Unified Concept Editing in Diffusion Models
Text-to-image models suffer from various safety issues that may limit their suitability for deployment. Previous methods have separately addressed individual issues of bias, copyright, and offensive content in text-to-image models. However, in the real world, all of these issues appear simultaneously in the same model. We present a method that tackles all issues with a single approach. Our method, Unified Concept Editing (UCE), edits the model without training using a closed-form solution, and scales seamlessly to concurrent edits on text-conditional diffusion models. We present scalable simultaneous debiasing, style erasure, and content moderation by editing text-to-image projections, and perform extensive experiments demonstrating improved efficacy and scalability over prior work. Our code is available at unified.baulab.info.
Problem:: 텍스트-이미지 디퓨전 모델이 저작권 침해, 편향성, 부적절한 콘텐츠 생성 등 여러 안전 문제 동시 발생 / 기존 방법들은 각 문제를 개별적으로 다루어 실용성 부족 / 데이터 큐레이션만으로는 해결 어렵고 추론 시간 필터링은 우회 가능
Solution:: 디퓨전 모델의 Cross-Attention 가중치를 Closed-Form 수식으로 직접 수정 / 개념 지우기, 편향 제거, 콘텐츠 조절을 통합 방법으로 처리 / 편집 개념과 보존 개념을 명시적으로 구분하여 간섭 최소화
Novelty:: 추가 훈련 없이 즉시 계산 가능한 닫힌 형태 해법 제공 / 여러 개념 동시 편집과 다중 속성(성별, 인종 등) 편향 처리 가능
Note:: 500개 이상에서는 이미지 품질 저하 → 이 논문에서 많은 컨셉 제거에 의한 생성 품질 저하를 처음 보고한 것 같음 / NSFW뿐만 아니라 편향 제거에도 초점을 맞춤 (이 분야의 기본적ㅇ니 연구 방향인가?) / 핵심은 텍스트만 학습 없이 가지고 개념 보존과 수정을 수행 한 것
