Interpreting the Second-Order Effects of Neurons in CLIP
We interpret the function of individual neurons in CLIP by automatically describing them using text. Analyzing the direct effects (i.e. the flow from a neuron through the residual stream to the output) or the indirect effects (overall contribution) fails to capture the neurons' function in CLIP. Therefore, we present the "second-order lens", analyzing the effect flowing from a neuron through the later attention heads, directly to the output. We find that these effects are highly selective: for each neuron, the effect is significant for <2% of the images. Moreover, each effect can be approximated by a single direction in the text-image space of CLIP. We describe neurons by decomposing these directions into sparse sets of text representations. The sets reveal polysemantic behavior - each neuron corresponds to multiple, often unrelated, concepts (e.g. ships and cars). Exploiting this neuron polysemy, we mass-produce "semantic" adversarial examples by generating images with concepts spuriously correlated to the incorrect class. Additionally, we use the second-order effects for zero-shot segmentation, outperforming previous methods. Our results indicate that an automated interpretation of neurons can be used for model deception and for introducing new model capabilities.
Problem:: 뉴런의 직접적인 영향은 너무 미미하고, 하나를 꺼도 다른 뉴런이 역할을 보완해버려(Self-Repair) 기능이 가려지기 때문에 CLIP 모델 내 개별 뉴런의 진짜 역할을 파악하기 어려움
Solution:: 뉴런의 영향을 Residual Stream만 고려 (First-Order)하거나 최종 출력 (Indirect)만 고려하는게 아닌 MSA도 함께 고려하는 Second-Order Lens 제안 / 뉴런의 영향을 CLIP Image-Text Embedding으로 프로젝션해 개별 뉴런의 영향을 해석 가능하도록 함
Novelty:: 기존의 직접/간접 분석법을 넘어선 '2차 효과 렌즈'라는 새로운 뉴런 분석 프레임워크 / 하나의 뉴런은 소수의 이미지에 대해서만 반응함을 경험적으로 발견 / 뉴런의 다의성(Polysemantic)을 이용해 의미론적 적대적 공격(Semantic Adversarial Attack)을 자동 생성하는 방법론 제안 / 해석 결과를 바탕으로 기존 SOTA를 능가하는 새로운 제로샷 분할(Zero-Shot Segmentation) 제안
