An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes. In other words, we ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy? Here we present a simple approach that allows such creative freedom. Using only
Problem:: 텍스트-이미지 모델이 발전했지만 특정 고유 개념(사용자 객체, 스타일 등)을 생성하거나 수정하는 능력에 한계 존재 / 새로운 개념을 모델에 도입하기 위한 기존 방법들(재학습, 미세조정)은 비용이 많이 들거나 Catastrophic Forgetting 발생
Solution:: 사전 학습된 텍스트-이미지 모델의 임베딩 공간에서 새로운 Pseudo-Word를 찾는 Textual Inversion 방법 제안 / 사용자가 제공한 3-5장의 이미지만으로 특정 개념을 표현하는 임베딩 벡터를 최적화 / 학습된 pseudo-word를 자연어 문장에 포함시켜 직관적인 방식으로 개인화된 생성 안내
Novelty:: 단일 임베딩 벡터만으로도 다양하고 고유한 개념을 포착 가능함을 입증 / 시각적 재구성 목표를 통해 pseudo-word 학습
Note:: 복잡한 형태 보존에는 여전히 한계 존재 / 최적화 시간이 길다는 단점(단일 개념 학습에 약 1시간 소요)
Summary
Motivation
- 최근 텍스트-이미지 모델들은 자연어 설명을 통한 이미지 생성에 높은 성능을 보이지만, 특정 고유 개념을 생성하거나 변형하는 능력은 제한적
- 사용자가 소유한 고양이를 그림으로 변환하거나 좋아하는 장난감을 기반으로 새 제품을 상상하는 등의 개인화된 생성이 어려움
