This paper views the DETR’s non-duplicate detection ability as a competition result among object queries. Around each object, there are usually multiple queries, within which only a single one can win the chance to become the final detection. Such a competition is hard: while some competing queries initially have very close prediction scores, their leading query has to dramatically enlarge its score superiority after several decoder layers. To help the leading query stands out, this paper proposes EASEDETR, which eases the competition by introducing bias that favours the leading one. EASE-DETR is very simple: in every intermediate decoder layer, we identify the “leading / trailing” relationship between any two queries, and encode this binary relationship into the following decoder layer to amplify the superiority of the leading one. More concretely, the leading query is to be protected from mutual query suppression in the self-attention layer and encouraged to absorb more object features in the cross-attention layer, therefore accelerating to win. Experimental results show that EASE-DETR brings consistent and remarkable improvement to various DETRs.
Synth
Problem:: DETR 모델에서는 동일 객체를 탐지하기 위해 다수의 쿼리들이 경쟁하면서 학습 비효율이 발생/초기 단계에서 근소한 차이를 갖는 선두 쿼리가 후발 쿼리와의 점수 차이를 크게 벌리기는 어려움
Solution:: 선두 쿼리에 유리한 편향을 제공하는 EASE-DETR 기법을 제안함
Novelty:: 논문은 최초로 “쿼리 간의 경쟁”을 성능 저하의 근본 원인으로 명확히 규명하고 해결/쿼리 간 경쟁 관계를 명시적으로 Self-Attention과 Cross-Attention 단계 모두에서 활용
Note:: 디테일한 설명이 부족하고, 코드가 공개되지 않음/자기 자신과의 Relation에 대한 정의가 불명확해 오해의 소지가 있음/Multi Class의 경우 상황에 대한 설명이 부족함