Note:: 이미지에 정답 클래스를 의미하는 오브젝트가 있음에도 오분류를 하는 공격 방식은 신선함 → 언어적 다의성이 이미지 분류에 혼동을 주는 방식이므로, 언어적 불분명함이 CLIP 임베딩의 약점으로 작용할수도?
Motivation
- CLIP 내 개별 Neuron의 기능을 해석하는 것은 Attention Head를 해석하는 것보다 어려움
- Neuron의 수가 Attention Head보다 훨씬 많아 자동화된 접근 방식이 필요함
- 기존 분석 방법들은 다음과 같은 명확한 한계를 가짐
- First-Order Effect (Direct Effect): Neuron의 출력이 후속 MSA Block을 거치지 않고 Residual Stream에 직접 더해지는 영향으로, 그 효과가 미미함 → Neuron이 Residual Stream에 미치는 영향
- Indirect Effect: Neuron 하나를 비활성화했을 때 최종 출력의 총체적인 변화지만, 다른 Neuron이 기능을 보완(Self-Repair) 하여 본래 기능이 가려짐 → Neuron이 출력에 미치는 영향
- 이러한 한계점을 극복하기 위해, 본 논문에서는 새로운 해석 가능성 렌즈를 제안함
- "Second-Order Lens" 라는 새로운 방법을 제안하여, 특정 Neuron의 출력이 이후의 Attention Head들을 거쳐 최종 출력에 미치는 영향 (Second-Order Effect)을 분석하고자 함
- 이는 Second-Order Lens가 다른 방법으로는 파악하기 힘든 Neuron의 핵심적인 기여도를 가장 잘 드러냄을 의미함
- Ablation 실험 결과, 이 Second-Order Effect를 제거했을 때가 Indirect Effect를 제거했을 때보다 모델의 성능 저하가 훨씬 컸음
Method

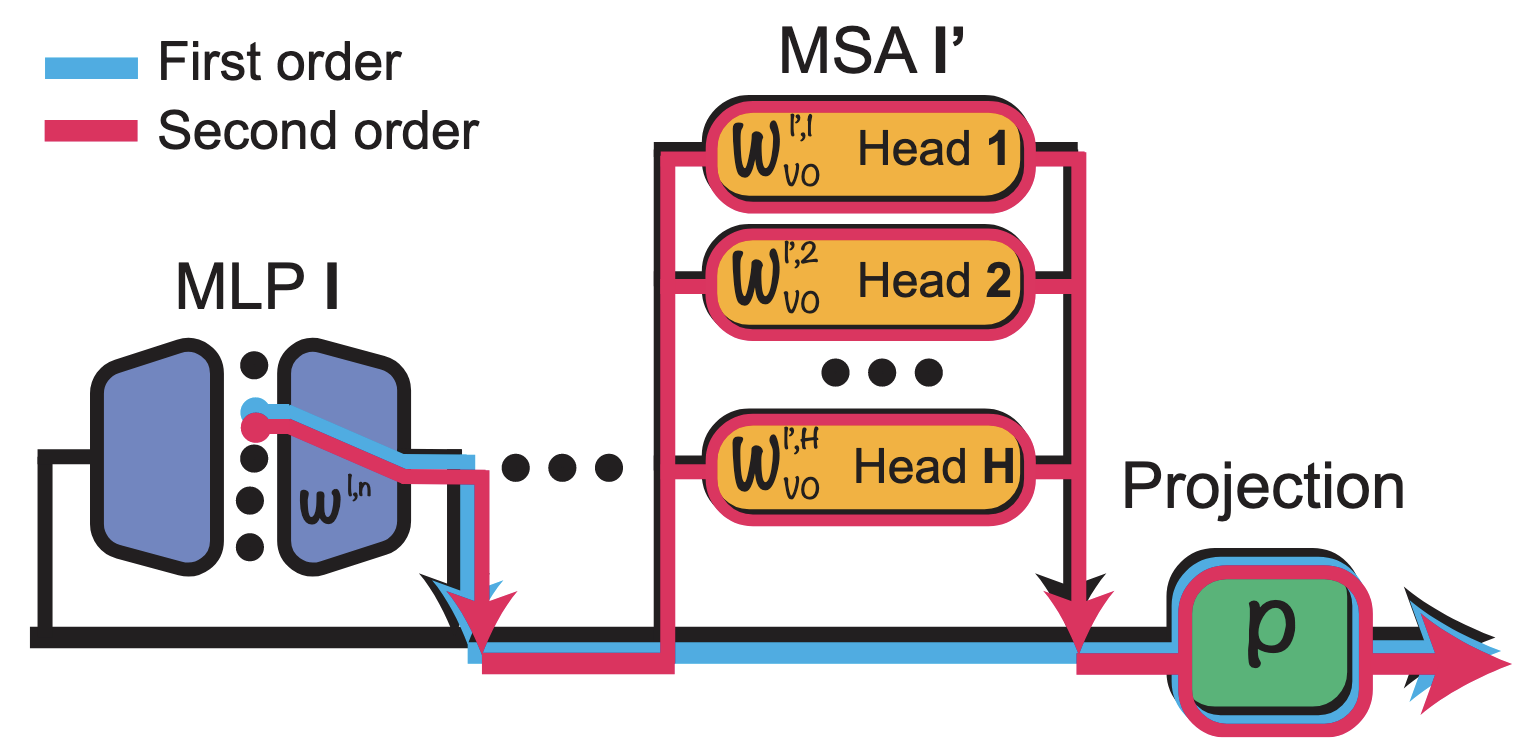
- Second-Order Effect의 정의:
-
Layer
의 Neuron 에서 나온 출력( )은 Residual Stream에 더해진 후, 그보다 뒤에 있는 Layer ( )의 Multi-Head Self-Attention (MSA) Block에 영향을 줌 -
