Detecting Adversarial Samples Using Influence Functions and Nearest Neighbors
Deep neural networks (DNNs) are notorious for their vulnerability to adversarial attacks, which are small perturbations added to their input images to mislead their prediction. Detection of adversarial examples is, therefore, a fundamental requirement for robust classification frameworks. In this work, we present a method for detecting such adversarial attacks, which is suitable for any pre-trained neural network classifier. We use influence functions to measure the impact of every training sample on the validation set data. From the influence scores, we find the most supportive training samples for any given validation example. A k-nearest neighbor (k-NN) model fitted on the DNN’s activation layers is employed to search for the ranking of these supporting training samples. We observe that these samples are highly correlated with the nearest neighbors of the normal inputs, while this correlation is much weaker for adversarial inputs. We train an adversarial detector using the k-NN ranks and distances and show that it successfully distinguishes adversarial examples, getting state-of-the-art results on six attack methods with three datasets. Code is available at https://github.com/giladcohen/NNIF_adv_defense.
Problem:: 딥 Neural Networks(DNN)가 Adversarial Attack에 취약하여 탐지 기법이 필요하나, 기존 방법들은 한계가 있음
Solution:: Influence Functions와 k-NN을 결합한 NNIF 알고리즘 제안, 정상 입력과 적대적 입력 간의 상관관계 차이를 이용
Novelty:: 훈련 데이터가 네트워크 결정에 미치는 영향을 측정하는 두 가지 방법(Influence Functions와 k-NN)의 상관관계를 활용한 적대적 예제 탐지 기법
Note:: 자신들이 제안한 방어 기법을 알고 공격하는 경우에도 성능 평가를 진행하고 강건성을 보임
Summary
Motivation
- 딥 Neural Networks(DNN)는 컴퓨터 비전, 자연어 처리, 음성 인식 등 다양한 분야에서 SOTA 성능을 보이지만 Adversarial Attack에 취약함
- Adversarial Examples는 인간에게는 감지할 수 없는 작은 변화를 입력에 가하여 모델이 오류를 범하게 만듦
- Adversarial Defense 방법은 크게 1) Proactive Defense: DNN의 강건성 향상과 2) Reactive Detection: 적대적 예제 탐지로 구분
- 본 연구는 Reactive Detection에 초점을 맞추며, 모든 사전 훈련된 Neural Network에 적용 가능한 방법 제안
- 네트워크 결정과 훈련 데이터 사이의 관계가 깨지면 적대적 입력일 가능성이 높다는 핵심 아이디어를 활용
Figure 1 설명
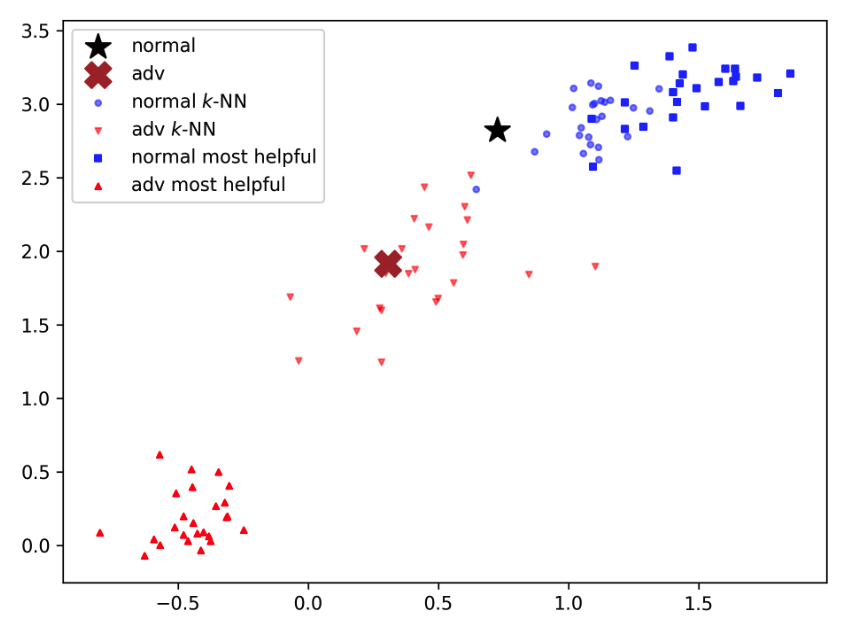
- 정상 이미지(검은 별표)와 적대적 이미지(갈색 X)의 임베딩 공간을 PCA로 시각화
- 각 이미지에 대해 영향 함수로 계산한 가장 도움이 되는 훈련 샘플 25개(Most Helpful)와 임베딩 공간에서 가장 가까운 25개 훈련 샘플(k-NN)을 표시
- 정상 이미지의 경우 Most Helpful 샘플(파란색 사각형)과 k-NN 샘플(파란색 원)이 임베딩 공간에서 높은 상관관계를 보임
- 반면 적대적 이미지의 경우 Most Helpful 샘플(빨간색 위쪽 삼각형)과 k-NN 샘플(빨간색 아래쪽 삼각형)이 서로 멀리 떨어져 있음