Summary
Motivation
DETR 계열 모델이 객체를 탐지할 때, 한 객체 주변에 여러 개의 유사한 쿼리(Object Queries)가 존재하며, 이 쿼리들이 동일 객체를 탐지하기 위해 서로 경쟁(Competition)하는 현상 발생
이 경쟁에서 최종 탐지를 수행할 단 하나의 쿼리(Leading Query)가 승리하기 위해서는, 초반에 비슷했던 다른 경쟁 쿼리(Trailing Queries)와의 예측 점수 격차를 디코더 층을 지날 때마다 크게 증가시켜야 하는 어려움이 존재
쿼리 간 지나친 경쟁은 모델의 학습 효율을 떨어뜨리고 탐지 성능의 한계를 유발하는 근본 원인임
Method
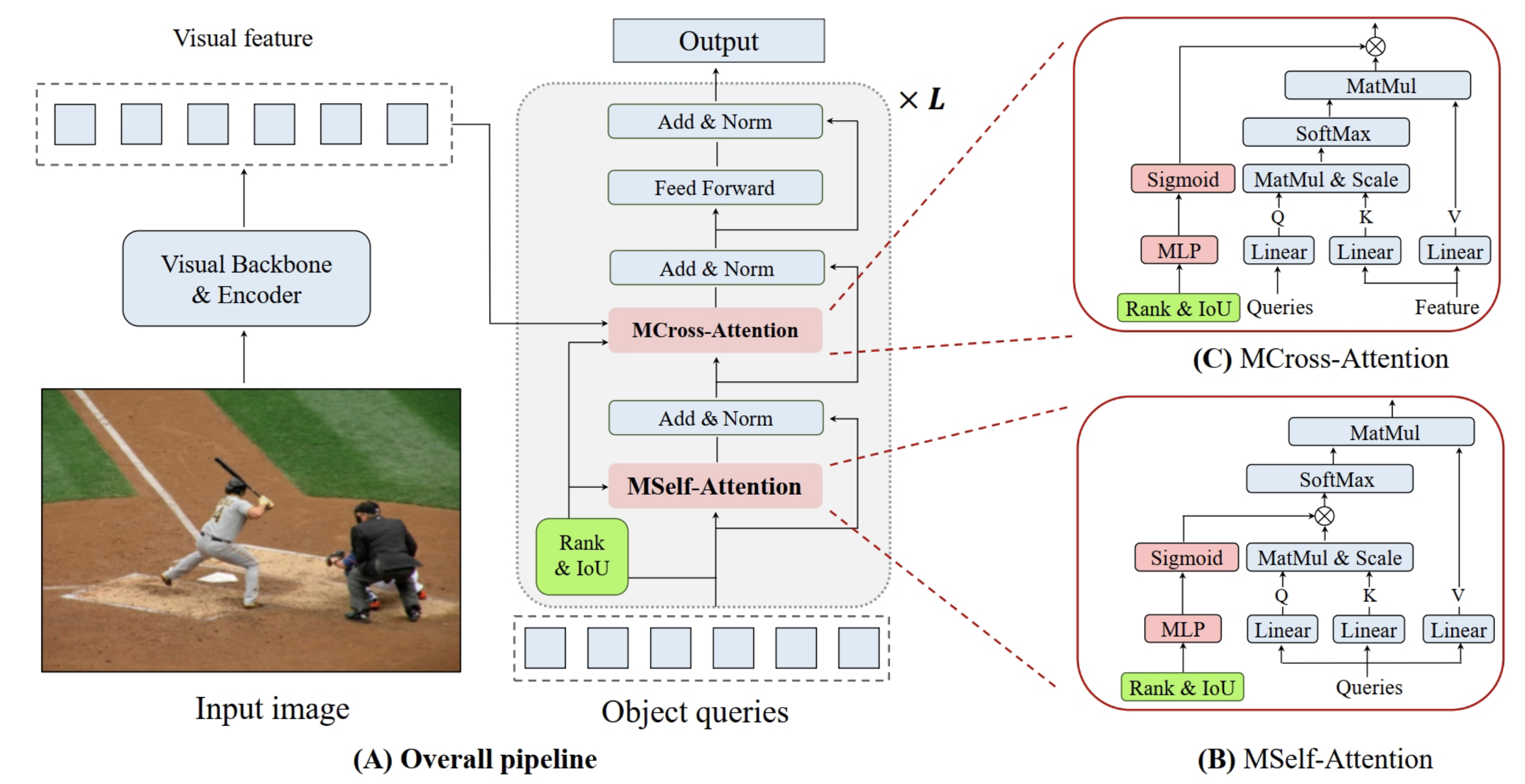
선두 쿼리를 유리하게 만드는 편향(Bias)을 부여하여 쿼리 간 경쟁을 완화하는 접근법(EASE-DETR) 제안
구체적 방법:
각 중간 디코더 층에서 쿼리 간 상대적 순위(Relative Ranking, ) 및 공간적 유사성(Spatial Relation, IoU 기반, )을 정의하고, 이를 이용해 선두 쿼리의 우위를 강화
Self-Attention 단계: 선두 쿼리에 대한 상호 억제(Mutual Suppression)를 완화하고 후발 쿼리는 그대로 유지하여 상대적 격차를 확대
와 를 곱한 후 MLP와 Sigmoid를 통해 감쇠 인자(Decay Factor)를 계산하여, 이를 Self-Attention 점수에 곱함으로써 구현
수식 표현:
