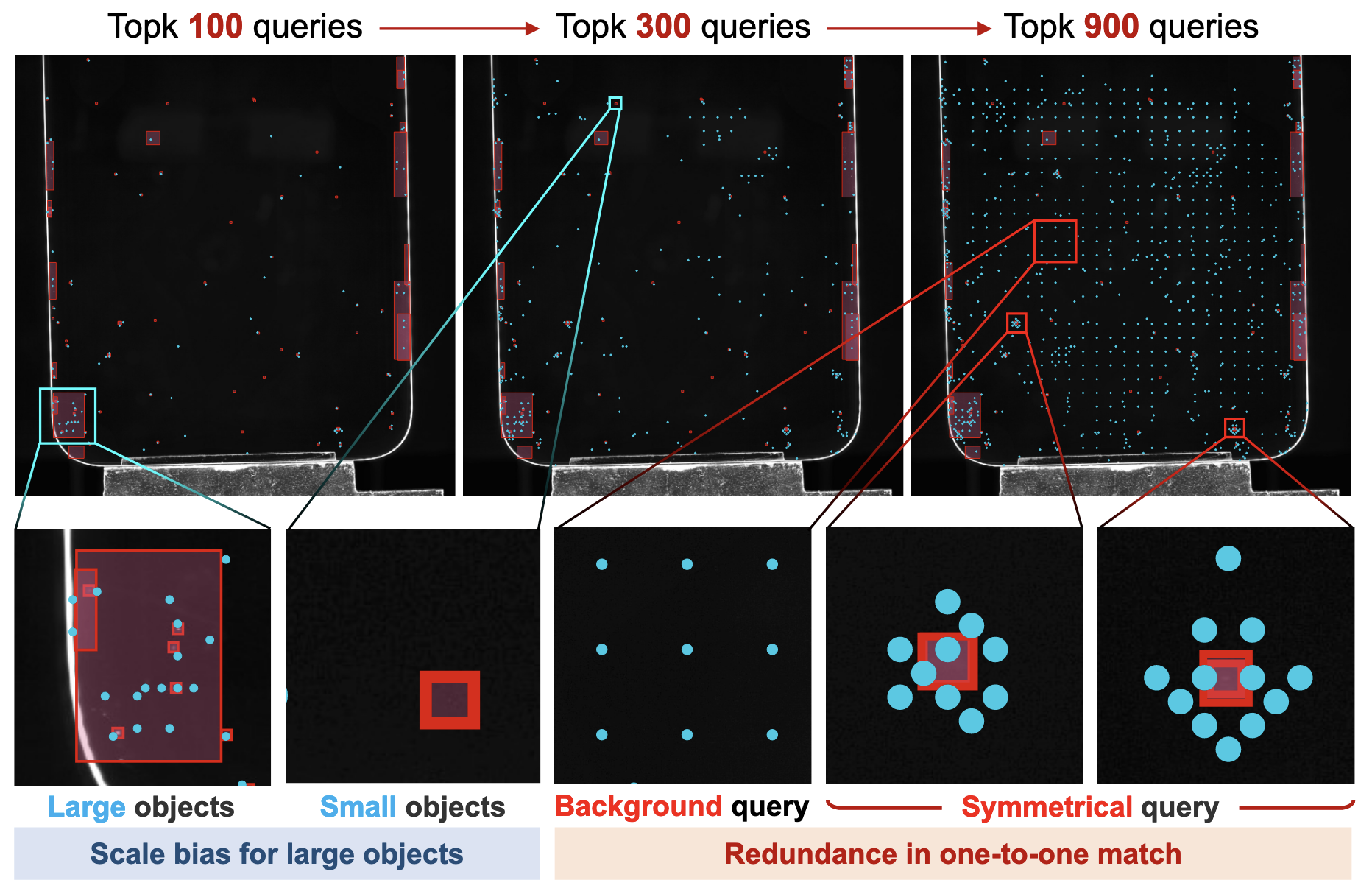
빨간색 상자: GT Box, 하늘색 점: Query → 큰 상자에 Query가 쓸데 없이 많음 & 작은 상자에는 없음. Symmetrical Query는 나타는 냈는데 논문에 추가 언급 없음
Method
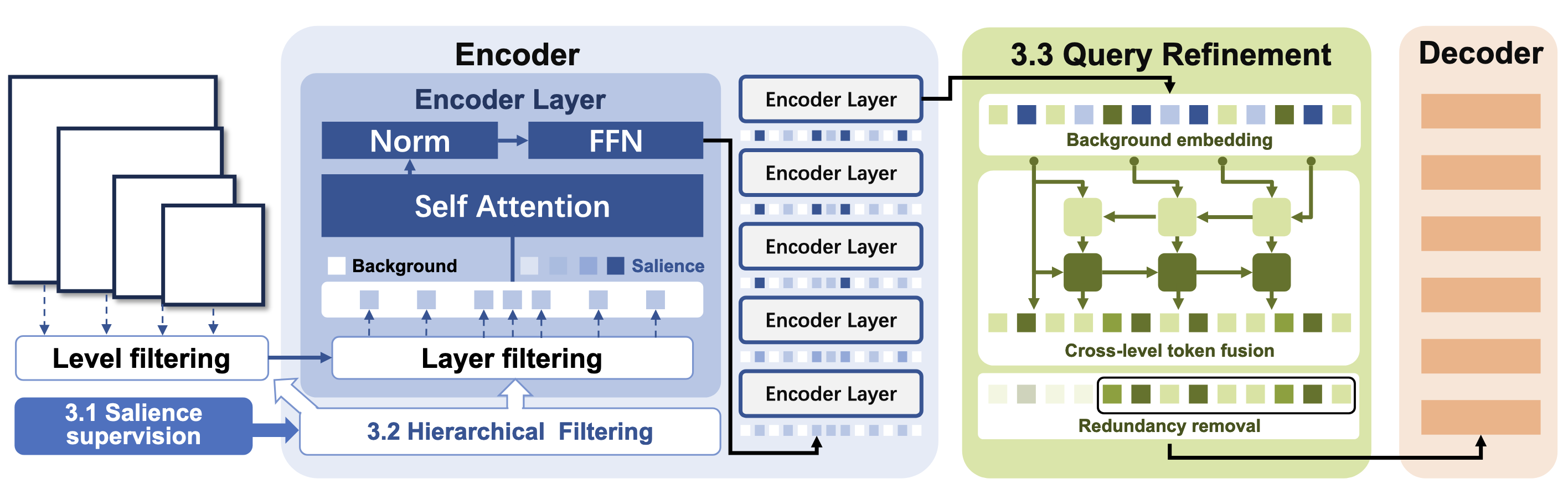
Salience-Guided Supervision
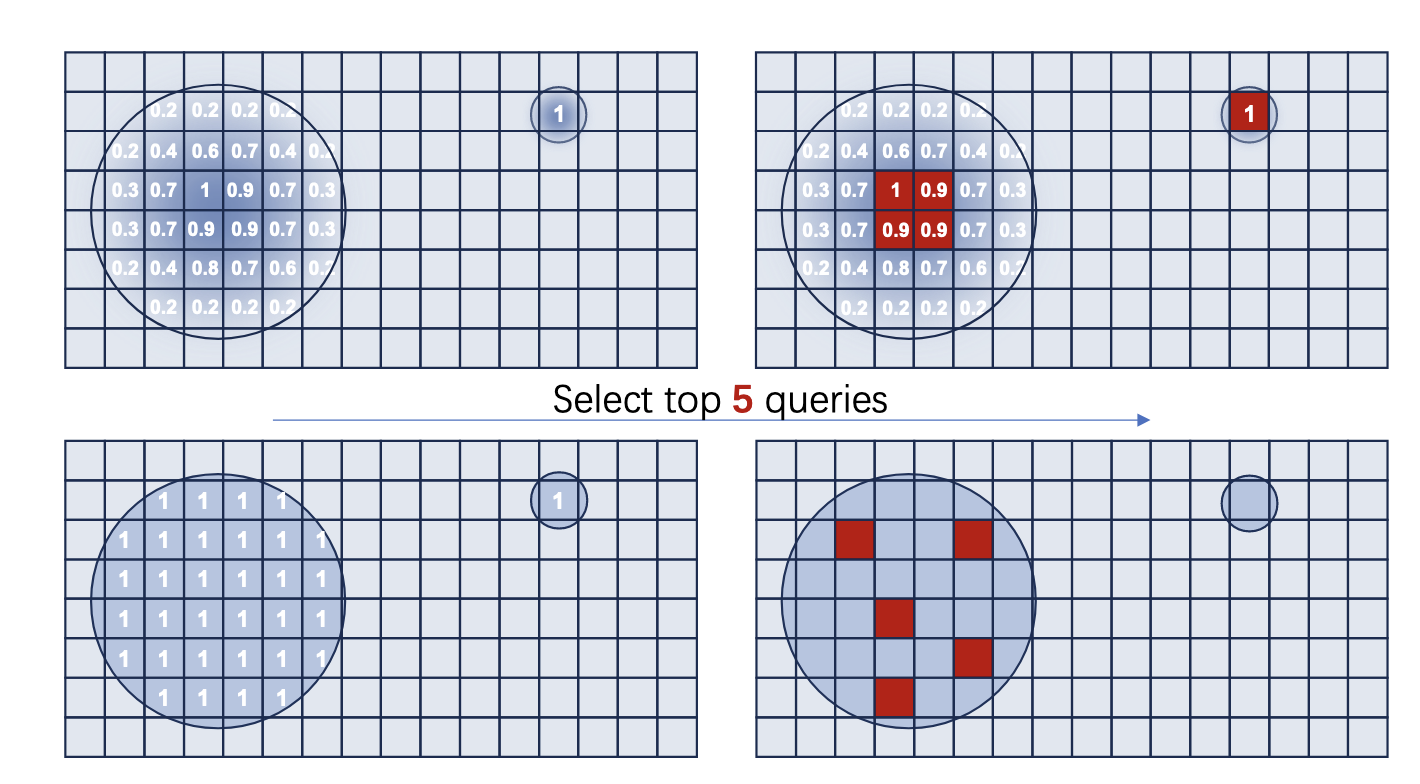
-
각 쿼리의 중요도를 평가하는 Supervision을, 단순한 전경/배경이 아닌 Scale Independent Salience Supervision로 정의
- 위 그림의 두 번째 행을 보면 단순 전경/배경으로 나눈건 작은 전경이랑 큰 전경의 여러 쿼리랑 동일 취급이라 샘플링이 이상함
-
쿼리 위치와 객체 중심 사이의 상대적 거리에 기반하여 중요도(Salience)를 연속적 점수로 표현:
- (
, ): Query의 위치와 GT Bbox의 중심점 차이의 거리 (최대 1/2)
- (
-
즉, 쿼리가 객체 Bbox안에 속하면 위 Score로 계산, 아니면 0
- 이 Score는 Query를 Filtering하는데 사용하는 것이 아니라 Loss 계산 시 사용함
Hierarchical Filtering