- 이러한 상관관계 차이를 이용해 적대적 예제를 탐지하는 것이 NNIF 방법의 핵심
Method
- 논문에서는 두 가지 "측정 방법"을 사용하여 훈련 데이터가 네트워크 결정에 미치는 영향 확인
- Influence Functions: 훈련 샘플이 테스트 샘플 분류에 얼마나 영향을 미치는지 측정
- 수식:
- 직관적 의미: 훈련 샘플
의 가중치를 약간 증가시킬 때 테스트 샘플 의 손실 함수 변화를 측정, 음수 값은 해당 훈련 샘플이 테스트 샘플 분류에 도움이 됨을 의미 - 활용 방식: 각 테스트 샘플에 대해 전체 훈련 셋에서 영향력 점수를 계산하여 가장 도움이 되는(helpful) 샘플과 가장 해로운(harmful) 샘플을 식별
- k-Nearest Neighbor(k-NN): 네트워크의 Embedding Space에서 적용되어 훈련 샘플과의 거리 측정
- 두 측정 방법을 결합하여 NNIF(Nearest Neighbor Influence Functions) 알고리즘 제안
- 정상 입력의 경우, Embedding Space에서 k-NN으로 찾은 이웃들과 Influence Function으로 찾은 가장 도움이 되는 훈련 샘플 간에 높은 상관관계 존재
- 적대적 입력의 경우, 이 상관관계가 약해져 Adversarial Attack 탐지 가능
- NNIF 알고리즘: 각 테스트 샘플에 대해 가장 영향력 있는 훈련 샘플들을 찾고, 이들의 k-NN 순위(R)와 거리(D)를 추출하여 Logistic Regression 모델 학습
NNIF 알고리즘 진행 프로세스
- 훈련 세트, 검증 세트, DNN 모델을 입력으로 받음
- 검증 세트에 대해 Adversarial Attack을 적용하여 적대적 검증 세트 생성
- 각 DNN 활성화 레이어에 대해 k-NN 모델 구축 (k는 전체 훈련 샘플 수와 동일)
- 정상 이미지와 적대적 이미지에 대해 다음 과정 수행:
- Influence Function을 사용하여 가장 도움이 되는(helpful) M개와 가장 해로운(harmful) M개의 훈련 샘플 인덱스 식별
- 위에서 식별된 훈련 샘플들의 k-NN 순위(R)와 L2 거리(D) 추출
- 각각 R↑, D↑(helpful 관련)와 R↓, D↓(harmful 관련) 특성 벡터로 저장
- 정상 이미지의 특성 벡터는 negative class(0), 적대적 이미지의 특성 벡터는 positive class(1)로 라벨링
- 이 특성-라벨 쌍으로 Logistic Regression 분류기 학습
- 테스트 시에는 새로운 이미지에 대해 특성 벡터를 추출하고 학습된 분류기로 적대적 여부 판단
Method 검증
- CIFAR-10, CIFAR-100, SVHN 데이터셋에서 6가지 공격 방법(FGSM, JSMA, Deepfool, CW, PGD, EAD) 평가
- NNIF는 대부분의 공격 탐지에서 기존 SOTA 방법들(DkNN, LID, Mahalanobis)보다 우수한 성능 달성
- Deepfool, CW, PGD 공격에서 모든 데이터셋에 대해 다른 탐지기보다 우수한 성능 보임
- CIFAR-10 데이터셋의 Deepfool 공격에서 99.32% AUC 달성 → 기존 방법 대비 우수한 성능 입증
- 특성 중요도 분석 결과,
(가장 도움이 되는 훈련 샘플들과의 L2 거리)가 가장 중요한 특성으로 나타남 - 전체 특성을 사용할 때와 비슷한 성능 (99.79% AUC) → 단순화된 탐지 방법 가능성 제시
- 새로운 공격으로의 일반화 능력 평가에서도 NNIF는 JSMA를 제외한 모든 미확인 공격에 최고의 일반화 능력 보임
White-Box 공격에 대한 강건성
- 논문은 NNIF 방법의 강건성을 평가하기 위해 White-Box 공격 시나리오를 검증함
- White-Box 설정: 공격자가 모델 파라미터와 방어 메커니즘을 알고 있으나 탐지기의 파라미터는 모르는 상황
- 수정된 CW 공격(CW-Opt) 제안:
- 여기서
는 적대적 이미지와 원본 이미지의 "가장 도움이 되는" 훈련 샘플들 간의 거리 합을 의미
- 여기서
- 이 공격은 적대적 이미지가 원본 이미지의 가장 도움이 되는 훈련 샘플들과 가깝게 유지되도록 유도함
- CIFAR-10 테스트 세트의 4000개 샘플에 적용한 결과, NNIF 탐지 정확도가 CW의 91.95%에서 CW-Opt의 90.81%로 약 1%만 감소
- 이 공격은 임베딩 공간의 거리에 의존하는 다른 탐지기(DkNN, LID)의 성능도 저하시켰으나, Mahalanobis 탐지기는 오히려 성능이 향상됨(90.70%→92.29%)
- Mahalanobis 방법은 클래스별 글로벌 가우시안 분포를 사용하기 때문에 이러한 역효과가 발생
- 결과적으로 NNIF는 White-Box 공격에도 1% 정도의 미미한 성능 저하만 보여 강건한 방어 메커니즘임을 입증