MLP: Multi-Head를 위해 단일 스칼라 값인 를 벡터로 만들어 주는 역할
Cross-Attention 단계: 후발 쿼리의 객체 특징 흡수를 감소시켜 선두 쿼리가 상대적으로 더 많은 정보를 얻도록 함
후발 쿼리가 받는 억제 수준(Level of Suppression, )을 계산하여 Cross-Attention의 감쇠 인자로 활용
수식 표현:
자기 자신, 즉 에 대한 설명이 부족함. 이 부분이 중요한게, 이 경우 및 가 낮아지며 이는 자기 자신과의 Attention Weight를 낮춰 오히려 선두 그룹의 학습을 억제하기 때문 → 구현 코드가 존재하지 않아 확인 할 수 없지만, 자기 자신에 대한 값은 건드리지 않는것으로 추정됨
Method 검증
MS-COCO 2017 검증 데이터셋에서 다양한 DETR 기반 모델(Deformable++, DINO, H-DETR)에 적용하여 수치적 성능 비교
Deformable++(ResNet-50)에서 12 epoch 기준 기존 대비 1.3 AP 성능 향상(47.0→48.3 AP)
DINO(ResNet-50)에서 기존 대비 0.7 AP 성능 향상(49.0→49.7 AP)
Swin-L 백본 사용 시, 최신의 Stable-DINO 모델 대비 1.0 AP 향상된 57.8 AP 달성
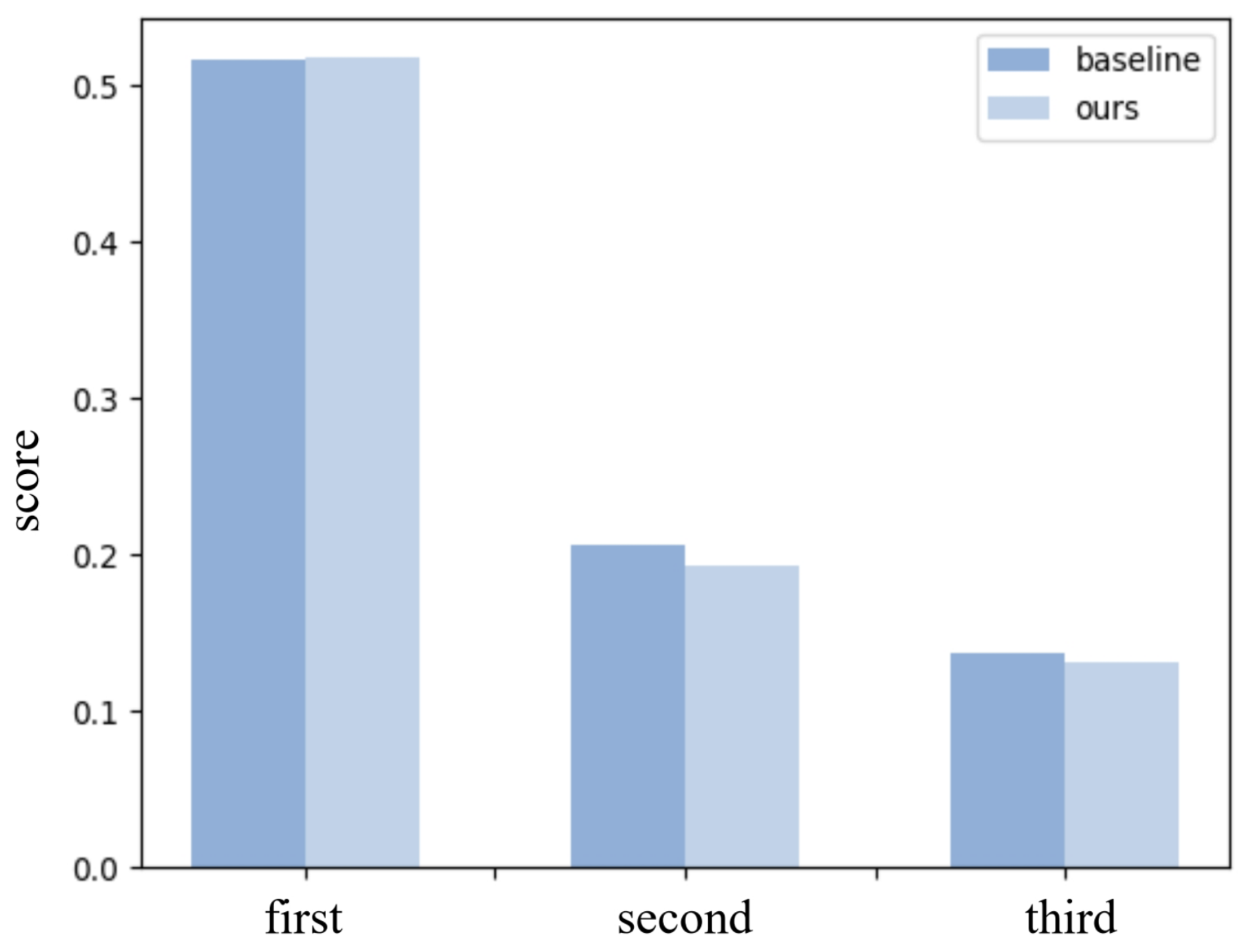
경쟁하는 쿼리들의 최종 예측 점수 분포를 분석하여 선두 쿼리와 후발 쿼리 간 점수 차이가 유의미하게 커졌음을 시각적으로 검증
