Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Detection transformer (DETR) relies on one-to-one assignment, assigning one ground-truth object to one prediction, for end-to-end detection without NMS post-processing. It is known that one-to-many assignment, assigning one ground-truth object to multiple predictions, succeeds in detection methods such as Faster R-CNN and FCOS. While the naive one-to-many assignment does not work for DETR, and it remains challenging to apply one-to-many assignment for DETR training. In this paper, we introduce Group DETR, a simple yet efficient DETR training approach that introduces a group-wise way for one-to-many assignment. This approach involves using multiple groups of object queries, conducting one-to-one assignment within each group, and performing decoder self-attention separately. It resembles data augmentation with automatically-learned object query augmentation. It is also equivalent to simultaneously training parameter-sharing networks of the same architecture, introducing more supervision and thus improving DETR training. The inference process is the same as DETR trained normally and only needs one group of queries without any architecture modification. Group DETR is versatile and is applicable to various DETR variants. The experiments show that Group DETR significantly speeds up the training convergence and improves the performance of various DETR-based models. Code will be available at \url{https://github.com/Atten4Vis/GroupDETR}.
Problem:: DETR 모델들의 느린 학습 수렴 속도/One-To-Many 방식은 DETR에 적용시키기 어려움
Solution:: Group-wise One-To-Many Assignment 방식의 Group DETR 제안
Novelty:: 분리된 Self-Attention과 Parameter-Sharing Decoder 학습
Note:: 쉽고 단순한 아이디어, 다양한 방법에 손 쉽게 적용 가능. Parameter-Shared Decoder 방식이 처음 도입되었는지는 확인 필요
Summary
Motivation
- DETR(Detection Transformer)은 NMS와 같은 후처리 없이 End-To-End 객체 탐지를 가능하게 했으나 학습 수렴 속도가 느림
- DETR은 One-To-One Assignment 방식을 사용하여 각 Ground-Truth 객체를 하나의 예측에만 할당
- 반면 Faster R-CNN, FCOS 같은 전통적인 객체 탐지 방법들은 One-To-Many Assignment(한 Ground-Truth 객체를 여러 예측에 할당)를 사용하여 더 빠르게 수렴
- 하지만 DETR에 단순히 One-To-Many Assignment를 적용하면 효과가 없으며, DETR에 적합한 One-To-Many Assignment 방식이 필요
Method
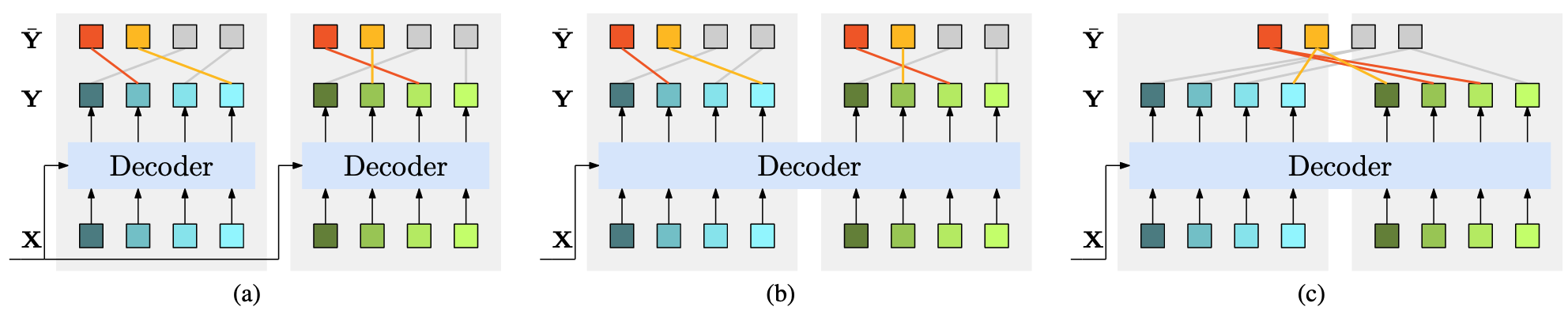
(a): Group DETR, (b) Group One-to-Many, (c) Naive One-to-Many
- Group DETR: 그룹 단위 One-To-Many Assignment 방식 제안
- K개 그룹의 Object Query 사용(각 그룹당 N개 Query, 기존 DETR과 동일)
- 각 그룹 내에서는 One-to-One Assignment 수행
- 그룹 간에는 Decoder Self-Attention을 별도로 수행하여 다른 그룹의 예측이 서로 영향을 주지 않도록 함
- 학습 구조:
- K개의 병렬 Decoder를 가진 구조와 동등(Parameter 공유)
- 각 그룹의 Query는 서로 다른 초기화를 가지므로 다양한 예측 생성
- 학습 중 손실 함수는 K개 그룹 손실의 평균값
- 추론 과정:
- 기존 DETR과 동일하게 하나의 Query 그룹만 사용
- 아키텍처 수정 없이 일반 DETR과 같은 추론 속도
Why it is Effective?