- 각 Feature Level 및 Encoder Layer에서 독립적으로 중요도 상위 Top-K 쿼리만 선택하여 Transformer Encoder 내에서 Attention 연산 수행
- Feature Level: Backbone에서 추출한 Multi-Scale Feature Maps
에서 각 L마다 뽑는 개수 이 정해져 있음 - Encoder Layer: Transformer Encoder 내의 개별 Layer 마다 뽑는 개수
이 정해져 있음 - 따라서 최종적으로 각 Layer 및 Feature마다
개의 토큰을 뽑음 - Focus DETR은 Layer별로 뽑는 개수만 정해져 있었음 → 인코더에서 SA를 수행하는 토큰 개수를 더 줄임
- Feature Level: Backbone에서 추출한 Multi-Scale Feature Maps
- DETR과 달리 모든 토큰을 Encoder에 넣어 Self-Attention 하지 않고, Score에 따라 선택된 것들만 Self-Attention을 수행 (Key&Value는 선택된 것들 외에 다른 것들도 포함됨) → 전체 토큰 안쓰니까 연산량 :LiArrowDown: 근데 성능은 개박살 나겠지? → Query Refinement
- 여기서 Score는 Prediction Score를 의미하고 일반적인 DETR과 동일함. 차이는 내부적으로 Background/Foreground를 구분하는 MaskPredictor가 하나 존재함
→ Focus DETR과 달리 자기들은 Feature Level에 따라서 Filtering을 조절 할 수 있다를 강점으로 내세움 (?)
- 여기서 Score는 Prediction Score를 의미하고 일반적인 DETR과 동일함. 차이는 내부적으로 Background/Foreground를 구분하는 MaskPredictor가 하나 존재함
Query Refinement
- 위의 과정으로 선택되지 않은 쿼리(Unselected Queries) 는 Encoder에서 아무 업데이트 없이 남음
- 이런 배경 쿼리는 의미적으로 빈약해지고 Semantic Misalignment가 생길 수 있음
- Focus DETR은 배경 정보를 이용하기 위한 Dual-Attention (Selected Query간의 SA + Unselected Query와의 CA) 도입
- 본 논문은 Dual-Attention에서 CA만 남김
- 연산량 줄이려고 SA 다 안하니까 성능 박살난거 보충해줘야지
Background Embedding
- Hierarchical Salience Filtering 과정에서 선택되지 않은 배경 쿼리(Unselected Queries) 는 Encoder에서 Attention 연산이 수행되지 않아 Semantic Misalignment이 발생 → Unselected Queries인 배경 쿼리에 위치 정보 기반의 임베딩 추가:
- 논문에서는 Absolute 위치 임베딩 (좌표 임베딩)을 추가.
- 이를 통해 배경 쿼리의 의미적 안정성 확보.