이때 Neuron
의 출력이 모든 후속 MSA Layer들을 통과한 후 최종적으로 Class Token에 미치는 총합적인 기여도를 해당 Neuron의 Second-Order Effect 로 정의함 -
수식은 다음과 같음:
: Attention Weight : Projection Matrix (제일 마지막에 존재)
-
- Second-Order Effect의 특성 규명:
- 후기 Layer 집중성: Second-Order Effect는 모델의 후기 Layer (ViT-B-32 기준 8-10 Layer)에서 가장 큰 영향을 미침
- Sparsity: 각 Neuron의 Second-Order Effect는 소수의 이미지 (< 2%)에 대해서만 큰 영향을 미침
- 이는 Neuron이 매우 전문화된 탐지기(Specialized Detector)처럼 작동함을 의미하며, 소수의 특정 개념에만 반응하기에 오히려 그 기능을 명확히 해석하고 분석할 수 있게 해주는 핵심적인 특성임
- Rank-1 근사 가능성: 하나의 Neuron이 생성하는 Second-Order Effect
는 이미지에 따라 달라지지만, 사실상 출력 공간에서 거의 단일한 방향 벡터 (Single Direction) 로 근사될 수 있음 - 이 대표 방향 벡터
은 특정 뉴런( )이 데이터셋( )의 여러 이미지 에 대해 생성한 효과 벡터들 중, 크기(Norm)가 가장 큰 상위 벡터들의 집합( )으로부터 제1 주성분(First Principal Component)을 계산하여 구함 → 단일 뉴런이 여러 이미지에 미친 영향들 중 큰 것만 모아서 주성분 추출
- 이 대표 방향 벡터
- Text 기반 Neuron 해석 (Sparse Decomposition):
- 위에서 발견한 단일 방향 벡터