Summary
Motivation
- 텍스트-이미지 디퓨전 모델은 다양한 안전 이슈 발생
- 아티스트 스타일 복제로 인한 저작권 침해 문제
- 성별, 인종 등 고정관념을 증폭시키는 편향성 문제
- 부적절한 이미지(NSFW) 생성 문제
- 기존 접근법의 한계
- 각 문제를 개별적으로 다루는 방식 (서로 다른 방법론 필요)
- 실제 상황에서는 모든 문제가 단일 모델에 동시에 존재
- 데이터 큐레이션만으로는 문제 해결 어려움 (의도치 않은 효과, 새 편향 발생)
- 추론 시간 필터링은 오픈 소스 환경에서 우회 가능
- 통합 접근법 필요성
- 여러 안전 문제를 동시에 해결할 수 있는 방법
- 훈련 후 모델 행동을 제어할 수 있는 빠르고 실용적인 방법
- 여러 편집 작업을 동시에 적용할 수 있는 확장성 있는 방법
Method
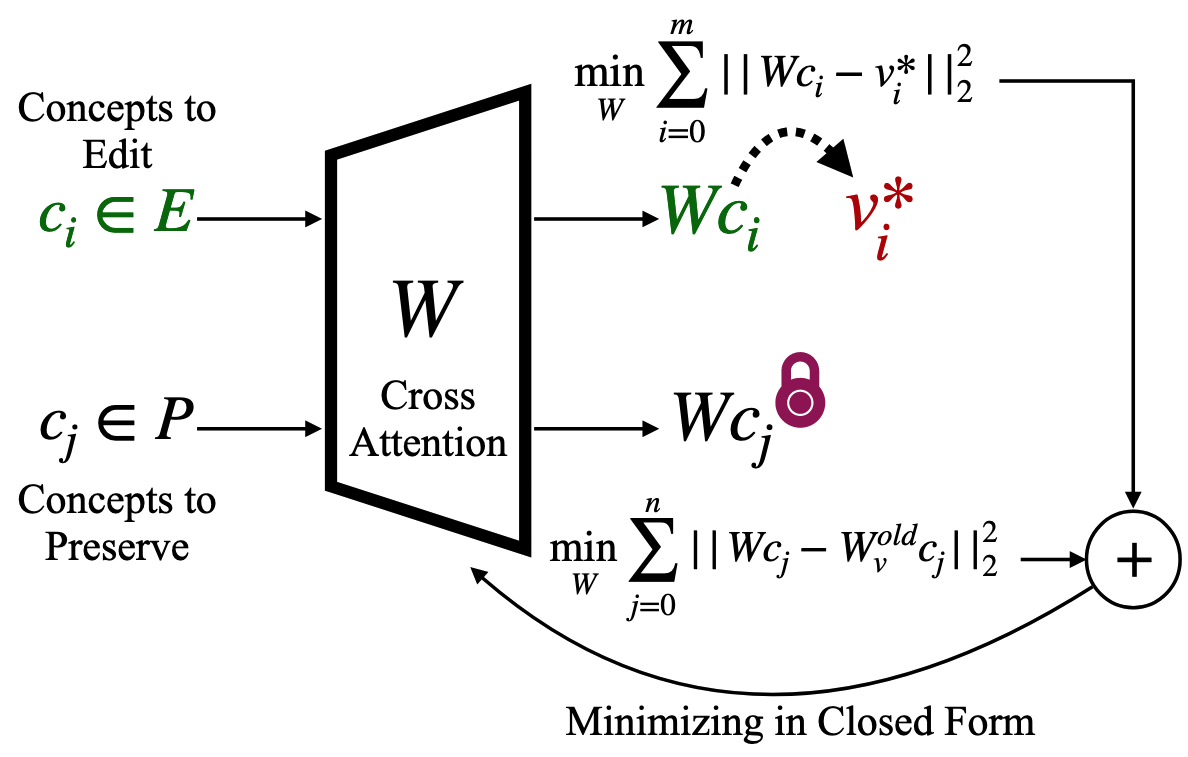
- UCE(Unified Concept Editing): 여러 개념을 통합적으로 편집하는 방법
- TIME과 MEMIT 방법을 기반으로 확장한 닫힌 형태 파라미터 편집 방법
- 텍스트-이미지 프로젝션에서 Cross-Attention 가중치 수정
- 목적 함수:
- 첫 번째 항(개념 편집): 편집 대상 개념들의 출력을 원하는 새로운 값으로 변경
- 두 번째 항(개념 보존): 보존할 개념들의 출력은 원래 모델과 동일하게 유지
- 닫힌 형태 해:
- 편집과 보존의 균형을 통해 원하는 개념만 선택적으로 수정하면서 모델의 일반적 생성 능력 유지
- 닫힌 형태이므로 학습이 필요 없음
- 개념 편집 유형
- 지우기(Erasing):
(개념 를 다른 개념 로 대체) - 편향 제거(Debiasing):
(여러 속성에 대한 균등 분포) - 편향 제거 알고리즘
- 반복적 접근법: 현재 비율 측정 → α 값 조정 → UCE 적용 → 비율 재측정
- 목표 비율에 도달한 개념은 보존 목록으로 이동, 새 개념 편집 시 보존
- 다른 개념 편향에 미치는 영향 최소화하는 점진적 편집
- 편향 제거 알고리즘
- 조절(Moderation):
(개념 를 비조건부 프롬프트 로 대체)
- 지우기(Erasing):
Method 검증
지우기(Erasing) 실험

지운 스타일의 수가 많아져도 지우려는 스타일을 잘 지움

지운 스타일의 수가 많아져도 지우지 않은 스타일을 잘 보존함 → 다른 방법들은 보존하지 못함
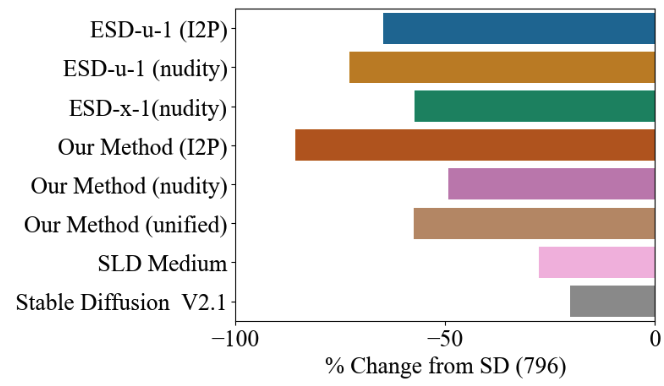
- 아티스트 스타일 지우기: Stable Diffusion 모델에서 5명의 현대 아티스트(Kelly McKernan, Thomas Kinkade 등) 스타일을 지우고, 1,000명의 다른 아티스트 보존하는 실험 구성. ESD, SDD, Ablation 방법과 비교 분석