- 대규모 모델에 새로운 개념을 도입하는 것은 일반적으로 어려운 과제
- 각 새로운 개념마다 확장된 데이터셋으로 모델을 재훈련하는 것은 비용이 많이 들고 비현실적
- 소수의 예제로 미세 조정(Fine-tuning)하면 Catastrophic Forgetting 발생
- 모델을 고정하고 변환 모듈을 훈련하는 방법도 이전 지식 망각 또는 새로운 개념과 함께 접근하는 데 어려움 발생
Method
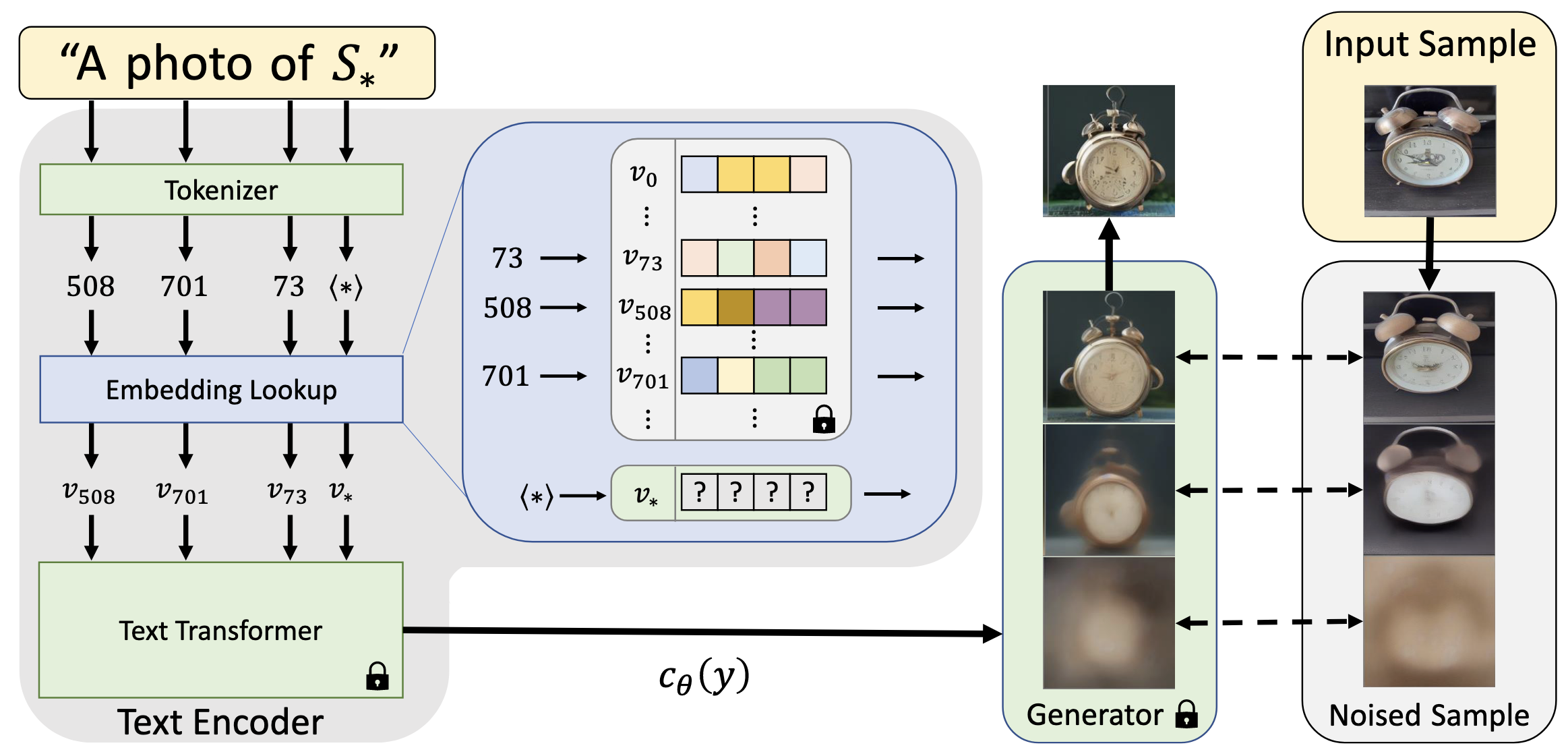
- 사전 학습된 텍스트-이미지 모델의 텍스트 임베딩 공간에서 새로운 단어를 찾는 방식으로 문제 해결
- 텍스트 인코딩 과정의 첫 단계를 활용
- 입력 문자열이 토큰으로 변환되고, 각 토큰은 해당 임베딩 벡터로 대체된 후 모델에 전달
- 목표: 새로운 특정 개념을 나타내는 임베딩 벡터 찾기
- 새로운 임베딩 벡터를 Pseudo-word "
"로 표현 - 이 Pseudo-word는 일반 단어처럼 취급되어 새로운 텍스트 쿼리 구성 가능
- "해변에 있는
의 사진", "벽에 걸린 의 유화" 등 다양한 문맥에서 사용 가능 - 두 개념 합성도 가능 ("
스타일의 그림")
- 생성 모델을 변경하지 않고 어휘를 확장하여 개념 표현
- 모델의 풍부한 텍스트 이해력과 일반화 능력을 유지
Textual Inversion 구현
- 사전 학습된 텍스트-이미지 모델과 개념을 묘사하는 소수(3-5장) 이미지 세트가 주어졌을 때, "
의 사진"과 같은 프롬프트가 이미지 세트에서 이미지를 재구성하도록 하는 단어 임베딩을 찾는 것 - Latent Diffusion Models(LDMs)를 기반으로 구현
- 오토인코더의 잠재 공간에서 작동하는 Denoising Diffusion Probabilistic Models
- 텍스트 인코더 BERT를 통해 조건부 입력 처리
