Probing Unlearned Diffusion Models: A Transferable Adversarial Attack Perspective
Advanced text-to-image diffusion models raise safety concerns regarding identity privacy violation, copyright infringement, and Not Safe For Work content generation. Towards this, unlearning methods have been developed to erase these involved concepts from diffusion models. However, these unlearning methods only shift the text-to-image mapping and preserve the visual content within the generative space of diffusion models, leaving a fatal flaw for restoring these erased concepts. This erasure trustworthiness problem needs probe, but previous methods are sub-optimal from two perspectives: (1) Lack of transferability: Some methods operate within a white-box setting, requiring access to the unlearned model. And the learned adversarial input often fails to transfer to other unlearned models for concept restoration; (2) Limited attack: The prompt-level methods struggle to restore narrow concepts from unlearned models, such as celebrity identity. Therefore, this paper aims to leverage the transferability of the adversarial attack to probe the unlearning robustness under a black-box setting. This challenging scenario assumes that the unlearning method is unknown and the unlearned model is inaccessible for optimization, requiring the attack to be capable of transferring across different unlearned models. Specifically, we employ an adversarial search strategy to search for the adversarial embedding which can transfer across different unlearned models. This strategy adopts the original Stable Diffusion model as a surrogate model to iteratively erase and search for embeddings, enabling it to find the embedding that can restore the target concept for different unlearning methods. Extensive experiments demonstrate the transferability of the searched adversarial embedding across several state-of-the-art unlearning methods and its effectiveness for different levels of concepts.
Problem:: 기존 Unlearning Method는 텍스트-이미지 매핑만 변경하고 시각적 콘텐츠는 보존 / 기존 프로빙 방법은 전이 가능성 부족하고 White-Box 환경 요구 / Prompt-Level 방법은 유명인 신원 같은 좁은 개념 복원에 실패
Solution:: 반복적으로 컨셉과 관련된 영역을 찾고 지워서 기존 방법들이 변경하지 매핑하지 못한 영역의 임베딩을 사용
Novelty:: 블랙박스 환경에서도 동작 가능 / 기존 언러닝 방법들의 한계점이 저밀도 영역에 있음을 발견 (컨셉과 가까운 영역은 고밀도)
Note:: 실험에 사용한 Unlearned Method가 전부 Stable Diffusion 기반이라 잘 동작한 듯, 진짜 Black-Box라면 Stable Diffusion도 몰랐어야 하지만 현실적으로 쉽지 않아보임 / 기존 Unlearning의 한계는 관련 개념을 텍스트 영역에서만 지우는 것
Summary
Motivation
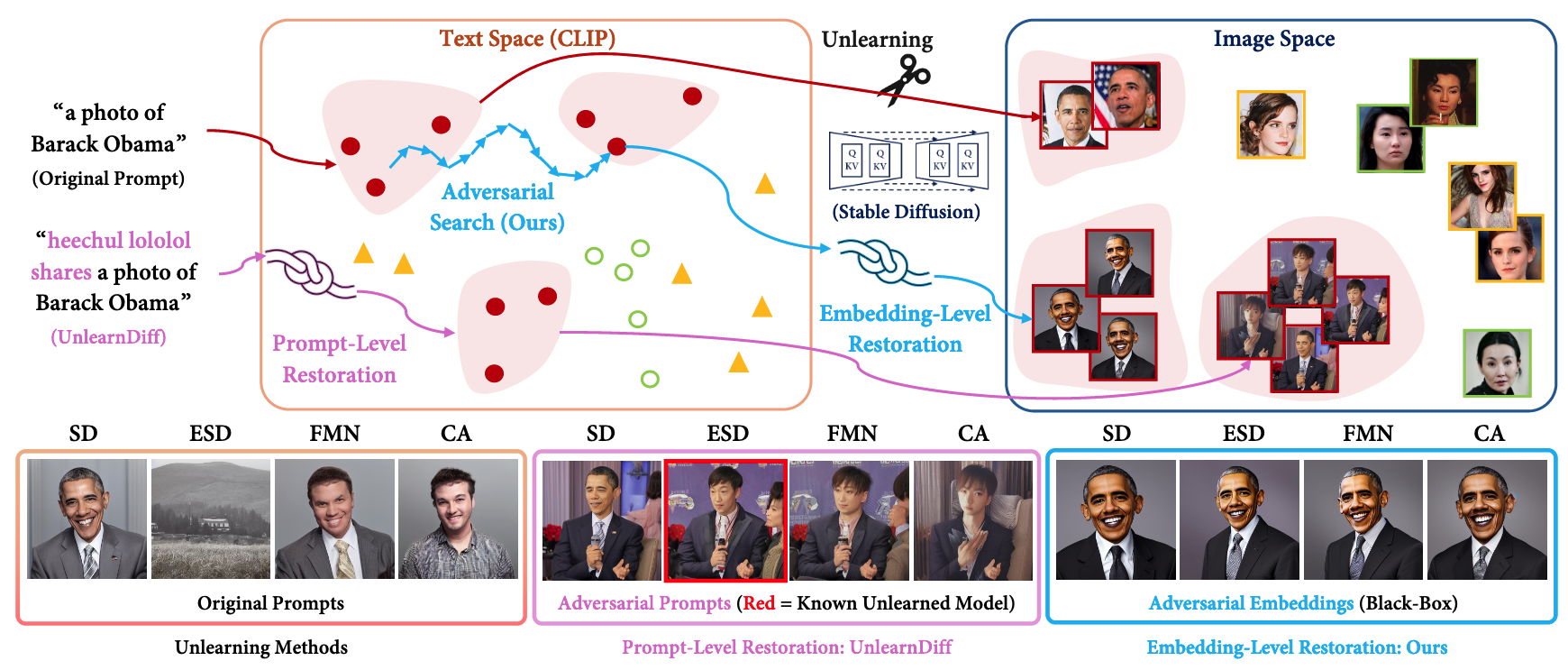
즉, Text Space에서 대표적인 컨셉을 이용한 조작은 Unlearning 방법들이 쉽게 막을 수 있음 → 해당 컨셉의 사진을 만들지만 언어와 크게 연결되어 있지 않은 영역을 찾자
- 텍스트-이미지 Diffusion Model에서 유명인 신원 침해, 저작권 침해, NSFW 콘텐츠 생성 등 안전 문제 발생
- 이러한 문제 해결을 위해 Unlearning Method(ESD, FMN, CA 등)가 개발됨
- 그러나 기존 Unlearning Method는 텍스트-이미지 매핑만 변경하고 시각적 콘텐츠는 여전히 보존
- 기존 Unlearning Method의 취약성을 프로빙하는 방법의 문제점:
- 전이 가능성 부족: 일부 방법은 White-Box 환경에서만 작동하며 다른 Unlearned Model로 전이가 어려움
- 공격 한계: Prompt-Level 방법은 유명인 신원과 같은 좁은 개념 복원에 실패
Method
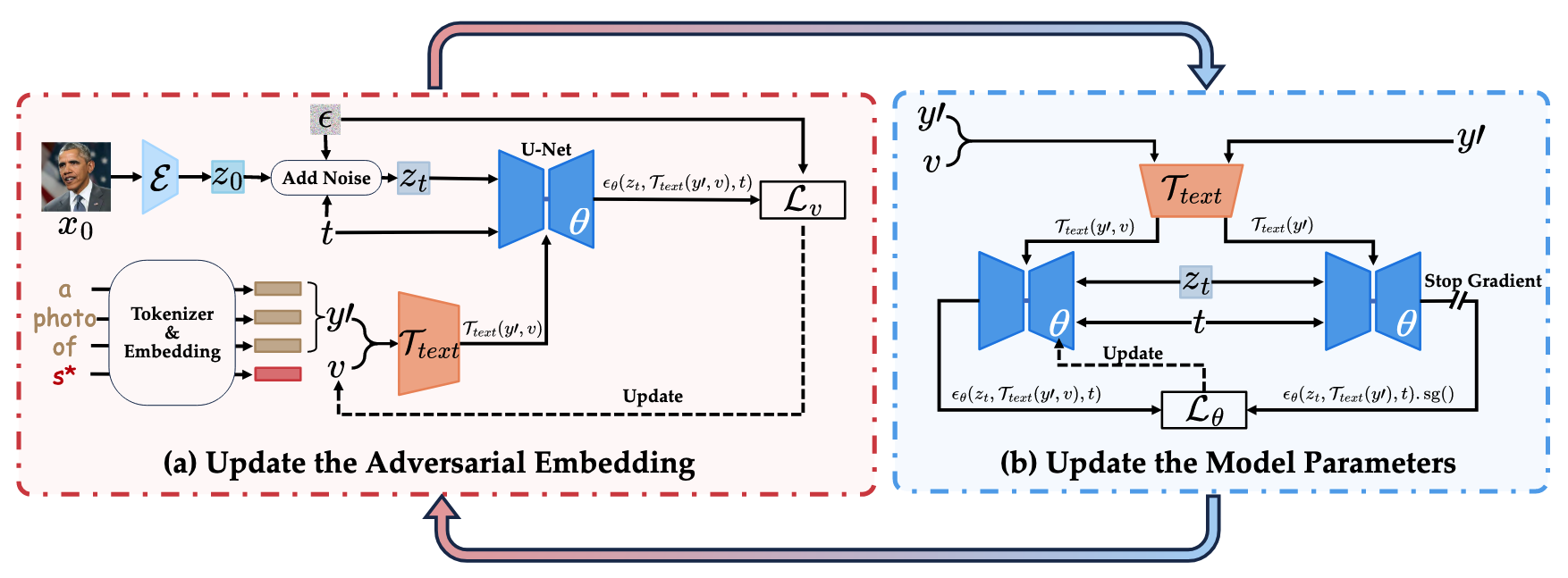
- 제안 방법: Black-Box 환경에서 Unlearning 견고성을 프로빙하는 전이 가능한 Adversarial Attack 개발
- 여기서 Black Box란 Stable Diffusion으로 찾은 Embedding을 다른 모든 Unlearned Model에 적용한다는 의미 → 다른 Unlearned Model이 다 Stable Diffusion 기반이라 사실 당연히 잘 적용됨
- 전이 가능성이 낮은 이유 분석: 초기에 얻은 임베딩들은 고밀도 영역에 위치하여 쉽게 지워짐
- Adversarial Search(AS) 전략 제안: 모델을 공격해서 Concept이랑 텍스트 영역에서 유사한 거 찾고, 이걸 다시 Unlearning하는 방식을 반복해서 Concept 주변에 뭉친 임베딩 말고 좀 떨어져 있는 임베딩을 사용하자
- 원본 Stable Diffusion 모델만 Surrogate Model로 사용하여 블랙박스 환경 구현
- 반복적으로 임베딩을 지우고(Inner Max) 지워지지 않는 임베딩 탐색(Outer Min)
- 고밀도 영역에서 저밀도 영역으로 임베딩 탐색 유도
- 후반 에폭에서 얻은 저밀도 영역의 임베딩들은 다양한 Unlearning Method에서 간과되기 쉬워 타겟 개념 복원 가능
- Min-Max 최적화 과정:
- 최적화 목표:
- Inner Maximization: 찾아낸 adversarial embedding(v)이 타겟 개념을 생성하지 못하도록 모델 파라미터(θ) 업데이트
- Outer Minimization: 모델이 지우려고 해도 타겟 개념을 복원할 수 있는 임베딩(v) 탐색
- 최적화 목표:
Method 검증
Embedding 시각화
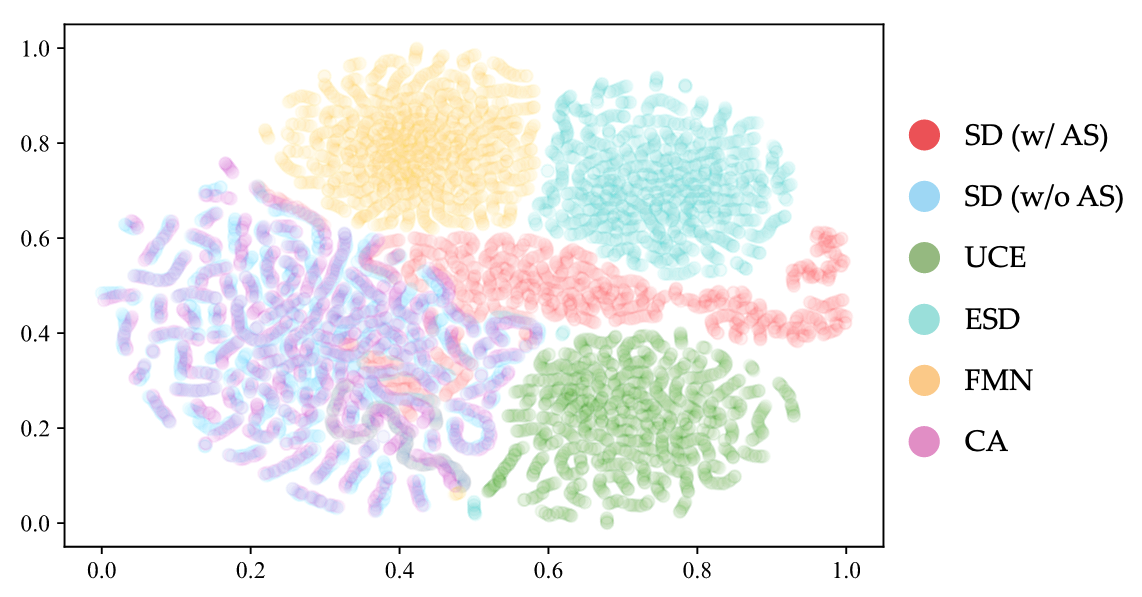
- 제안 방법은 기존 Unlearning 방식이 사용하지 않는 임베딩 스페이스를 찾았으며, 해당 스페이스는 기존 방법들이 탐색하지 않았으므로 공격에 유효함
객체 개념 복원
- 실험 설정: 넓은 객체("Dog")와 좁은 객체("English Springer") 복원 평가
- 넓은 객체에서 제안 방법의 평균 복원율 94.5% 달성 → Prompt-Level 공격(54-55%)보다 월등히 우수
- 좁은 객체에서 제안 방법의 평균 복원율 42.8% 달성 → 좁은 개념은 지우기 쉽고 복원이 어려움을 확인
- White-Box Embedding 공격은 알려진 Unlearning Method에서만 효과적 → 실제 환경에 적용하기 제한적
예술 스타일 복원
- 실험 설정: "Van Gogh" 스타일 복원 성능 평가
- 제안 방법의 평균 복원율 45.3% 달성 → 모든 비교 방법보다 우수
- 추가 실험에서 다양한 예술가(Monet, Picasso, Chagall) 스타일에서도 효과적 복원 → 방법의 일반화 능력 입증
NSFW 콘텐츠 복원
- 실험 설정: Nudity 콘텐츠 복원 성능 평가
- 제안 방법의 평균 복원율 64.9% 달성 → Prompt-Level 공격(23-36%)보다 훨씬 우수
- 모든 Unlearning Method에서 안정적 복원 성능 → 콘텐츠 필터링 시스템의 취약점 확인
유명인 신원 복원
- 실험 설정: "Barack Obama" 등 유명인 신원 복원 성능 평가
- 제안 방법의 평균 복원율 55.5% 달성 → 비교 방법들(0-27%)보다 월등히 우수
- 다양한 유명인(Emma Watson, Brad Pitt 등)에서도 높은 복원율(평균 85.8%) → 기존 복원 방법으로는 어려웠던 ID 복원 문제 해결
Ablation Study
- Adversarial Search 전략 효과 분석
- AS 없이는 대부분의 Unlearning Method에서 타겟 ID 복원 실패 → AS가 전이 가능성에 핵심 요소임을 입증
- AS 적용 시 훈련 후반부로 갈수록 ID 예측 점수 점진적 증가 → 저밀도 영역에서 전이 가능한 임베딩 발견 확인 → 당연히 충분히 개념이 제거 된 후에 찾은 임베딩이 효과적
- 언러닝 방법에 대한 지식이나 모델 접근 없이도 원본 SD 모델만으로 효과적인 adversarial 임베딩 발견 가능