가 CLIP의 공유된 Text-Image 공간에 존재한다는 점을 활용하여, 이 벡터를 소수의 Text Embedding들의 희소 선형 결합 (Sparse Linear Combination)으로 분해함 → 텍스트 임베딩들의 선형 결합으로 표현해보자
- 이를 통해 Neuron이 Polysemantic 하다는, 즉 하나의 Neuron이 서로 관련 없는 여러 개념 (예: 배와 자동차)에 동시에 반응한다는 사실을 발견함
- 위에서 발견한 단일 방향 벡터
Method 검증
실험 1: Mean-Ablation of Second-Order Effects
- 실험 진행 방법:
- ImageNet 데이터셋에 대해 특정 Layer에 있는 모든 Neuron들의 Second-Order Effect를 데이터셋 전체의 평균값으로 대체(Mean-Ablation)한 후, Zero-Shot Classification 정확도 하락을 측정
- 정량적 성능 및 통찰:
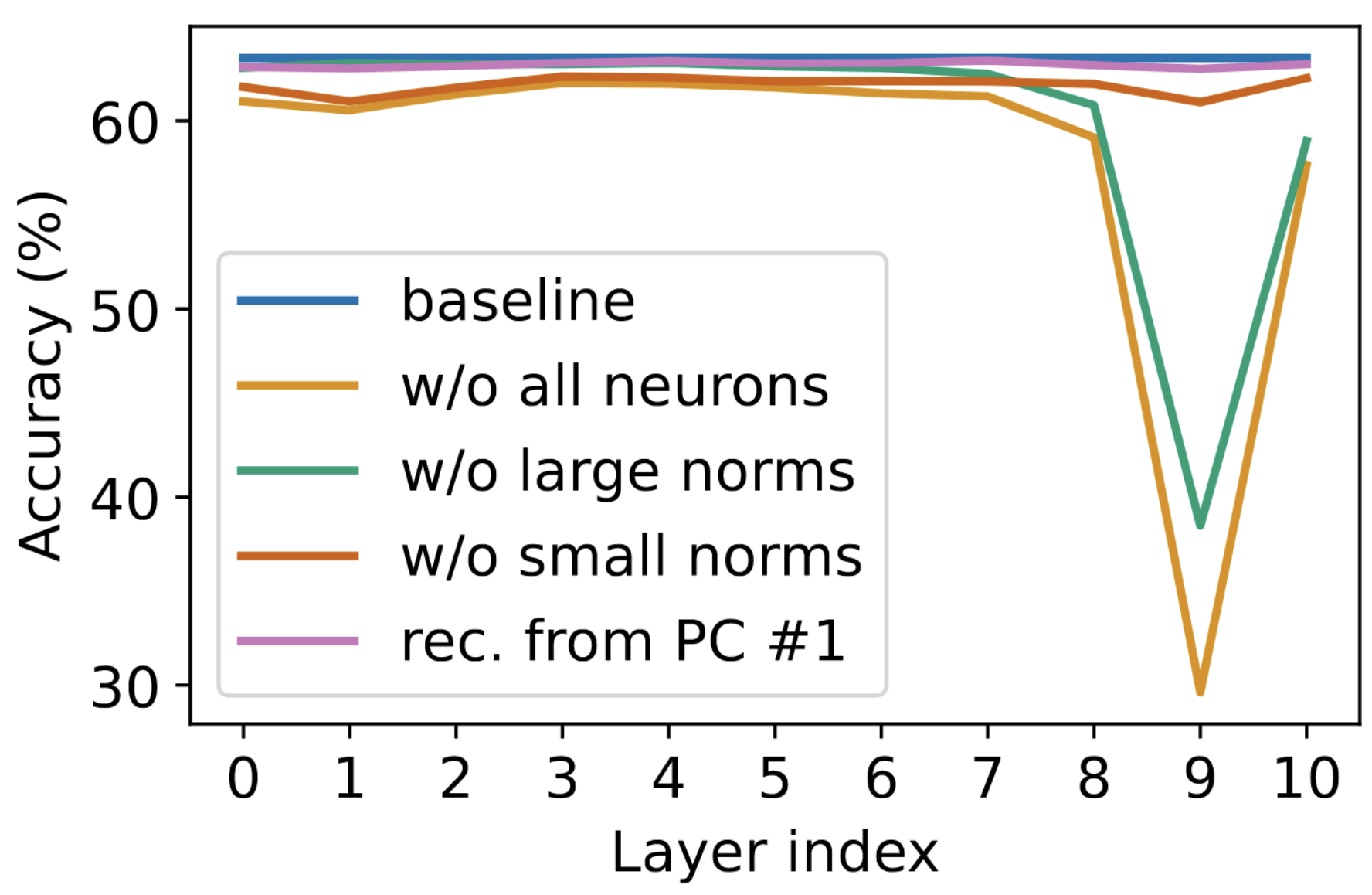
- Layer 8-10에서 정확도 하락이 가장 컸음 → Second-Order Effect는 후기 Layer에 집중되어 있음을 확인
- 큰 Norm을 가진 효과만 제거("w/o large norm")했을 때 정확도 하락이 훨씬 컸음 → 각 Neuron은 소수의 특정 이미지에 대해서만 선택적으로 강하게 반응함을 의미
- 제1 주성분으로 복원("rec. from PC #1")(
으로 교체)해도 성능이 거의 하락하지 않음 → 개별 Neuron의 효과는 사실상 하나의 방향 벡터로 표현될 수 있음을 증명
실험 2: Accuracy for Neuron Reconstructed from Sparse Text Representations
- 실험 진행 방법:
- 뉴런의 대표 방향 벡터(
)를 소수의 텍스트 임베딩 조합으로 근사( )한 뒤, 이 근사된 벡터를 사용하여 뉴런의 효과를 재구성함 - 이 재구성된 효과를 실제 모델에 적용했을 때, ImageNet 분류 정확도가 얼마나 유지되는지를 측정
- 뉴런당 사용되는 텍스트의 개수(m)와 텍스트 풀의 종류를 바꿔가며 실험을 진행함
- 뉴런의 대표 방향 벡터(
- 정량적 성능 및 통찰:
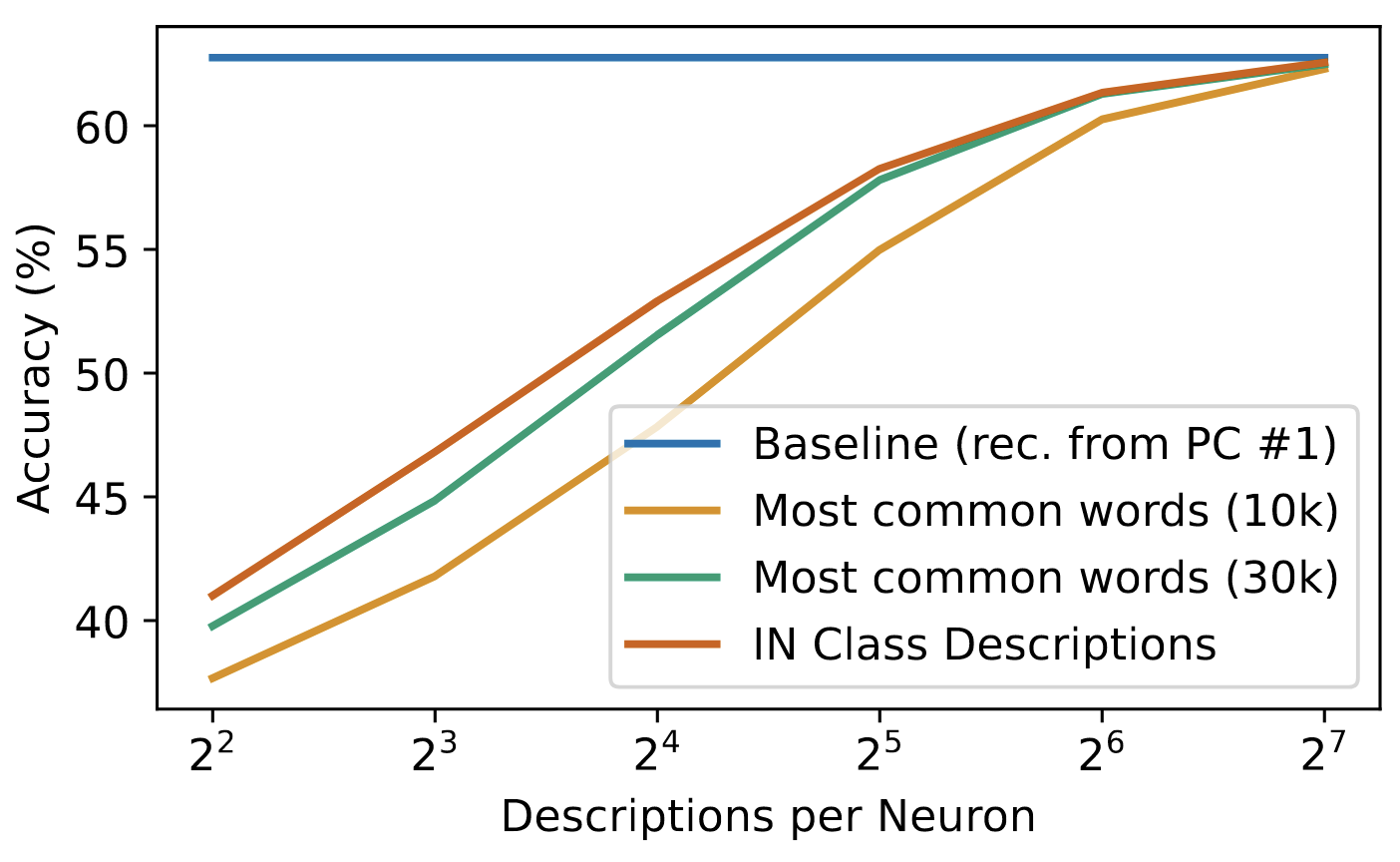
- 뉴런당 128개의 텍스트 설명을 사용했을 때, 분류 정확도가 원래 수준(Baseline)에 거의 근접하게 회복됨 → 이는 소수의 텍스트 집합으로 뉴런의 핵심 기능을 성공적으로 포착하고 재구성할 수 있음을 의미함
- 따라서, 이 방법으로 찾은 텍스트 설명이 단순한 상관관계가 아니라 뉴런의 기능과 인과적으로 연결되어 있음을 실험적으로 증명함
실험 3: Automatic Generation of Adversarial Examples

은 고양이, 는 강아지인 경우
-
실험 진행 방법:
- Neuron의 Polysemantic한 특성을 이용하여 Adversarial Example을 생성
- 두 클래스(
, )를 구분하는 '분류 방향 벡터' 를 정의 는 CLIP 임베딩 공간에서 개념에서 개념으로 향하는 방향을 의미하며, 이것과 유사한 방향벡터 을 가진 뉴런은 에서 로 가도록 하는 Second Order Effect를 가지고 있음
- 이 분류 방향에 가장 큰 영향을 미치는 뉴런들을 찾고, 해당 뉴런들의 Text Decomposition에서 오분류를 유발할 수 있는 Spurious Cue 단어들을 추출
- 분류 방향과 유사한
의 Decomposition을 구성하는 단어들은 을 로 보이도록 한다고 볼 수 있음
- 분류 방향과 유사한
- LLM을 이용해 원래 클래스 이름과 Spurious Cue 단어들을 포함하는 프롬프트를 생성한 뒤, Text-to-Image 모델로 이미지를 생성함
- 두 클래스(
- 비교군(Baseline)으로는 Random Neurons, Indirect Effects (
계산에 대신 Output Representation 사용), Similar Words ( 와 유사한 단어들로 프롬프트 생성) 등을 사용
- Neuron의 Polysemantic한 특성을 이용하여 Adversarial Example을 생성
-
정량적 성능 및 통찰:
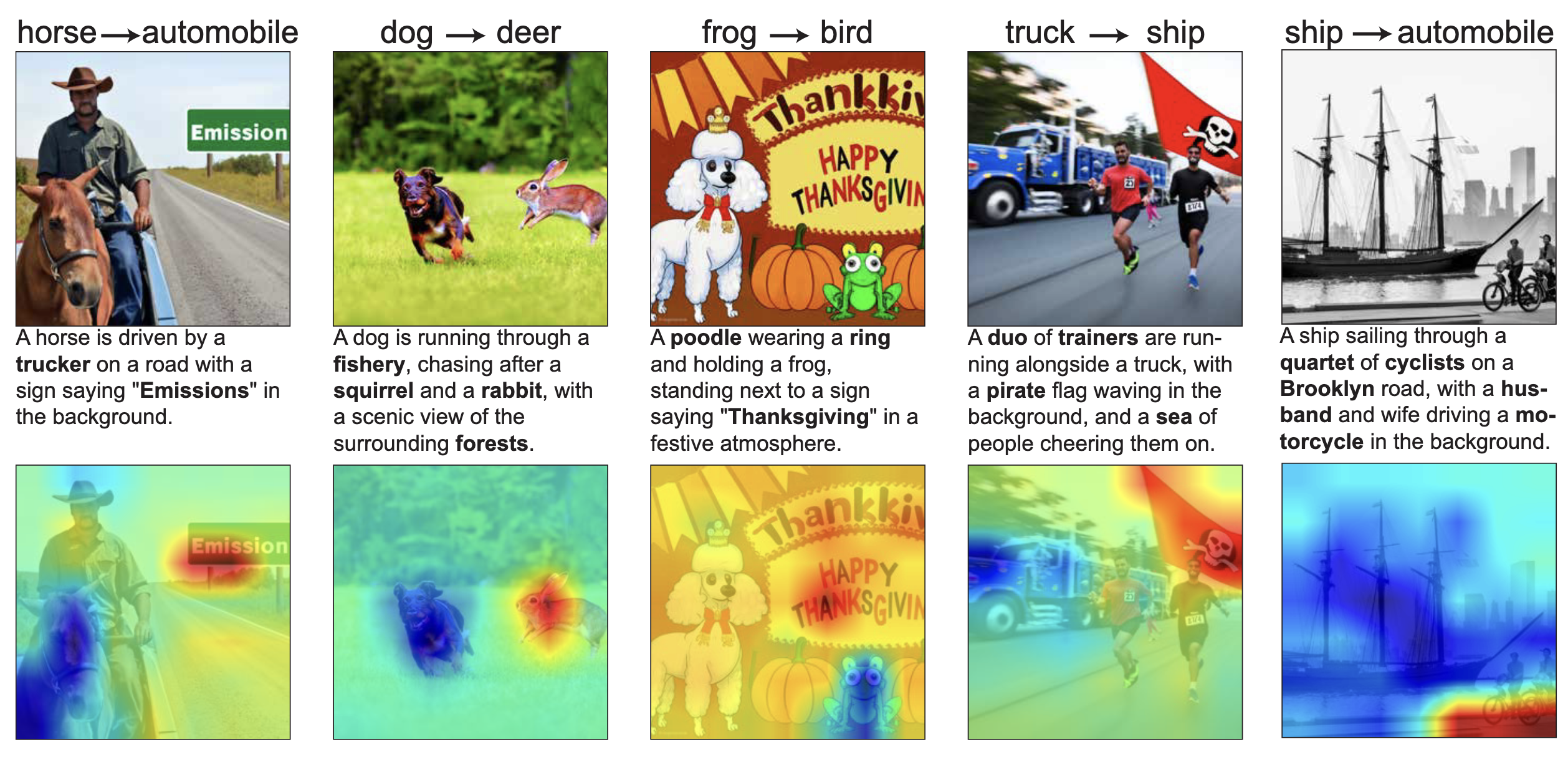
생성된 이미지와 프롬프트 예시. 볼드체는 찾아낸 오분류 유발 단어. 아래 시각화는 오분류에 기여한 부분 (빨간색)과 분류에 기여한 부분 (파란색)에 대한 시각화
ship -> automobile분류 과제에서, 제안 방법은 7.0%의 성공률로 이미지를 오분류 시킨 반면, 다른 Baseline들은 거의 성공하지 못함- Second-Order Lens로 발견한 Neuron의 기능(Text Decomposition)이 인과적으로 유의미하며, 이를 통해 모델을 속일 수 있음을 보여줌. 특히 "Similar Words"와 같은 외부 '블랙박스' 접근법보다 모델 내부 메커니즘을 직접 분석하는 제안 방법이 훨씬 효과적임을 입증
실험 4: Zero-Shot Segmentation
- 실험 진행 방법:
- 분할하려는 Class 이름의 Text Embedding과 가장 유사한 방향(
)을 가진 상위 Neuron들을 선택 - 선택된 Neuron들의 공간적 활성화 맵(
)을 평균내어 최종적인 Attribution Heatmap을 생성하고, 이를 이진화하여 Segmentation Mask를 얻음
- 분할하려는 Class 이름의 Text Embedding과 가장 유사한 방향(
- 정량적 성능 및 통찰

- ImageNet-Segmentation 데이터셋에서 mIoU 기준 59.0%를 달성하여, 이전 SOTA 방법인 TextSpan(58.1%) 등을 능가함
- 위 그림에서, 이전 방법이 객체의 특정 부분만 강조하는 반면, 제안 방법은 객체의 전체적인 모습을 더 잘 포착함
- Neuron의 Second-Order Effect를 기반으로 의미적으로 관련된 Neuron들을 종합하면, 객체의 위치를 정확하게 특정하는 새로운 능력을 이끌어낼 수 있음을 증명