- Relative Embedding도 수행 했는데, 실험적으로 Absolute Embedding이 더 좋음 → Query Filtering에서 각 Query의 위치를 기반으로 수행 되었기 때문에 직접적인 위치 정보를 제공하는 Absolute가 더 효과적인 것으로 보임
Cross-Level Token Fusion
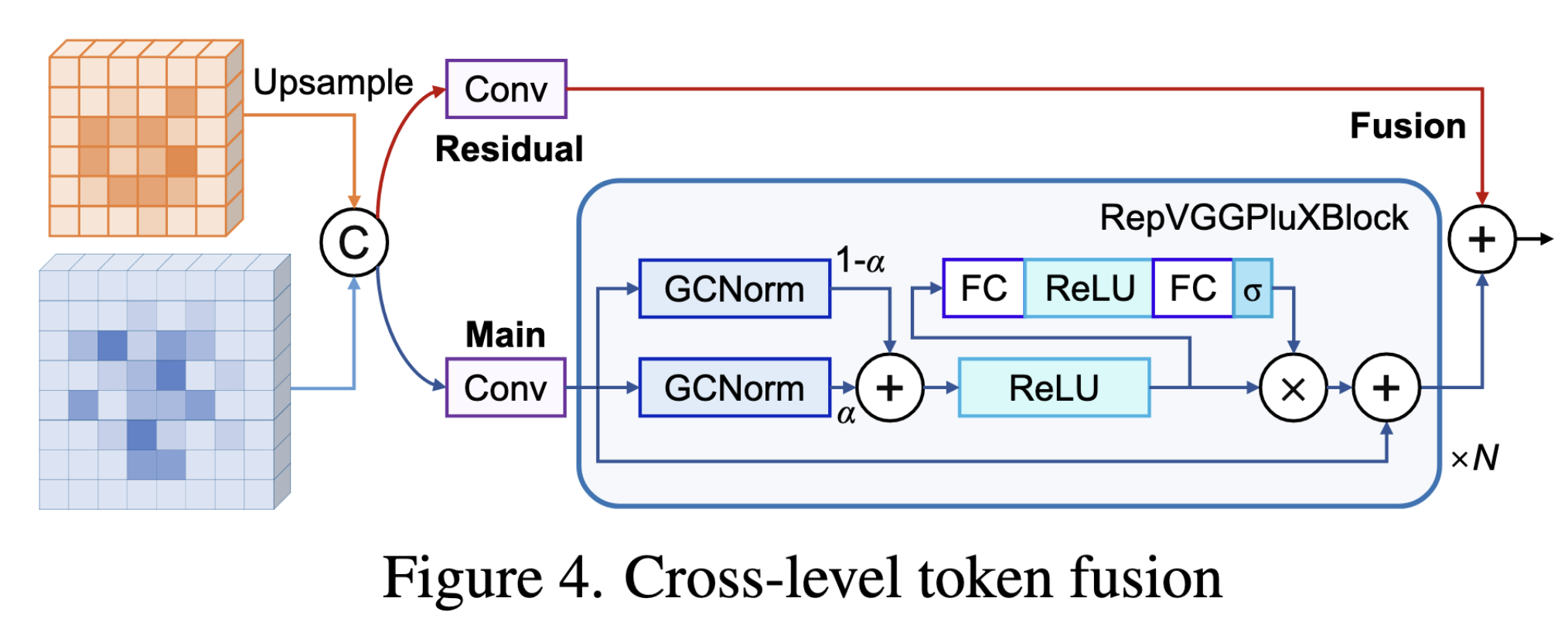
- 서로 다른 해상도(Multi-Scale)를 가진 Feature Level 간 Semantic Misalignment 해결을 위해 피처 간 정보를 통합하는 과정
- 본 논문은 Feature Level에 따른 Query 개수를 제한 했으므로, Misalignment가 발생 할 수 있음
- 최종적으로 선택된 쿼리와 배경 쿼리를 모두 통합하여, 서로 다른 해상도의 Feature Level 간 융합 진행
- 이는 서로 다른 Feature Level의 의미적 차이를 해소하고 객체 탐지 성능을 최적화하는 과정
Redundancy Removal for Two-Stage Queries
-
두 번째 단계(Decoder 진입 전)의 두드러짐이 낮거나 중복된 쿼리를 제거하여 탐지 효율성과 성능 향상.
-
객체를 대표하기에 부족하거나 중복된 쿼리를 Non-Maximum Suppression (NMS) 방식을 활용해 제거:
-
특히 작은 객체가 많은 경우 Decoder의 초기화 과정에서 중복 쿼리로 인한 성능 저하를 막아, 더 효과적인 최종 쿼리를 확보함.
Method 검증
- 3개의 특수 목적 데이터셋 (ESD, CSD, MSSD) 및 일반 탐지 데이터셋 (COCO)에서 성능 평가.
- 기존 방법(DINO, Focus-DETR 등) 대비 AP(정밀도), AR(재현율) 등의 평가 지표에서 우수한 성능 기록.
- Ablation study를 통해 개별 요소(Salience Supervision, Background Embedding, Cross-level Fusion)의 효과성 검증.
- 추가 연산량은 최소화하면서, 높은 성능을 얻는 방법임을 실험으로 입증.