- 5명의 아티스트
스타w일지우기 실험 → 목표 스타일 효과적 제거(사용자 연구 평균 점수 1.12/5로 가장 낮음) - LPIPS, CLIP 측정 결과 편집되지 않은 개념에 미치는 영향 최소화
- 최대 100개 아티스트 동시 지우기 가능, FID 점수 15.09로 원본 SD(14.49)와 유사
- 500개 이상 부터 일반 이미지 생성 품질 저하
- FID 점수 급격히 증가, CLIP 점수 하락
- 이미지 생성 능력 유지를 위한 임계점 존재
- 5명의 아티스트
- 객체 지우기: ImageNette 데이터셋의 10개 클래스(French Horn, Church 등)를 SD 모델에서 제거하는 실험. 각 클래스당 500개 이미지 생성 후 ResNet-50으로 분류 정확도 평가, ESD-u와 비교
- ImageNette 데이터셋 10개 클래스 지우기 → 목표 클래스 분류 정확도 78.2%에서 2.6%로 감소
- 다른 클래스 정확도는 78.2%에서 79.8%로 유지 → 목표 외 개념 보존력 우수
- ESD-u보다 목표 개념 제거(12.6%→2.6%)와 다른 개념 보존(63.2%→79.8%) 모두 우수
- 일부 복잡한 개념(church 등)은 완전히 지워지지 않고 핵심 요소만 제거
편향 제거(Debiasing) 실험

- 성별 편향 제거: 35개 직업(WinoBias 데이터셋)에 대한 성별 편향을 50-50 비율로 조정하는 실험. 각 직업별로 250개 이미지 생성 후 CLIP으로 성별 분류 측정, TIME, Concept Algebra, Debiasing-VL과 비교
- 직업 관련 성별 편향 수정 → 원하는 성별 비율(50-50)과의 편차 0.22로 최소화 (원본 SD는 0.67), Unified Model은 0.27 (약간 안좋음)
- TIME, Concept Algebra, Debiasing-VL 등 기존 방법보다 우수한 성능
- 이미지의 다른 요소는 보존하며 성별만 변경

- 인종 편향 제거: 여러 직업(의사, 상담사, 관리자 등)에 대해 백인, 흑인, 아메리카 원주민, 아시아인 등 인종 다양성을 개선하는 실험. 정성적 분석 위주로 평가
- 여러 직업에 대한 인종 다양성 증가 → 백인, 흑인, 원주민, 아시아인 등 다양한 인종 표현 개선
- 이진 속성(남/녀)을 넘어 다중 속성(여러 인종) 편향 처리 가능한 장점 보여줌
- 여러 속성에 대한 편향 제거 시 복합적인 편향 발생 가능성
- 흑인의 경우 성별 비율 균형적(48% 남성)이나, 원주민은 불균형(96% 남성)
- 한 차원의 편향 제거가 다른 차원의 편향을 악화시킬 수 있음
콘텐츠 조절(Moderation) 실험