- 최적화 목표: 훈련 세트에서 샘플링된 이미지에 대해 LDM 손실 최소화
- 원본 LDM 모델의 훈련 방식 재사용, 단
와 는 고정
- CLIP ImageNet 템플릿에서 파생된 중립적 컨텍스트 텍스트로 생성 조건화
Method 검증
실험에 사용된 비교 방법들
- DALLE-2 (Ramesh et al., 2022)
- 이미지 입력 방식: DDIM 샘플링 과정의 폐쇄형 역변환을 통해 실제 이미지를 잠재 노이즈 맵으로 역변환
- 긴 캡션 입력 방식: 세부적인 텍스트 설명(30단어 이상)을 사용하여 이미지 생성
- 더 매력적인 샘플을 생성하지만 고유한 디테일 포착에 한계 → 세부 디테일에 충실한 생성이 어려움
- PALAVRA (Cohen et al., 2022)
- CLIP의 텍스트 임베딩 공간에서 대조 학습과 순환 일관성 목표를 사용하여 객체 인코딩
- 개인화된 검색 및 분할 작업을 위해 설계된 판별적(discriminative) 접근법
- 생성 품질에 필요한 세부 정보를 포착하지 못하고 자연 이미지 매니폴드에 매핑되는 제약이 없음
- VQGAN+CLIP과 CLIP-Guided Diffusion을 통해 생성 과정에 활용 시도
- CLIP 기반 최적화 모델
- VQGAN+CLIP (Crowson et al., 2022): VQGAN을 CLIP 유사도 점수로 최적화하여 이미지 생성
- CLIP-Guided Diffusion (Crowson, 2021): 디퓨전 프로세스를 CLIP으로 안내하여 생성
- 훈련 이미지와 타겟 텍스트 간의 CLIP 기반 거리를 동시에 최소화하는 방식으로 응용
- 훈련 세트 이미지로 최적화 초기화하는 방법 사용 (Letts et al., 2021)
- 테스트 시간에 매 생성마다 비용이 많이 드는 최적화 과정 필요 → 효율성 문제