추가적으로, 다중 뷰(Multi-View) 3D 객체 탐지(PETR 모델)에서도 일관된 성능 개선(+1.6 NDS, +0.9 mAP)을 통해 방법론의 일반성(Generality)을 입증
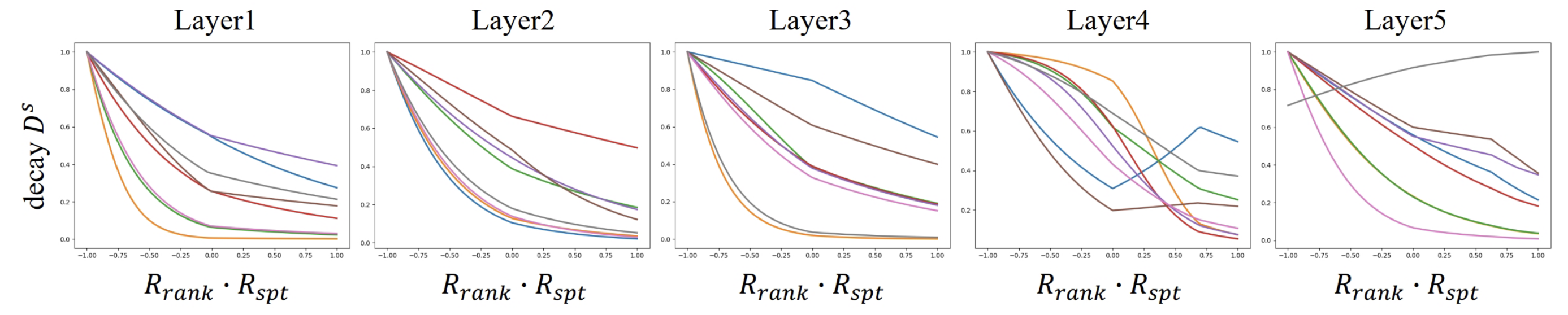
과 의 관계
위 그림은 과 의 관게에 대한 분석으로 값이 증가함에 따라 는 대체로 단조감소(Monotonic Decrease) 하는 경향을 보였음
즉, 값이 커질수록, 감쇠 인자()가 감소하여, 선두 쿼리에 대한 억제가 줄어드는 방향으로 학습된다는 의미임
선두 쿼리와 유사한 경쟁 쿼리들의 Attention Weight는 많이 낮추고, 경쟁 상대가 되지 않는 후발 쿼리들은 적당히 낮춤
이 함수가 비대칭적(Asymmetric) 이라는 것은 다음을 뜻함
양의 값 영역과 음의 값 영역에서의 함수 모양이 서로 다르게 나타남
예컨대, (선두일 때)와 (후발일 때)의 상황에서 값이 다르게 작용하여, 선두 쿼리와 후발 쿼리에 대한 처리를 명확히 구분한다는 것을 나타냄
결과적으로, 이러한 비대칭적이고 단조감소하는 관계가 관찰된다는 사실은 상대적 순위()라는 요소를 Attention에 명시적으로 도입한 것이 의미가 있고 효과적임을 뒷받침하는 근거가 됨
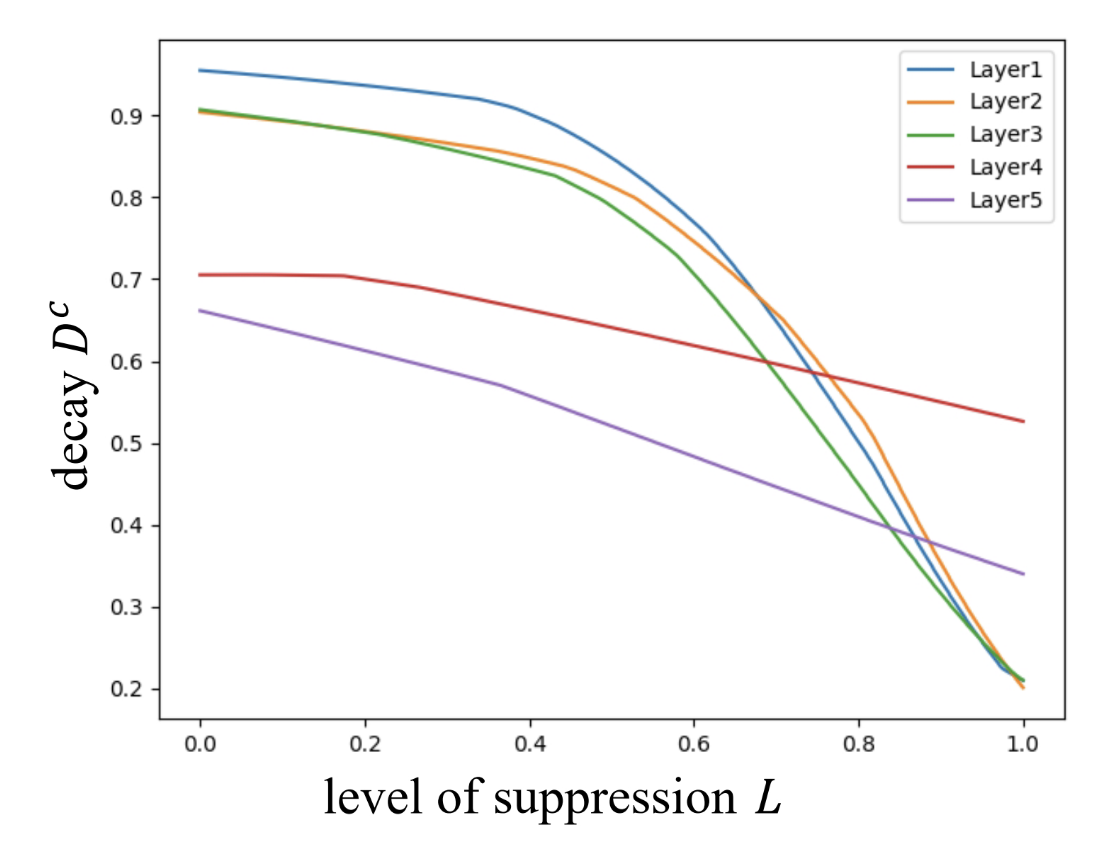
Cross-Attention의 경우도 비슷한 맥락에서 동일한 작용을 함
선두 쿼리는 Cross-Attention의 결과를 그대로 사용, 후발 쿼리들은 감쇠하여 사용
결과적으로, 선두 그룹을 띄우기 위해 나머지들의 가중치를 낮춰 Loss Gradient가 선두그룹에 집중되어 흐르도록 한것임