- Parameter-shared Model 관점:
- K개의 DETR 모델을 동시에 학습하는 효과
- 각 파라미터가 K배 더 많은 그래디언트를 받아 더 효과적으로 학습됨
- Query Augmentation 관점:

- 여러 그룹의 Query는 자동으로 학습되는 데이터 증강과 유사
- 더 많은 지도 신호(Supervision)를 제공하여 Decoder 학습 향상
- 동일 객체를 예측하는 서로 다른 그룹의 Query들은 공간적으로 가까운 경향을 보임
- Assignment 안정성
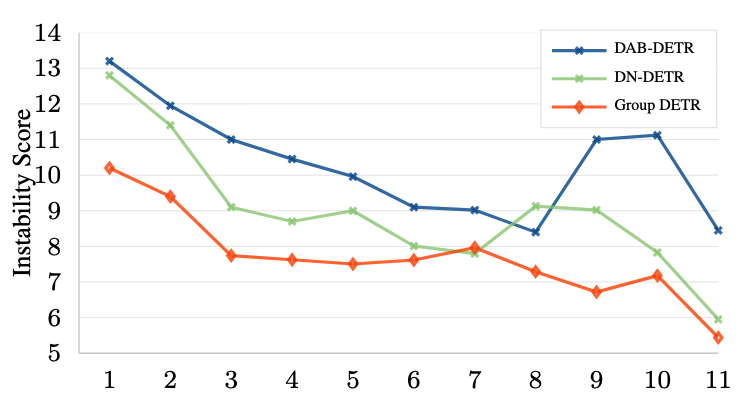
- Group DETR은 학습 중 Assignment 과정을 더 안정적으로 만듦
- 더 나은 네트워크가 더 신뢰할 수 있는 예측을 생성하고, 이는 다시 Assignment 품질을 향상시키는 선순환 효과
Method 검증
- 기본 모델에서 더 큰 향상: 단순한 DETR 모델에서 성능 향상이 더 두드러짐 → Group DETR은 복잡한 최적화 기법이 적용되지 않은 기본 모델의 학습 효율성을 크게 개선
- 장기 학습에서의 효과 지속: 50 epochs 학습에서도 일관된 성능 향상 유지 → 단순한 초기 수렴 가속화가 아닌 모델 표현력 자체의 근본적 개선 효과
- 다양한 작업에서의 성공: 2D/3D 탐지, 인스턴스 분할 등 여러 작업에서 효과적 → bipartite matching 기반 시각 작업의 일반적인 학습 패러다임 개선
- 핵심 컴포넌트의 상호 시너지: 그룹별 assignment와 분리된 self-attention 모두 중요 → 그룹 내 경쟁과 그룹 간 독립성의 균형이 성능 향상의 핵심
- 기존 방법과의 상호보완성: DN-DETR과 결합 시 추가 성능 향상 → 서로 다른 메커니즘으로 작동하는 DETR 최적화 방법들의 조합 가능성 시사
DN-DETR과의 차이점
- 쿼리 생성 방식: DN-DETR은 Ground-Truth 객체에 노이즈를 추가한 쿼리를 생성하는 반면, Group DETR은 다수의 쿼리 그룹을 자동으로 학습
- 목적과 접근법: DN-DETR은 One-to-One Assignment의 안정화에 초점을 맞추지만, Group DETR은 One-to-Many Assignment를 효과적으로 구현하는 데 중점
- 쿼리 다양성: DN-DETR의 추가 쿼리 수는 Ground-Truth 객체 수에 비례하고 각 쿼리는 특정 객체에 대응하지만, Group DETR은 고정된 N개의 쿼리(객체 및 배경 포함)를 각 그룹마다 사용
- Self-Attention 동작: DN-DETR은 노이즈가 있는 쿼리에 Self-Attention을 수행하여 주로 다른 객체의 정보를 수집하는 반면, Group DETR의 그룹별 Self-Attention은 중복 예측과 다른 객체 예측 모두의 정보를 활용
- 성능 향상 메커니즘: DN-DETR은 주로 박스 및 분류 예측 개선에 도움을 주지만, Group DETR은 중복 예측 제거에도 직접적인 도움을 줌