실험 결과

- Pseudo-word 이미지 생성
- 단일 Pseudo-word로 객체 표현 능력 평가
- 인간 캡션과 DALLE-2(이미지 또는 캡션 기반) 방식과 비교
- 인간 캡션: 높은 수준의 의미는 포착하지만 색상 패턴과 같은 세부 사항 누락
- DALLE-2: 더 매력적인 샘플 생성하지만 고유한 세부 사항 포착 어려움
- 제안 방법: 더 세밀한 디테일 포착 → 원본 개념에 더 충실한 변형 생성
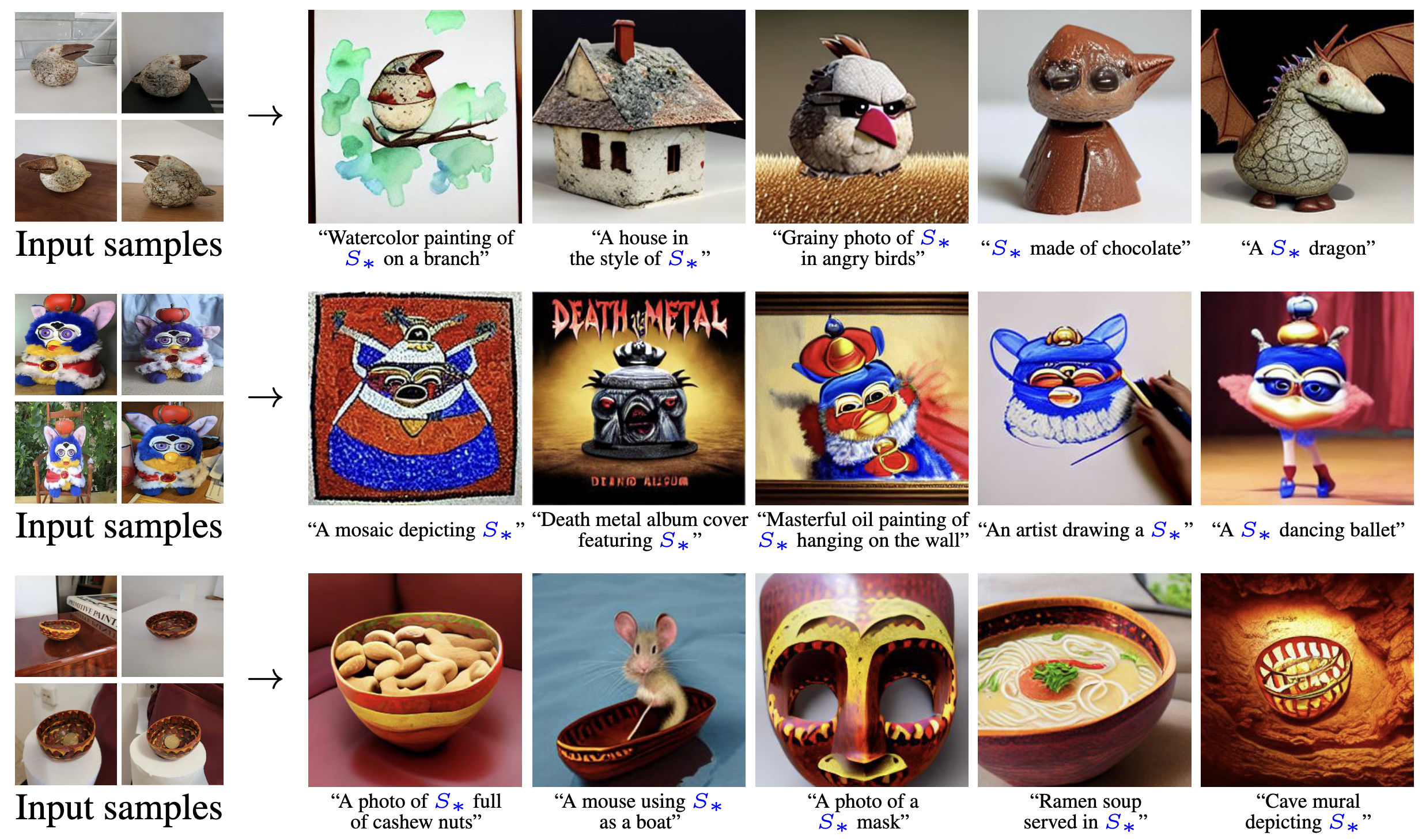
- 학습된 Pseudo-word를 새로운 문맥에 포함시켜 새로운 장면 합성
- 모델이 새 개념과 기존 지식을 결합하여 창의적 이미지 생성
- 시각적 학습 목표에도 불구하고 의미적 지식도 포착함을 확인
- 예: 그릇이 다른 물체를 담을 수 있다는 특성 이해

- 예: 그릇이 다른 물체를 담을 수 있다는 특성 이해
- 스타일 전이 능력
- 특정 예술 스타일을 Pseudo-word로 표현하고 다양한 주제에 적용
- 제안 방법이 객체 재구성을 넘어 추상적인 스타일까지 포착 가능함을 입증

- 개인화 기법 비교
- PALAVRA와 CLIP 기반 모델들과 비교
- PALAVRA: 타겟 프롬프트 요소(해변, 달)는 포함하지만 개념 포착 실패 및 시각적 왜곡 발생
- VQGAN+CLIP, Guided Diffusion: 더 자연스러운 결과 생성하지만 새 텍스트로 일반화 어려움
- 제안 방법: 개념을 더 정확히 보존하고 pseudo-word와 나머지 캡션 요소 간 상호작용 처리 가능
- PALAVRA와 CLIP 기반 모델들과 비교
정량적 평가
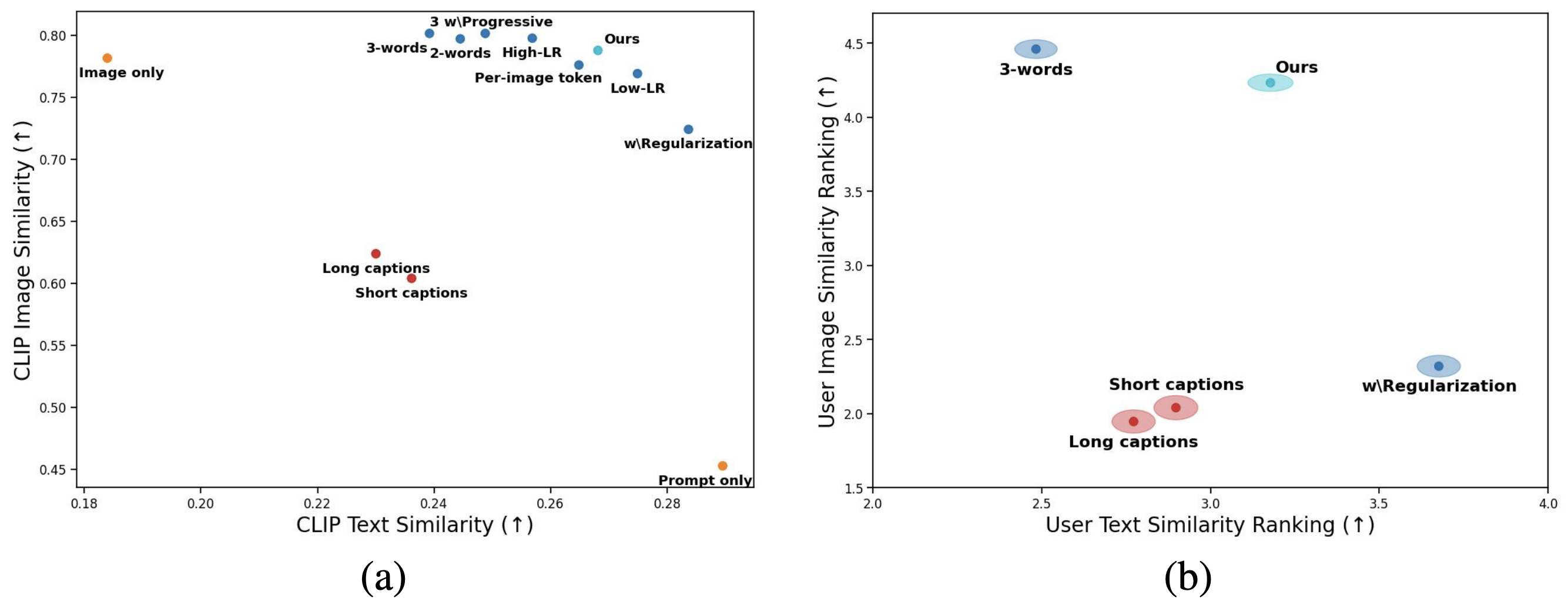
- 다양한 실험 셋업에 대한 체계적 평가:
- 확장된 잠재 공간(2-word, 3-word): 여러 임베딩 벡터로 잠재적 병목 현상 완화 시도 → 재구성 향상되나 프롬프트 준수 악화
- Progressive: 2,000 훈련 스텝 후 두 번째 벡터, 4,000 스텝 후 세 번째 벡터 도입하는 방식 → 초기에 핵심 특징에 집중하고 추가 벡터로 세부 디테일 포착하는 계층적 학습 유도
- Regularization: 학습된 임베딩을 개념의 대략적 설명자(예: "sculpture", "cat")에 가까이 유지 → 프롬프트 준수는 향상되나 세부 디테일 포착 능력 감소
- Per-Image Token: 공유 개념 토큰(
)과 각 이미지별 고유 토큰( )을 함께 사용 → 공유 정보는 에, 이미지별 세부 사항은 에 인코딩되도록 유도 - 참조 셋업: 개념 완벽 복제("Image only"), 프롬프트만 준수("Prompt only") → 성능 상한과 하한 제공
- 학습률 변화: 높은 학습률(2e-2)은 재구성 향상/프롬프트 준수 감소, 낮은 학습률(1e-4)은 반대 효과 → 단순 학습률 조정으로 성능 특성 조절 가능
- 결과:
- 단일 단어 방법이 다중 단어 방법보다 재구성 비용 최소화하며 프롬프트 준수 성능 크게 향상
- 재구성-프롬프트 준수 간 트레이드오프 곡선 발견 → 학습률 조정으로 이 곡선을 따라 모델 이동 가능
- 인간 캡션은 개념 유사성 포착에 실패하고 프롬프트 준수도 감소
- 사용자 평가 결과:
- 두 가지 설문 조사 진행:
- 개념 훈련 세트와 각 모델이 생성한 결과 간 유사성 평가
- 텍스트 설명과 각 모델이 생성한 이미지 간 유사성 평가
- 결과:
- CLIP 기반 메트릭과 유사한 패턴 보임
- 동일한 재구성-프롬프트 준수 트레이드오프 확인
- 인간 캡션 기반 생성의 제한점 확인
- 두 가지 설문 조사 진행: